 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeDecider: An LLM-Based Framework for Federated Cross-Domain Recommendation
Feb 17, 2026Federated cross-domain recommendation (Federated CDR) aims to collaboratively learn personalized recommendation models across heterogeneous domains while preserving data privacy. Recently, large language model (LLM)-based recommendation models have demonstrated impressive performance by leveraging LLMs' strong reasoning capabilities and broad knowledge. However, adopting LLM-based recommendation models in Federated CDR scenarios introduces new challenges. First, there exists a risk of overfitting with domain-specific local adapters. The magnitudes of locally optimized parameter updates often vary across domains, causing biased aggregation and overfitting toward domain-specific distributions. Second, unlike traditional recommendation models (e.g., collaborative filtering, bipartite graph-based methods) that learn explicit and comparable user/item representations, LLMs encode knowledge implicitly through autoregressive text generation training. This poses additional challenges for effectively measuring the cross-domain similarities under heterogeneity. To address these challenges, we propose an LLM-based framework for federated cross-domain recommendation, FeDecider. Specifically, FeDecider tackles the challenge of scale-specific noise by disentangling each client's low-rank updates and sharing only their directional components. To handle the need for flexible and effective integration, each client further learns personalized weights that achieve the data-aware integration of updates from other domains. Extensive experiments across diverse datasets validate the effectiveness of our proposed FeDecider.
LithoSeg: A Coarse-to-Fine Framework for High-Precision Lithography Segmentation
Nov 15, 2025Accurate segmentation and measurement of lithography scanning electron microscope (SEM) images are crucial for ensuring precise process control, optimizing device performance, and advancing semiconductor manufacturing yield. Lithography segmentation requires pixel-level delineation of groove contours and consistent performance across diverse pattern geometries and process window. However, existing methods often lack the necessary precision and robustness, limiting their practical applicability. To overcome this challenge, we propose LithoSeg, a coarse-to-fine network tailored for lithography segmentation. In the coarse stage, we introduce a Human-in-the-Loop Bootstrapping scheme for the Segment Anything Model (SAM) to attain robustness with minimal supervision. In the subsequent fine stage, we recast 2D segmentation as 1D regression problem by sampling groove-normal profiles using the coarse mask and performing point-wise refinement with a lightweight MLP. LithoSeg outperforms previous approaches in both segmentation accuracy and metrology precision while requiring less supervision, offering promising prospects for real-world applications.
Differential Alignment for Domain Adaptive Object Detection
Dec 17, 2024



Domain adaptive object detection (DAOD) aims to generalize an object detector trained on labeled source-domain data to a target domain without annotations, the core principle of which is \emph{source-target feature alignment}. Typically, existing approaches employ adversarial learning to align the distributions of the source and target domains as a whole, barely considering the varying significance of distinct regions, say instances under different circumstances and foreground \emph{vs} background areas, during feature alignment. To overcome the shortcoming, we investigates a differential feature alignment strategy. Specifically, a prediction-discrepancy feedback instance alignment module (dubbed PDFA) is designed to adaptively assign higher weights to instances of higher teacher-student detection discrepancy, effectively handling heavier domain-specific information. Additionally, an uncertainty-based foreground-oriented image alignment module (UFOA) is proposed to explicitly guide the model to focus more on regions of interest. Extensive experiments on widely-used DAOD datasets together with ablation studies are conducted to demonstrate the efficacy of our proposed method and reveal its superiority over other SOTA alternatives. Our code is available at https://github.com/EstrellaXyu/Differential-Alignment-for-DAOD.
DeBaTeR: Denoising Bipartite Temporal Graph for Recommendation
Nov 14, 2024



