 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVMem: Consistent Interactive Video Scene Generation with Surfel-Indexed View Memory
Jun 23, 2025We propose a novel memory mechanism to build video generators that can explore environments interactively. Similar results have previously been achieved by out-painting 2D views of the scene while incrementally reconstructing its 3D geometry, which quickly accumulates errors, or by video generators with a short context window, which struggle to maintain scene coherence over the long term. To address these limitations, we introduce Surfel-Indexed View Memory (VMem), a mechanism that remembers past views by indexing them geometrically based on the 3D surface elements (surfels) they have observed. VMem enables the efficient retrieval of the most relevant past views when generating new ones. By focusing only on these relevant views, our method produces consistent explorations of imagined environments at a fraction of the computational cost of using all past views as context. We evaluate our approach on challenging long-term scene synthesis benchmarks and demonstrate superior performance compared to existing methods in maintaining scene coherence and camera control.
Generalized Few-shot 3D Point Cloud Segmentation with Vision-Language Model
Mar 20, 2025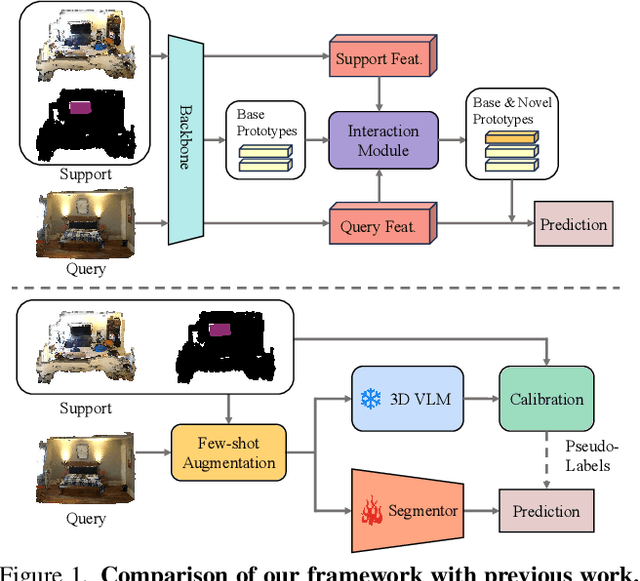
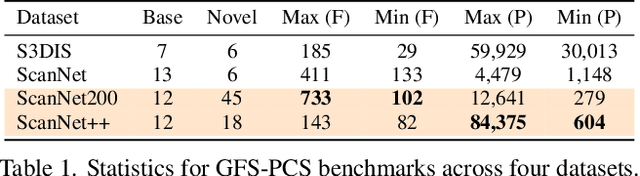
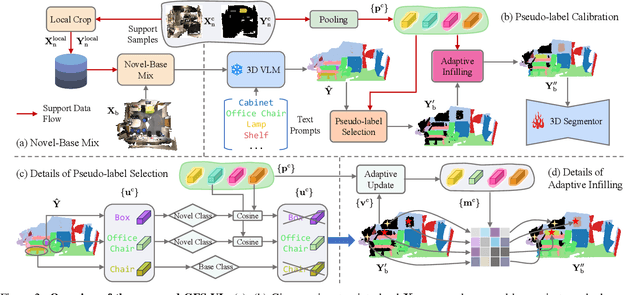
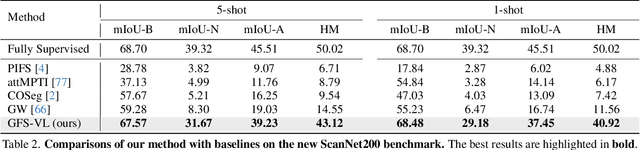
Generalized few-shot 3D point cloud segmentation (GFS-PCS) adapts models to new classes with few support samples while retaining base class segmentation. Existing GFS-PCS methods enhance prototypes via interacting with support or query features but remain limited by sparse knowledge from few-shot samples. Meanwhile, 3D vision-language models (3D VLMs), generalizing across open-world novel classes, contain rich but noisy novel class knowledge. In this work, we introduce a GFS-PCS framework that synergizes dense but noisy pseudo-labels from 3D VLMs with precise yet sparse few-shot samples to maximize the strengths of both, named GFS-VL. Specifically, we present a prototype-guided pseudo-label selection to filter low-quality regions, followed by an adaptive infilling strategy that combines knowledge from pseudo-label contexts and few-shot samples to adaptively label the filtered, unlabeled areas. Additionally, we design a novel-base mix strategy to embed few-shot samples into training scenes, preserving essential context for improved novel class learning. Moreover, recognizing the limited diversity in current GFS-PCS benchmarks, we introduce two challenging benchmarks with diverse novel classes for comprehensive generalization evaluation. Experiments validate the effectiveness of our framework across models and datasets. Our approach and benchmarks provide a solid foundation for advancing GFS-PCS in the real world. The code is at https://github.com/ZhaochongAn/GFS-VL
