 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavReward: Spoken Dialogue Models With Generalist Reward Evaluators
May 14, 2025End-to-end spoken dialogue models such as GPT-4o-audio have recently garnered significant attention in the speech domain. However, the evaluation of spoken dialogue models' conversational performance has largely been overlooked. This is primarily due to the intelligent chatbots convey a wealth of non-textual information which cannot be easily measured using text-based language models like ChatGPT. To address this gap, we propose WavReward, a reward feedback model based on audio language models that can evaluate both the IQ and EQ of spoken dialogue systems with speech input. Specifically, 1) based on audio language models, WavReward incorporates the deep reasoning process and the nonlinear reward mechanism for post-training. By utilizing multi-sample feedback via the reinforcement learning algorithm, we construct a specialized evaluator tailored to spoken dialogue models. 2) We introduce ChatReward-30K, a preference dataset used to train WavReward. ChatReward-30K includes both comprehension and generation aspects of spoken dialogue models. These scenarios span various tasks, such as text-based chats, nine acoustic attributes of instruction chats, and implicit chats. WavReward outperforms previous state-of-the-art evaluation models across multiple spoken dialogue scenarios, achieving a substantial improvement about Qwen2.5-Omni in objective accuracy from 55.1$\%$ to 91.5$\%$. In subjective A/B testing, WavReward also leads by a margin of 83$\%$. Comprehensive ablation studies confirm the necessity of each component of WavReward. All data and code will be publicly at https://github.com/jishengpeng/WavReward after the paper is accepted.
WavRAG: Audio-Integrated Retrieval Augmented Generation for Spoken Dialogue Models
Feb 20, 2025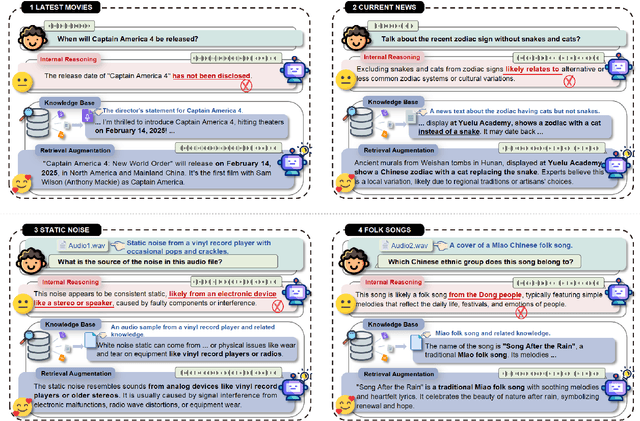
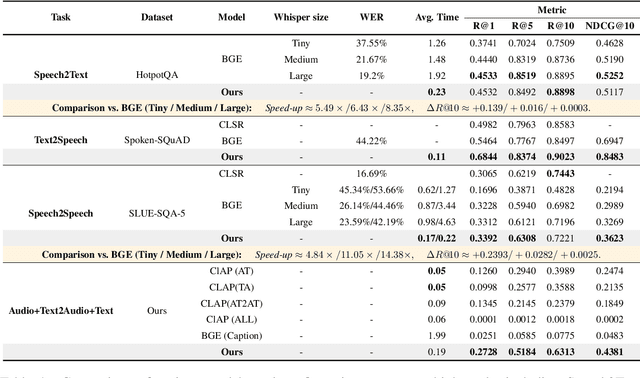
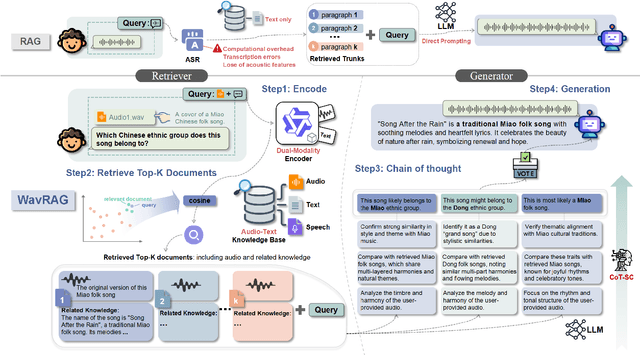
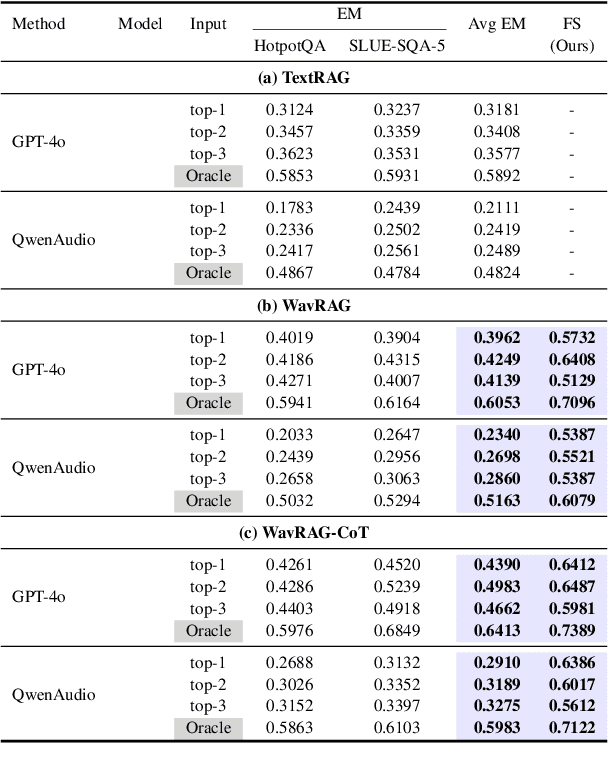