Due to the difficulty of acquiring large-scale explicit user feedback, implicit feedback (e.g., clicks or other interactions) is widely applied as an alternative source of data, where user-item interactions can be modeled as a bipartite graph. Due to the noisy and biased nature of implicit real-world user-item interactions, identifying and rectifying noisy interactions are vital to enhance model performance and robustness. Previous works on purifying user-item interactions in collaborative filtering mainly focus on mining the correlation between user/item embeddings and noisy interactions, neglecting the benefit of temporal patterns in determining noisy interactions. Time information, while enhancing the model utility, also bears its natural advantage in helping to determine noisy edges, e.g., if someone usually watches horror movies at night and talk shows in the morning, a record of watching a horror movie in the morning is more likely to be noisy interaction. Armed with this observation, we introduce a simple yet effective mechanism for generating time-aware user/item embeddings and propose two strategies for denoising bipartite temporal graph in recommender systems (DeBaTeR): the first is through reweighting the adjacency matrix (DeBaTeR-A), where a reliability score is defined to reweight the edges through both soft assignment and hard assignment; the second is through reweighting the loss function (DeBaTeR-L), where weights are generated to reweight user-item samples in the losses. Extensive experiments have been conducted to demonstrate the efficacy of our methods and illustrate how time information indeed helps identifying noisy edges.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024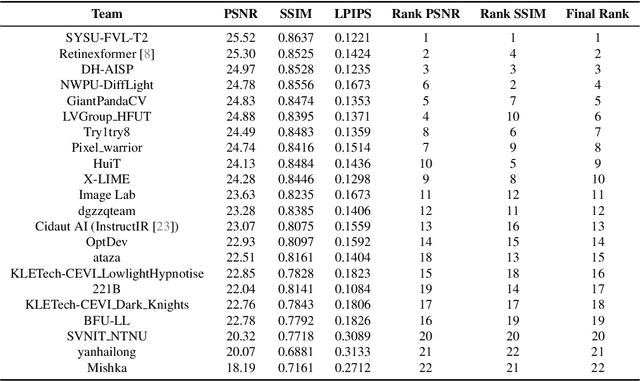

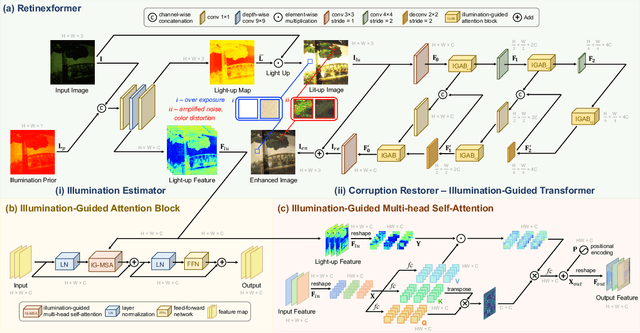

This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Knowledge NeRF: Few-shot Novel View Synthesis for Dynamic Articulated Objects
Apr 07, 2024



We present Knowledge NeRF to synthesize novel views for dynamic scenes. Reconstructing dynamic 3D scenes from few sparse views and rendering them from arbitrary perspectives is a challenging problem with applications in various domains. Previous dynamic NeRF methods learn the deformation of articulated objects from monocular videos. However, qualities of their reconstructed scenes are limited. To clearly reconstruct dynamic scenes, we propose a new framework by considering two frames at a time.We pretrain a NeRF model for an articulated object.When articulated objects moves, Knowledge NeRF learns to generate novel views at the new state by incorporating past knowledge in the pretrained NeRF model with minimal observations in the present state. We propose a projection module to adapt NeRF for dynamic scenes, learning the correspondence between pretrained knowledge base and current states. Experimental results demonstrate the effectiveness of our method in reconstructing dynamic 3D scenes with 5 input images in one state. Knowledge NeRF is a new pipeline and promising solution for novel view synthesis in dynamic articulated objects. The data and implementation are publicly available at https://github.com/RussRobin/Knowledge_NeRF.
Agonist-Antagonist Pouch Motors: Bidirectional Soft Actuators Enhanced by Thermally Responsive Peltier Elements
Mar 16, 2024