No Culture Left Behind: ArtELingo-28, a Benchmark of WikiArt with Captions in 28 Languages
Nov 06, 2024Research in vision and language has made considerable progress thanks to benchmarks such as COCO. COCO captions focused on unambiguous facts in English; ArtEmis introduced subjective emotions and ArtELingo introduced some multilinguality (Chinese and Arabic). However we believe there should be more multilinguality. Hence, we present ArtELingo-28, a vision-language benchmark that spans $\textbf{28}$ languages and encompasses approximately $\textbf{200,000}$ annotations ($\textbf{140}$ annotations per image). Traditionally, vision research focused on unambiguous class labels, whereas ArtELingo-28 emphasizes diversity of opinions over languages and cultures. The challenge is to build machine learning systems that assign emotional captions to images. Baseline results will be presented for three novel conditions: Zero-Shot, Few-Shot and One-vs-All Zero-Shot. We find that cross-lingual transfer is more successful for culturally-related languages. Data and code are provided at www.artelingo.org.
Multimodality Helps Few-Shot 3D Point Cloud Semantic Segmentation
Oct 29, 2024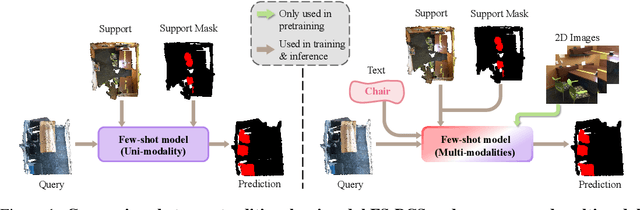
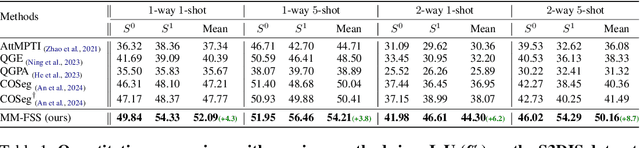
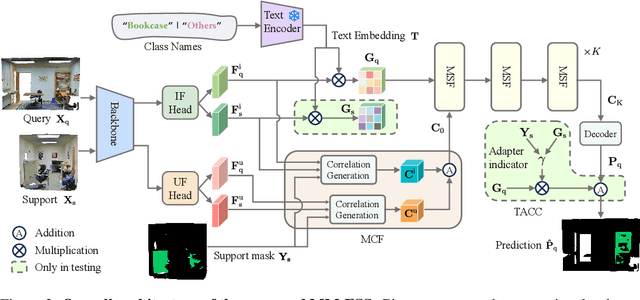
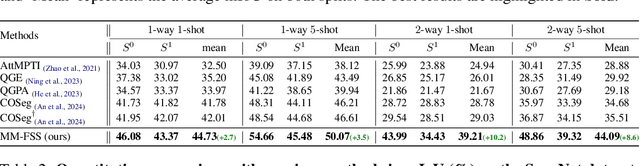
Few-shot 3D point cloud segmentation (FS-PCS) aims at generalizing models to segment novel categories with minimal annotated support samples. While existing FS-PCS methods have shown promise, they primarily focus on unimodal point cloud inputs, overlooking the potential benefits of leveraging multimodal information. In this paper, we address this gap by introducing a cost-free multimodal FS-PCS setup, utilizing textual labels and the potentially available 2D image modality. Under this easy-to-achieve setup, we present the MultiModal Few-Shot SegNet (MM-FSS), a model effectively harnessing complementary information from multiple modalities. MM-FSS employs a shared backbone with two heads to extract intermodal and unimodal visual features, and a pretrained text encoder to generate text embeddings. To fully exploit the multimodal information, we propose a Multimodal Correlation Fusion (MCF) module to generate multimodal correlations, and a Multimodal Semantic Fusion (MSF) module to refine the correlations using text-aware semantic guidance. Additionally, we propose a simple yet effective Test-time Adaptive Cross-modal Calibration (TACC) technique to mitigate training bias, further improving generalization. Experimental results on S3DIS and ScanNet datasets demonstrate significant performance improvements achieved by our method. The efficacy of our approach indicates the benefits of leveraging commonly-ignored free modalities for FS-PCS, providing valuable insights for future research. The code is available at https://github.com/ZhaochongAn/Multimodality-3D-Few-Shot .
