 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge NeRF: Few-shot Novel View Synthesis for Dynamic Articulated Objects
Apr 07, 2024



We present Knowledge NeRF to synthesize novel views for dynamic scenes. Reconstructing dynamic 3D scenes from few sparse views and rendering them from arbitrary perspectives is a challenging problem with applications in various domains. Previous dynamic NeRF methods learn the deformation of articulated objects from monocular videos. However, qualities of their reconstructed scenes are limited. To clearly reconstruct dynamic scenes, we propose a new framework by considering two frames at a time.We pretrain a NeRF model for an articulated object.When articulated objects moves, Knowledge NeRF learns to generate novel views at the new state by incorporating past knowledge in the pretrained NeRF model with minimal observations in the present state. We propose a projection module to adapt NeRF for dynamic scenes, learning the correspondence between pretrained knowledge base and current states. Experimental results demonstrate the effectiveness of our method in reconstructing dynamic 3D scenes with 5 input images in one state. Knowledge NeRF is a new pipeline and promising solution for novel view synthesis in dynamic articulated objects. The data and implementation are publicly available at https://github.com/RussRobin/Knowledge_NeRF.
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance
Mar 21, 2024
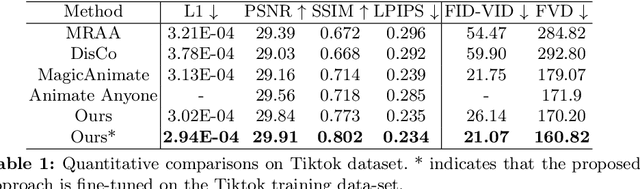
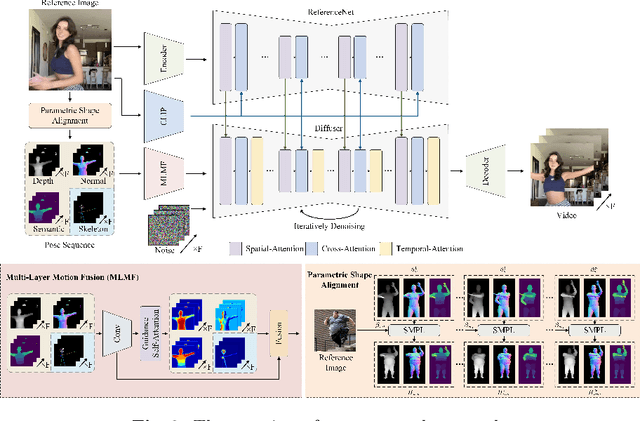
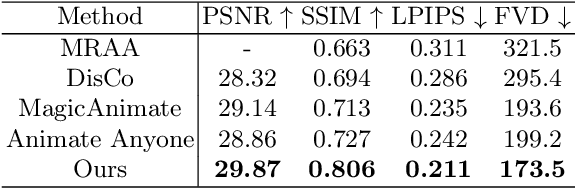
In this study, we introduce a methodology for human image animation by leveraging a 3D human parametric model within a latent diffusion framework to enhance shape alignment and motion guidance in curernt human generative techniques. The methodology utilizes the SMPL(Skinned Multi-Person Linear) model as the 3D human parametric model to establish a unified representation of body shape and pose. This facilitates the accurate capture of intricate human geometry and motion characteristics from source videos. Specifically, we incorporate rendered depth images, normal maps, and semantic maps obtained from SMPL sequences, alongside skeleton-based motion guidance, to enrich the conditions to the latent diffusion model with comprehensive 3D shape and detailed pose attributes. A multi-layer motion fusion module, integrating self-attention mechanisms, is employed to fuse the shape and motion latent representations in the spatial domain. By representing the 3D human parametric model as the motion guidance, we can perform parametric shape alignment of the human body between the reference image and the source video motion. Experimental evaluations conducted on benchmark datasets demonstrate the methodology's superior ability to generate high-quality human animations that accurately capture both pose and shape variations. Furthermore, our approach also exhibits superior generalization capabilities on the proposed wild dataset. Project page: https://fudan-generative-vision.github.io/champ.