Retrieval Augmented Generation (RAG) has gained widespread adoption owing to its capacity to empower large language models (LLMs) to integrate external knowledge. However, existing RAG frameworks are primarily designed for text-based LLMs and rely on Automatic Speech Recognition to process speech input, which discards crucial audio information, risks transcription errors, and increases computational overhead. Therefore, we introduce WavRAG, the first retrieval augmented generation framework with native, end-to-end audio support. WavRAG offers two key features: 1) Bypassing ASR, WavRAG directly processes raw audio for both embedding and retrieval. 2) WavRAG integrates audio and text into a unified knowledge representation. Specifically, we propose the WavRetriever to facilitate the retrieval from a text-audio hybrid knowledge base, and further enhance the in-context capabilities of spoken dialogue models through the integration of chain-of-thought reasoning. In comparison to state-of-the-art ASR-Text RAG pipelines, WavRAG achieves comparable retrieval performance while delivering a 10x acceleration. Furthermore, WavRAG's unique text-audio hybrid retrieval capability extends the boundaries of RAG to the audio modality.
Speech Watermarking with Discrete Intermediate Representations
Dec 18, 2024Speech watermarking techniques can proactively mitigate the potential harmful consequences of instant voice cloning techniques. These techniques involve the insertion of signals into speech that are imperceptible to humans but can be detected by algorithms. Previous approaches typically embed watermark messages into continuous space. However, intuitively, embedding watermark information into robust discrete latent space can significantly improve the robustness of watermarking systems. In this paper, we propose DiscreteWM, a novel speech watermarking framework that injects watermarks into the discrete intermediate representations of speech. Specifically, we map speech into discrete latent space with a vector-quantized autoencoder and inject watermarks by changing the modular arithmetic relation of discrete IDs. To ensure the imperceptibility of watermarks, we also propose a manipulator model to select the candidate tokens for watermark embedding. Experimental results demonstrate that our framework achieves state-of-the-art performance in robustness and imperceptibility, simultaneously. Moreover, our flexible frame-wise approach can serve as an efficient solution for both voice cloning detection and information hiding. Additionally, DiscreteWM can encode 1 to 150 bits of watermark information within a 1-second speech clip, indicating its encoding capacity. Audio samples are available at https://DiscreteWM.github.io/discrete_wm.
