 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeBaTeR: Denoising Bipartite Temporal Graph for Recommendation
Nov 14, 2024



Due to the difficulty of acquiring large-scale explicit user feedback, implicit feedback (e.g., clicks or other interactions) is widely applied as an alternative source of data, where user-item interactions can be modeled as a bipartite graph. Due to the noisy and biased nature of implicit real-world user-item interactions, identifying and rectifying noisy interactions are vital to enhance model performance and robustness. Previous works on purifying user-item interactions in collaborative filtering mainly focus on mining the correlation between user/item embeddings and noisy interactions, neglecting the benefit of temporal patterns in determining noisy interactions. Time information, while enhancing the model utility, also bears its natural advantage in helping to determine noisy edges, e.g., if someone usually watches horror movies at night and talk shows in the morning, a record of watching a horror movie in the morning is more likely to be noisy interaction. Armed with this observation, we introduce a simple yet effective mechanism for generating time-aware user/item embeddings and propose two strategies for denoising bipartite temporal graph in recommender systems (DeBaTeR): the first is through reweighting the adjacency matrix (DeBaTeR-A), where a reliability score is defined to reweight the edges through both soft assignment and hard assignment; the second is through reweighting the loss function (DeBaTeR-L), where weights are generated to reweight user-item samples in the losses. Extensive experiments have been conducted to demonstrate the efficacy of our methods and illustrate how time information indeed helps identifying noisy edges.
LLM-based Weak Supervision Framework for Query Intent Classification in Video Search
Sep 13, 2024


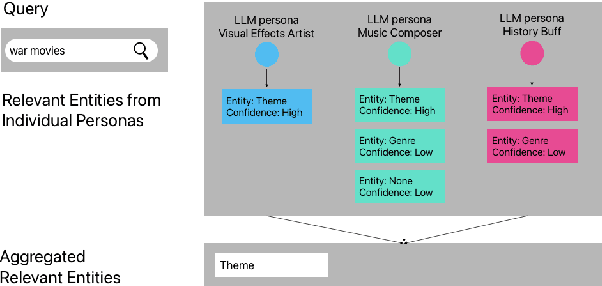
Streaming services have reshaped how we discover and engage with digital entertainment. Despite these advancements, effectively understanding the wide spectrum of user search queries continues to pose a significant challenge. An accurate query understanding system that can handle a variety of entities that represent different user intents is essential for delivering an enhanced user experience. We can build such a system by training a natural language understanding (NLU) model; however, obtaining high-quality labeled training data in this specialized domain is a substantial obstacle. Manual annotation is costly and impractical for capturing users' vast vocabulary variations. To address this, we introduce a novel approach that leverages large language models (LLMs) through weak supervision to automatically annotate a vast collection of user search queries. Using prompt engineering and a diverse set of LLM personas, we generate training data that matches human annotator expectations. By incorporating domain knowledge via Chain of Thought and In-Context Learning, our approach leverages the labeled data to train low-latency models optimized for real-time inference. Extensive evaluations demonstrated that our approach outperformed the baseline with an average relative gain of 113% in recall. Furthermore, our novel prompt engineering framework yields higher quality LLM-generated data to be used for weak supervision; we observed 47.60% improvement over baseline in agreement rate between LLM predictions and human annotations with respect to F1 score, weighted according to the distribution of occurrences of the search queries. Our persona selection routing mechanism further adds an additional 3.67% increase in weighted F1 score on top of our novel prompt engineering framework.