In this study, we introduce a novel Mylar-based pouch motor design that leverages the reversible actuation capabilities of Peltier junctions to enable agonist-antagonist muscle mimicry in soft robotics. Addressing the limitations of traditional silicone-based materials, such as leakage and phase-change fluid degradation, our pouch motors filled with Novec 7000 provide a durable and leak-proof solution for geometric modeling. The integration of flexible Peltier junctions offers a significant advantage over conventional Joule heating methods by allowing active and reversible heating and cooling cycles. This innovation not only enhances the reliability and longevity of soft robotic applications but also broadens the scope of design possibilities, including the development of agonist-antagonist artificial muscles, grippers with can manipulate through flexion and extension, and an anchor-slip style simple crawler design. Our findings indicate that this approach could lead to more efficient, versatile, and durable robotic systems, marking a significant advancement in the field of soft robotics.
Context Matters: A Strategy to Pre-train Language Model for Science Education
Jan 27, 2023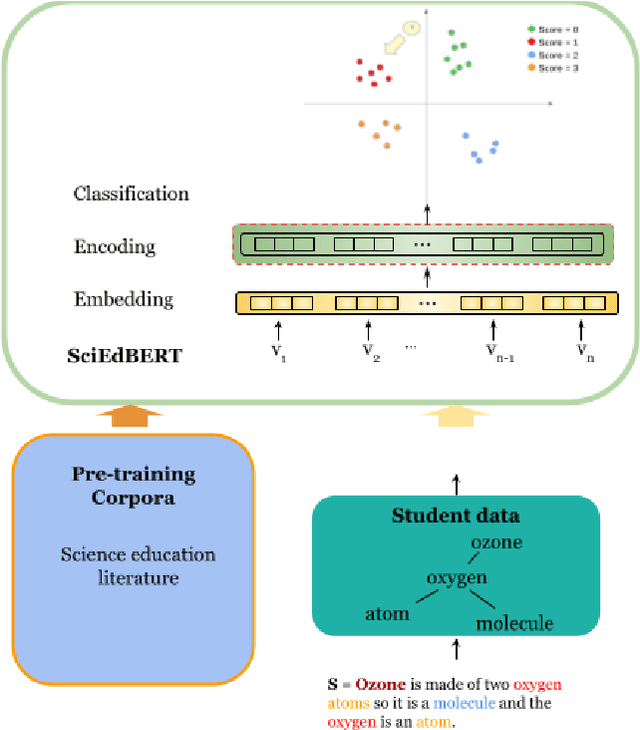
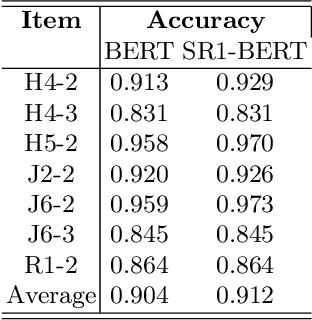
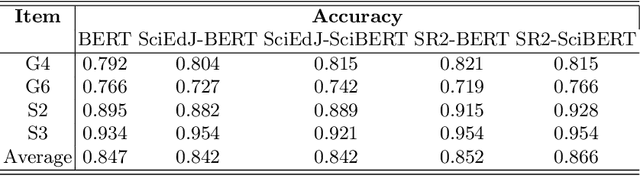
This study aims at improving the performance of scoring student responses in science education automatically. BERT-based language models have shown significant superiority over traditional NLP models in various language-related tasks. However, science writing of students, including argumentation and explanation, is domain-specific. In addition, the language used by students is different from the language in journals and Wikipedia, which are training sources of BERT and its existing variants. All these suggest that a domain-specific model pre-trained using science education data may improve model performance. However, the ideal type of data to contextualize pre-trained language model and improve the performance in automatically scoring student written responses remains unclear. Therefore, we employ different data in this study to contextualize both BERT and SciBERT models and compare their performance on automatic scoring of assessment tasks for scientific argumentation. We use three datasets to pre-train the model: 1) journal articles in science education, 2) a large dataset of students' written responses (sample size over 50,000), and 3) a small dataset of students' written responses of scientific argumentation tasks. Our experimental results show that in-domain training corpora constructed from science questions and responses improve language model performance on a wide variety of downstream tasks. Our study confirms the effectiveness of continual pre-training on domain-specific data in the education domain and demonstrates a generalizable strategy for automating science education tasks with high accuracy. We plan to release our data and SciEdBERT models for public use and community engagement.
Matching Exemplar as Next Sentence Prediction (MeNSP): Zero-shot Prompt Learning for Automatic Scoring in Science Education
Jan 20, 2023Developing models to automatically score students' written responses to science problems is critical for science education. However, collecting and labeling sufficient student responses for training models is time and cost-consuming. Recent studies suggest that pre-trained language models (PLMs) can be adapted to downstream tasks without fine-tuning with prompts. However, no research has employed such a prompt approach in science education. As student responses are presented with natural language, aligning the scoring procedure as the next sentence prediction task using prompts can skip the costly fine-tuning stage. In this study, we developed a zero-shot approach to automatically score student responses via Matching Exemplars as Next Sentence Prediction (MeNSP). This approach employs no training samples. We first apply MeNSP in scoring three assessment tasks of scientific argumentation and found machine-human scoring agreements, Cohen's Kappa ranges from 0.30 to 0.57, and F1 score ranges from 0.54 to 0.81. To improve the performance, we extend our research to the few-shots setting, either randomly selecting labeled student responses or manually constructing responses to fine-tune the models. We find that one task's performance is improved with more samples, Cohen's Kappa from 0.30 to 0.38, and F1 score from 0.54 to 0.59; for the two others, scoring performance is not improved. We also find that randomly selected few-shots perform better than the human expert-crafted approach. This study suggests that MeNSP can yield referable automatic scoring for student responses while significantly reducing the cost of model training. This method can benefit low-stakes classroom assessment practices in science education. Future research should further explore the applicability of the MeNSP in different types of assessment tasks in science education and improve the model performance.
Data-driven Method for Estimating Aircraft Mass from Quick Access Recorder using Aircraft Dynamics and Multilayer Perceptron Neural Network
Dec 10, 2020

