 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Learning for Stochastic Optimization with Nonlinear Parametric Belief Models
Paper and Code
Nov 22, 2016
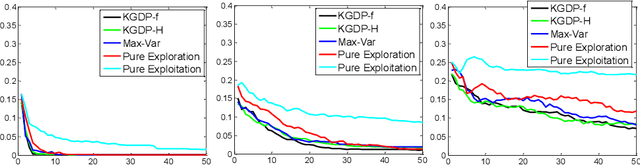


We consider the problem of estimating the expected value of information (the knowledge gradient) for Bayesian learning problems where the belief model is nonlinear in the parameters. Our goal is to maximize some metric, while simultaneously learning the unknown parameters of the nonlinear belief model, by guiding a sequential experimentation process which is expensive. We overcome the problem of computing the expected value of an experiment, which is computationally intractable, by using a sampled approximation, which helps to guide experiments but does not provide an accurate estimate of the unknown parameters. We then introduce a resampling process which allows the sampled model to adapt to new information, exploiting past experiments. We show theoretically that the method converges asymptotically to the true parameters, while simultaneously maximizing our metric. We show empirically that the process exhibits rapid convergence, yielding good results with a very small number of experiments.