 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAP: Parameter-efficient Task-Aware Prompting for Adverse Weather Removal
Aug 11, 2025Image restoration under adverse weather conditions has been extensively explored, leading to numerous high-performance methods. In particular, recent advances in All-in-One approaches have shown impressive results by training on multi-task image restoration datasets. However, most of these methods rely on dedicated network modules or parameters for each specific degradation type, resulting in a significant parameter overhead. Moreover, the relatedness across different restoration tasks is often overlooked. In light of these issues, we propose a parameter-efficient All-in-One image restoration framework that leverages task-aware enhanced prompts to tackle various adverse weather degradations.Specifically, we adopt a two-stage training paradigm consisting of a pretraining phase and a prompt-tuning phase to mitigate parameter conflicts across tasks. We first employ supervised learning to acquire general restoration knowledge, and then adapt the model to handle specific degradation via trainable soft prompts. Crucially, we enhance these task-specific prompts in a task-aware manner. We apply low-rank decomposition to these prompts to capture both task-general and task-specific characteristics, and impose contrastive constraints to better align them with the actual inter-task relatedness. These enhanced prompts not only improve the parameter efficiency of the restoration model but also enable more accurate task modeling, as evidenced by t-SNE analysis. Experimental results on different restoration tasks demonstrate that the proposed method achieves superior performance with only 2.75M parameters.
IRBridge: Solving Image Restoration Bridge with Pre-trained Generative Diffusion Models
May 30, 2025Bridge models in image restoration construct a diffusion process from degraded to clear images. However, existing methods typically require training a bridge model from scratch for each specific type of degradation, resulting in high computational costs and limited performance. This work aims to efficiently leverage pretrained generative priors within existing image restoration bridges to eliminate this requirement. The main challenge is that standard generative models are typically designed for a diffusion process that starts from pure noise, while restoration tasks begin with a low-quality image, resulting in a mismatch in the state distributions between the two processes. To address this challenge, we propose a transition equation that bridges two diffusion processes with the same endpoint distribution. Based on this, we introduce the IRBridge framework, which enables the direct utilization of generative models within image restoration bridges, offering a more flexible and adaptable approach to image restoration. Extensive experiments on six image restoration tasks demonstrate that IRBridge efficiently integrates generative priors, resulting in improved robustness and generalization performance. Code will be available at GitHub.
WavChat: A Survey of Spoken Dialogue Models
Nov 26, 2024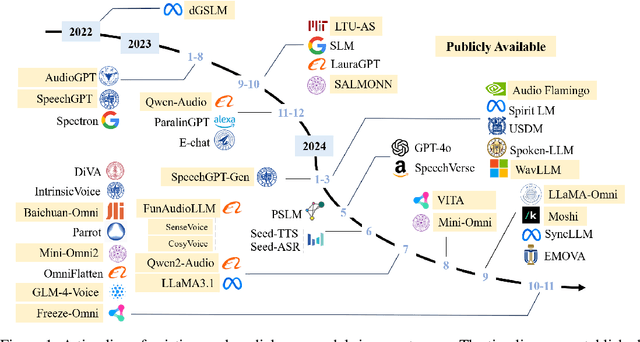

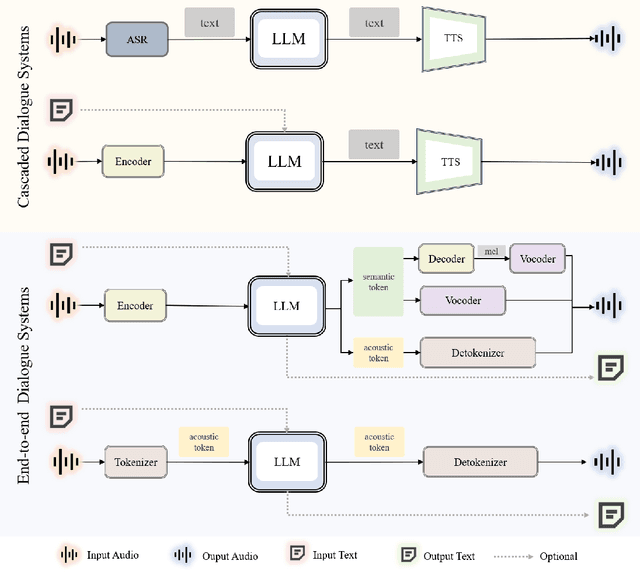
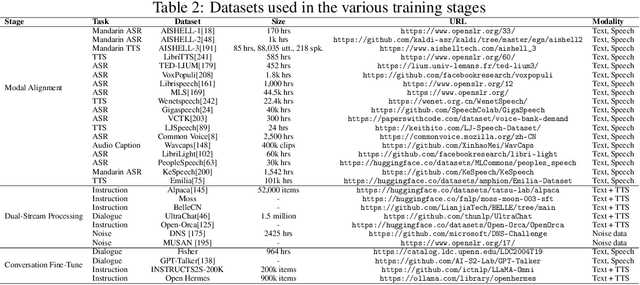
Recent advancements in spoken dialogue models, exemplified by systems like GPT-4o, have captured significant attention in the speech domain. Compared to traditional three-tier cascaded spoken dialogue models that comprise speech recognition (ASR), large language models (LLMs), and text-to-speech (TTS), modern spoken dialogue models exhibit greater intelligence. These advanced spoken dialogue models not only comprehend audio, music, and other speech-related features, but also capture stylistic and timbral characteristics in speech. Moreover, they generate high-quality, multi-turn speech responses with low latency, enabling real-time interaction through simultaneous listening and speaking capability. Despite the progress in spoken dialogue systems, there is a lack of comprehensive surveys that systematically organize and analyze these systems and the underlying technologies. To address this, we have first compiled existing spoken dialogue systems in the chronological order and categorized them into the cascaded and end-to-end paradigms. We then provide an in-depth overview of the core technologies in spoken dialogue models, covering aspects such as speech representation, training paradigm, streaming, duplex, and interaction capabilities. Each section discusses the limitations of these technologies and outlines considerations for future research. Additionally, we present a thorough review of relevant datasets, evaluation metrics, and benchmarks from the perspectives of training and evaluating spoken dialogue systems. We hope this survey will contribute to advancing both academic research and industrial applications in the field of spoken dialogue systems. The related material is available at https://github.com/jishengpeng/WavChat.