WavChat: A Survey of Spoken Dialogue Models
Nov 26, 2024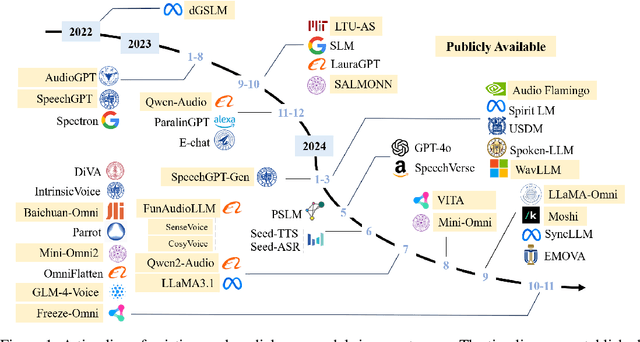

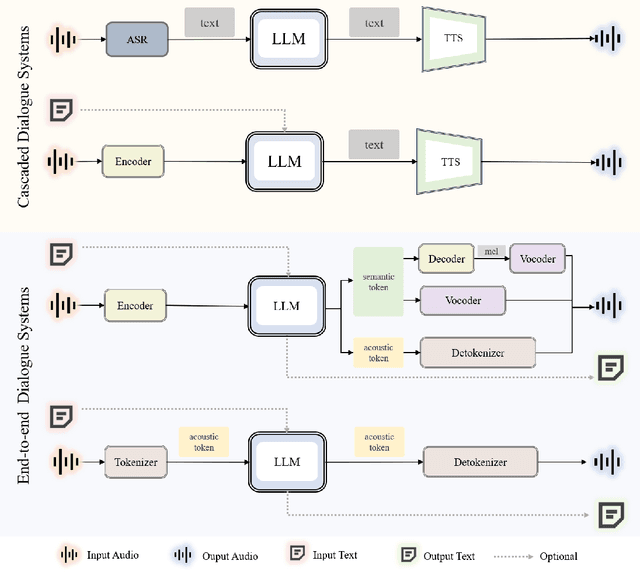
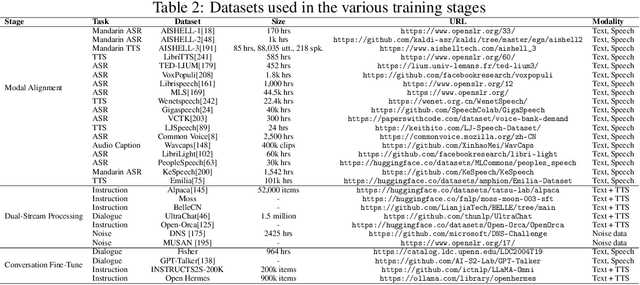
Recent advancements in spoken dialogue models, exemplified by systems like GPT-4o, have captured significant attention in the speech domain. Compared to traditional three-tier cascaded spoken dialogue models that comprise speech recognition (ASR), large language models (LLMs), and text-to-speech (TTS), modern spoken dialogue models exhibit greater intelligence. These advanced spoken dialogue models not only comprehend audio, music, and other speech-related features, but also capture stylistic and timbral characteristics in speech. Moreover, they generate high-quality, multi-turn speech responses with low latency, enabling real-time interaction through simultaneous listening and speaking capability. Despite the progress in spoken dialogue systems, there is a lack of comprehensive surveys that systematically organize and analyze these systems and the underlying technologies. To address this, we have first compiled existing spoken dialogue systems in the chronological order and categorized them into the cascaded and end-to-end paradigms. We then provide an in-depth overview of the core technologies in spoken dialogue models, covering aspects such as speech representation, training paradigm, streaming, duplex, and interaction capabilities. Each section discusses the limitations of these technologies and outlines considerations for future research. Additionally, we present a thorough review of relevant datasets, evaluation metrics, and benchmarks from the perspectives of training and evaluating spoken dialogue systems. We hope this survey will contribute to advancing both academic research and industrial applications in the field of spoken dialogue systems. The related material is available at https://github.com/jishengpeng/WavChat.