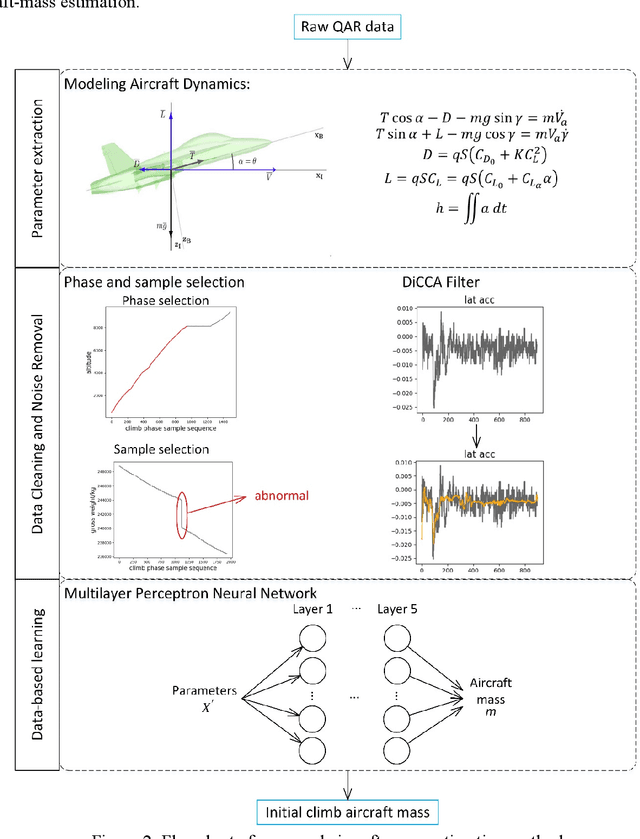
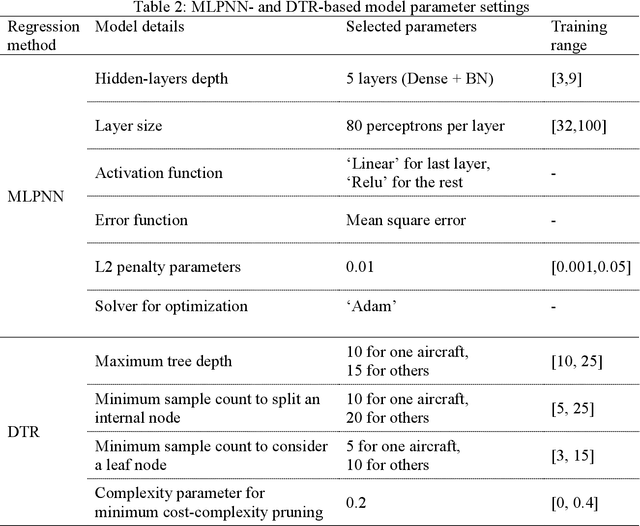
Accurate aircraft-mass estimation is critical to airlines from the safety-management and performance-optimization viewpoints. Overloading an aircraft with passengers and baggage might result in a safety hazard. In contrast, not fully utilizing an aircraft's payload-carrying capacity undermines its operational efficiency and airline profitability. However, accurate determination of the aircraft mass for each operating flight is not feasible because it is impractical to weigh each aircraft component, including the payload. The existing methods for aircraft-mass estimation are dependent on the aircraft- and engine-performance parameters, which are usually considered proprietary information. Moreover, the values of these parameters vary under different operating conditions while those of others might be subject to large estimation errors. This paper presents a data-driven method involving use of the quick access recorder (QAR)-a digital flight-data recorder-installed on all aircrafts to record the initial aircraft climb mass during each flight. The method requires users to select appropriate parameters among several thousand others recorded by the QAR using physical models. The selected data are subsequently processed and provided as input to a multilayer perceptron neural network for building the model for initial-climb aircraft-mass prediction. Thus, the proposed method offers the advantages of both the model-based and data-driven approaches for aircraft-mass estimation. Because this method does not explicitly rely on any aircraft or engine parameter, it is universally applicable to all aircraft types. In this study, the proposed method was applied to a set of Boeing 777-300ER aircrafts, the results of which demonstrated reasonable accuracy. Airlines can use this tool to better utilize aircraft's payload.