Unlocking the Potential of Multimodal Unified Discrete Representation through Training-Free Codebook Optimization and Hierarchical Alignment
Mar 08, 2024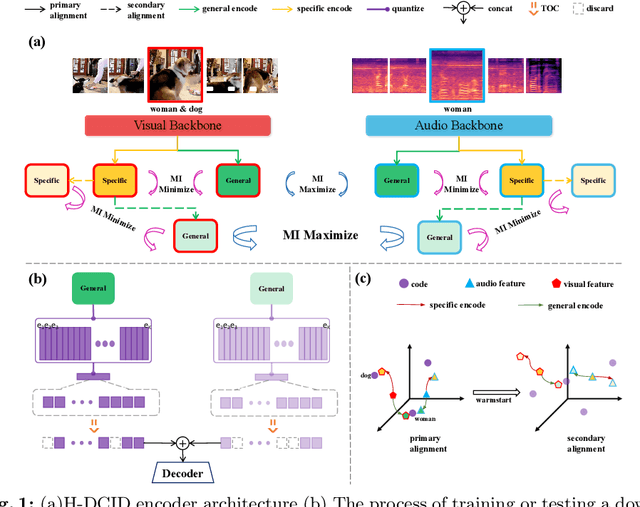
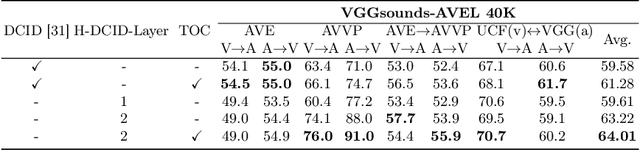
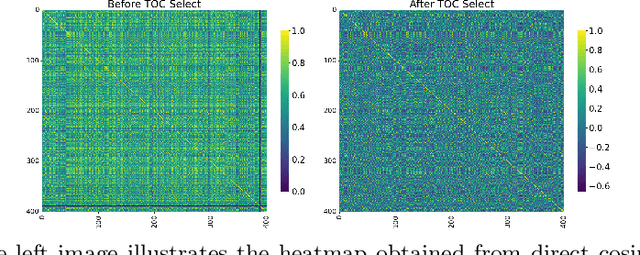
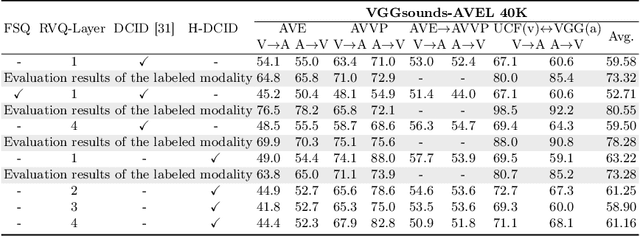
Recent advances in representation learning have demonstrated the significance of multimodal alignment. The Dual Cross-modal Information Disentanglement (DCID) model, utilizing a unified codebook, shows promising results in achieving fine-grained representation and cross-modal generalization. However, it is still hindered by equal treatment of all channels and neglect of minor event information, resulting in interference from irrelevant channels and limited performance in fine-grained tasks. Thus, in this work, We propose a Training-free Optimization of Codebook (TOC) method to enhance model performance by selecting important channels in the unified space without retraining. Additionally, we introduce the Hierarchical Dual Cross-modal Information Disentanglement (H-DCID) approach to extend information separation and alignment to two levels, capturing more cross-modal details. The experiment results demonstrate significant improvements across various downstream tasks, with TOC contributing to an average improvement of 1.70% for DCID on four tasks, and H-DCID surpassing DCID by an average of 3.64%. The combination of TOC and H-DCID further enhances performance, exceeding DCID by 4.43%. These findings highlight the effectiveness of our methods in facilitating robust and nuanced cross-modal learning, opening avenues for future enhancements. The source code and pre-trained models can be accessed at https://github.com/haihuangcode/TOC_H-DCID.
MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech
Feb 14, 2024Zero-shot text-to-speech (TTS) has gained significant attention due to its powerful voice cloning capabilities, requiring only a few seconds of unseen speaker voice prompts. However, all previous work has been developed for cloud-based systems. Taking autoregressive models as an example, although these approaches achieve high-fidelity voice cloning, they fall short in terms of inference speed, model size, and robustness. Therefore, we propose MobileSpeech, which is a fast, lightweight, and robust zero-shot text-to-speech system based on mobile devices for the first time. Specifically: 1) leveraging discrete codec, we design a parallel speech mask decoder module called SMD, which incorporates hierarchical information from the speech codec and weight mechanisms across different codec layers during the generation process. Moreover, to bridge the gap between text and speech, we introduce a high-level probabilistic mask that simulates the progression of information flow from less to more during speech generation. 2) For speaker prompts, we extract fine-grained prompt duration from the prompt speech and incorporate text, prompt speech by cross attention in SMD. We demonstrate the effectiveness of MobileSpeech on multilingual datasets at different levels, achieving state-of-the-art results in terms of generating speed and speech quality. MobileSpeech achieves RTF of 0.09 on a single A100 GPU and we have successfully deployed MobileSpeech on mobile devices. Audio samples are available at \url{https://mobilespeech.github.io/} .