Improving Text-guided Object Inpainting with Semantic Pre-inpainting
Sep 12, 2024Recent years have witnessed the success of large text-to-image diffusion models and their remarkable potential to generate high-quality images. The further pursuit of enhancing the editability of images has sparked significant interest in the downstream task of inpainting a novel object described by a text prompt within a designated region in the image. Nevertheless, the problem is not trivial from two aspects: 1) Solely relying on one single U-Net to align text prompt and visual object across all the denoising timesteps is insufficient to generate desired objects; 2) The controllability of object generation is not guaranteed in the intricate sampling space of diffusion model. In this paper, we propose to decompose the typical single-stage object inpainting into two cascaded processes: 1) semantic pre-inpainting that infers the semantic features of desired objects in a multi-modal feature space; 2) high-fieldity object generation in diffusion latent space that pivots on such inpainted semantic features. To achieve this, we cascade a Transformer-based semantic inpainter and an object inpainting diffusion model, leading to a novel CAscaded Transformer-Diffusion (CAT-Diffusion) framework for text-guided object inpainting. Technically, the semantic inpainter is trained to predict the semantic features of the target object conditioning on unmasked context and text prompt. The outputs of the semantic inpainter then act as the informative visual prompts to guide high-fieldity object generation through a reference adapter layer, leading to controllable object inpainting. Extensive evaluations on OpenImages-V6 and MSCOCO validate the superiority of CAT-Diffusion against the state-of-the-art methods. Code is available at \url{https://github.com/Nnn-s/CATdiffusion}.
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
Aug 29, 2024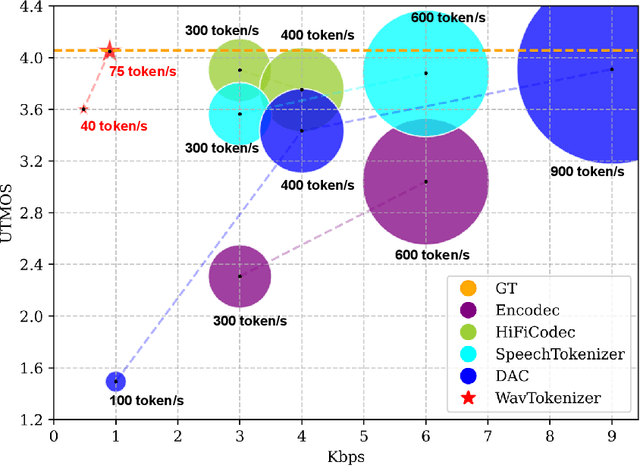
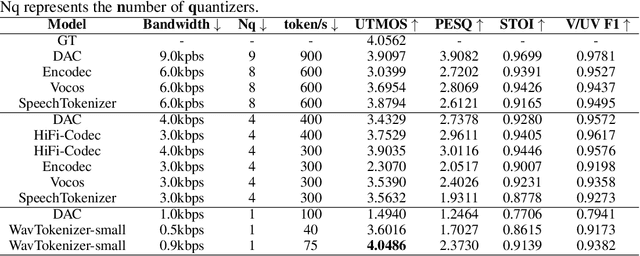
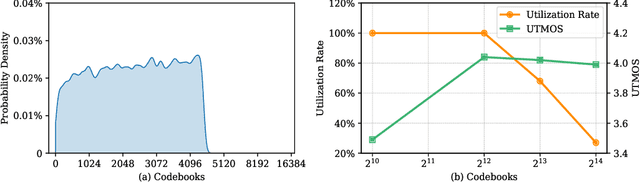
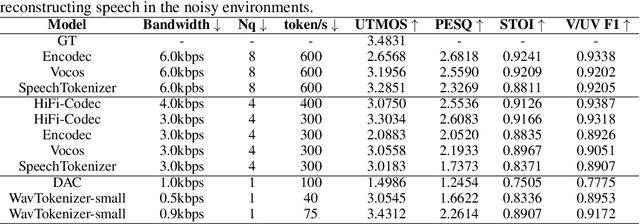
Language models have been effectively applied to modeling natural signals, such as images, video, speech, and audio. A crucial component of these models is the codec tokenizer, which compresses high-dimensional natural signals into lower-dimensional discrete tokens. In this paper, we introduce WavTokenizer, which offers several advantages over previous SOTA acoustic codec models in the audio domain: 1)extreme compression. By compressing the layers of quantizers and the temporal dimension of the discrete codec, one-second audio of 24kHz sampling rate requires only a single quantizer with 40 or 75 tokens. 