 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST$^3$: Accelerating Multimodal Large Language Model by Spatial-Temporal Visual Token Trimming
Paper and Code
Dec 28, 2024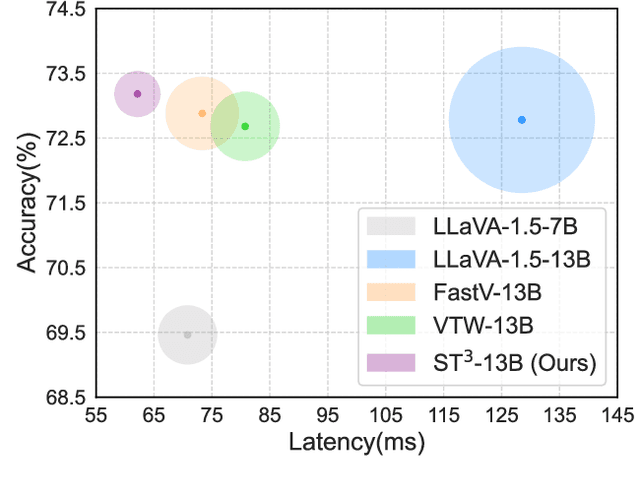



Multimodal large language models (MLLMs) enhance their perceptual capabilities by integrating visual and textual information. However, processing the massive number of visual tokens incurs a significant computational cost. Existing analysis of the MLLM attention mechanisms remains shallow, leading to coarse-grain token pruning strategies that fail to effectively balance speed and accuracy. In this paper, we conduct a comprehensive investigation of MLLM attention mechanisms with LLaVA. We find that numerous visual tokens and partial attention computations are redundant during the decoding process. Based on this insight, we propose Spatial-Temporal Visual Token Trimming ($\textbf{ST}^{3}$), a framework designed to accelerate MLLM inference without retraining. $\textbf{ST}^{3}$ consists of two primary components: 1) Progressive Visual Token Pruning (\textbf{PVTP}), which eliminates inattentive visual tokens across layers, and 2) Visual Token Annealing (\textbf{VTA}), which dynamically reduces the number of visual tokens in each layer as the generated tokens grow. Together, these techniques deliver around $\mathbf{2\times}$ faster inference with only about $\mathbf{30\%}$ KV cache memory compared to the original LLaVA, while maintaining consistent performance across various datasets. Crucially, $\textbf{ST}^{3}$ can be seamlessly integrated into existing pre-trained MLLMs, providing a plug-and-play solution for efficient inference.