2)improved subjective quality. Despite the reduced number of tokens, WavTokenizer achieves state-of-the-art reconstruction quality with outstanding UTMOS scores and inherently contains richer semantic information. Specifically, we achieve these results by designing a broader VQ space, extended contextual windows, and improved attention networks, as well as introducing a powerful multi-scale discriminator and an inverse Fourier transform structure. We conducted extensive reconstruction experiments in the domains of speech, audio, and music. WavTokenizer exhibited strong performance across various objective and subjective metrics compared to state-of-the-art models. We also tested semantic information, VQ utilization, and adaptability to generative models. Comprehensive ablation studies confirm the necessity of each module in WavTokenizer. The related code, demos, and pre-trained models are available at https://github.com/jishengpeng/WavTokenizer.
OS-FPI: A Coarse-to-Fine One-Stream Network for UAV Geo-Localization
Mar 10, 2024The geo-localization and navigation technology of unmanned aerial vehicles (UAVs) in denied environments is currently a prominent research area. Prior approaches mainly employed a two-stream network with non-shared weights to extract features from UAV and satellite images separately, followed by related modeling to obtain the response map. However, the two-stream network extracts UAV and satellite features independently. This approach significantly affects the efficiency of feature extraction and increases the computational load. To address these issues, we propose a novel coarse-to-fine one-stream network (OS-FPI). Our approach allows information exchange between UAV and satellite features during early image feature extraction. To improve the model's performance, the framework retains feature maps generated at different stages of the feature extraction process for the feature fusion network, and establishes additional connections between UAV and satellite feature maps in the feature fusion network. Additionally, the framework introduces offset prediction to further refine and optimize the model's prediction results based on the classification tasks. Our proposed model, boasts a similar inference speed to FPI while significantly reducing the number of parameters. It can achieve better performance with fewer parameters under the same conditions. Moreover, it achieves state-of-the-art performance on the UL14 dataset. Compared to previous models, our model achieved a significant 10.92-point improvement on the RDS metric, reaching 76.25. Furthermore, its performance in meter-level localization accuracy is impressive, with 182.62% improvement in 3-meter accuracy, 164.17% improvement in 5-meter accuracy, and 137.43% improvement in 10-meter accuracy.
Skywork: A More Open Bilingual Foundation Model
Oct 30, 2023
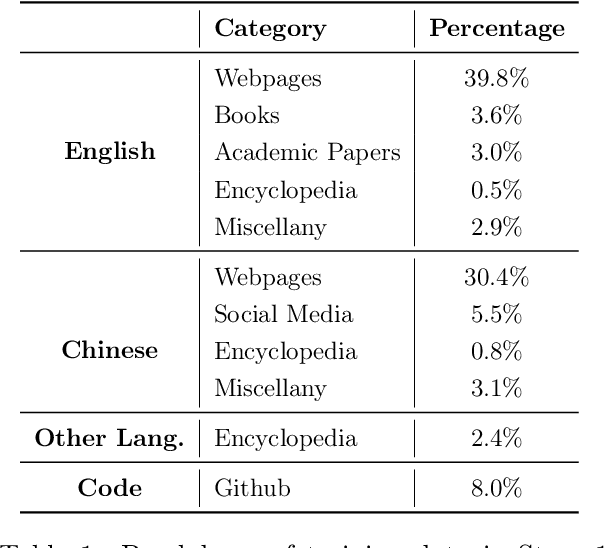
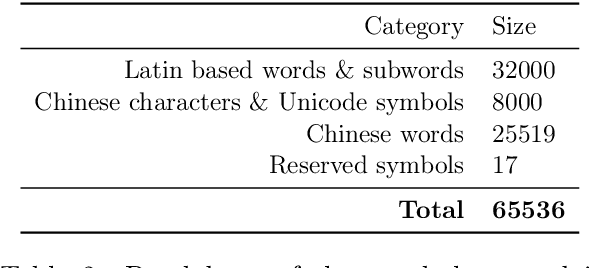
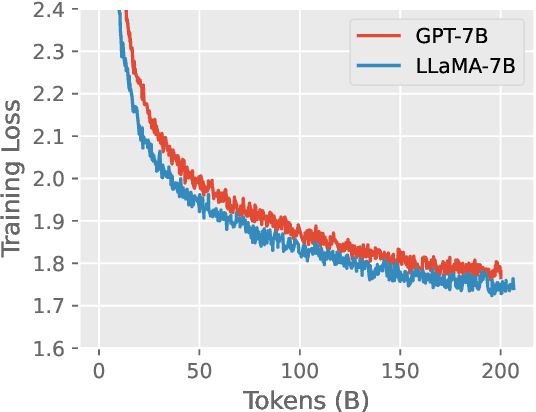
In this technical report, we present Skywork-13B, a family of large language models (LLMs) trained on a corpus of over 3.2 trillion tokens drawn from both English and Chinese texts. This bilingual foundation model is the most extensively trained and openly published LLMs of comparable size to date. We introduce a two-stage training methodology using a segmented corpus, targeting general purpose training and then domain-specific enhancement training, respectively. We show that our model not only excels on popular benchmarks, but also achieves \emph{state of the art} performance in Chinese language modeling on diverse domains. Furthermore, we propose a novel leakage detection method, demonstrating that test data contamination is a pressing issue warranting further investigation by the LLM community. To spur future research, we release Skywork-13B along with checkpoints obtained during intermediate stages of the training process. We are also releasing part of our SkyPile corpus, a collection of over 150 billion tokens of web text, which is the largest high quality open Chinese pre-training corpus to date. We hope Skywork-13B and our open corpus will serve as a valuable open-source resource to democratize access to high-quality LLMs.
SkyMath: Technical Report
Oct 26, 2023Large language models (LLMs) have shown great potential to solve varieties of natural language processing (NLP) tasks, including mathematical reasoning. In this work, we present SkyMath, a large language model for mathematics with 13 billion parameters. By applying self-compare fine-tuning, we have enhanced mathematical reasoning abilities of Skywork-13B-Base remarkably. On GSM8K, SkyMath outperforms all known open-source models of similar size and has established a new SOTA performance.
Hybrid Augmented Automated Graph Contrastive Learning
Mar 24, 2023Graph augmentations are essential for graph contrastive learning. Most existing works use pre-defined random augmentations, which are usually unable to adapt to different input graphs and fail to consider the impact of different nodes and edges on graph semantics. To address this issue, we propose a framework called Hybrid Augmented Automated Graph Contrastive Learning (HAGCL). HAGCL consists of a feature-level learnable view generator and an edge-level learnable view generator. The view generators are end-to-end differentiable to learn the probability distribution of views conditioned on the input graph. It insures to learn the most semantically meaningful structure in terms of features and topology, respectively. Furthermore, we propose an improved joint training strategy, which can achieve better results than previous works without resorting to any weak label information in the downstream tasks and extensive evaluation of additional work.