Unified Convergence Analysis for Score-Based Diffusion Models with Deterministic Samplers
Oct 18, 2024Score-based diffusion models have emerged as powerful techniques for generating samples from high-dimensional data distributions. These models involve a two-phase process: first, injecting noise to transform the data distribution into a known prior distribution, and second, sampling to recover the original data distribution from noise. Among the various sampling methods, deterministic samplers stand out for their enhanced efficiency. However, analyzing these deterministic samplers presents unique challenges, as they preclude the use of established techniques such as Girsanov's theorem, which are only applicable to stochastic samplers. Furthermore, existing analysis for deterministic samplers usually focuses on specific examples, lacking a generalized approach for general forward processes and various deterministic samplers. Our paper addresses these limitations by introducing a unified convergence analysis framework. To demonstrate the power of our framework, we analyze the variance-preserving (VP) forward process with the exponential integrator (EI) scheme, achieving iteration complexity of $\tilde O(d^2/\epsilon)$. Additionally, we provide a detailed analysis of Denoising Diffusion Implicit Models (DDIM)-type samplers, which have been underexplored in previous research, achieving polynomial iteration complexity.
Semantic Score Distillation Sampling for Compositional Text-to-3D Generation
Oct 11, 2024



Generating high-quality 3D assets from textual descriptions remains a pivotal challenge in computer graphics and vision research. Due to the scarcity of 3D data, state-of-the-art approaches utilize pre-trained 2D diffusion priors, optimized through Score Distillation Sampling (SDS). Despite progress, crafting complex 3D scenes featuring multiple objects or intricate interactions is still difficult. To tackle this, recent methods have incorporated box or layout guidance. However, these layout-guided compositional methods often struggle to provide fine-grained control, as they are generally coarse and lack expressiveness. To overcome these challenges, we introduce a novel SDS approach, Semantic Score Distillation Sampling (SemanticSDS), designed to effectively improve the expressiveness and accuracy of compositional text-to-3D generation. Our approach integrates new semantic embeddings that maintain consistency across different rendering views and clearly differentiate between various objects and parts. These embeddings are transformed into a semantic map, which directs a region-specific SDS process, enabling precise optimization and compositional generation. By leveraging explicit semantic guidance, our method unlocks the compositional capabilities of existing pre-trained diffusion models, thereby achieving superior quality in 3D content generation, particularly for complex objects and scenes. Experimental results demonstrate that our SemanticSDS framework is highly effective for generating state-of-the-art complex 3D content. Code: https://github.com/YangLing0818/SemanticSDS-3D
DreamBeast: Distilling 3D Fantastical Animals with Part-Aware Knowledge Transfer
Sep 12, 2024



We present DreamBeast, a novel method based on score distillation sampling (SDS) for generating fantastical 3D animal assets composed of distinct parts. Existing SDS methods often struggle with this generation task due to a limited understanding of part-level semantics in text-to-image diffusion models. While recent diffusion models, such as Stable Diffusion 3, demonstrate a better part-level understanding, they are prohibitively slow and exhibit other common problems associated with single-view diffusion models. DreamBeast overcomes this limitation through a novel part-aware knowledge transfer mechanism. For each generated asset, we efficiently extract part-level knowledge from the Stable Diffusion 3 model into a 3D Part-Affinity implicit representation. This enables us to instantly generate Part-Affinity maps from arbitrary camera views, which we then use to modulate the guidance of a multi-view diffusion model during SDS to create 3D assets of fantastical animals. DreamBeast significantly enhances the quality of generated 3D creatures with user-specified part compositions while reducing computational overhead, as demonstrated by extensive quantitative and qualitative evaluations.
kNN-CLIP: Retrieval Enables Training-Free Segmentation on Continually Expanding Large Vocabularies
Apr 15, 2024



Rapid advancements in continual segmentation have yet to bridge the gap of scaling to large continually expanding vocabularies under compute-constrained scenarios. We discover that traditional continual training leads to catastrophic forgetting under compute constraints, unable to outperform zero-shot segmentation methods. We introduce a novel strategy for semantic and panoptic segmentation with zero forgetting, capable of adapting to continually growing vocabularies without the need for retraining or large memory costs. Our training-free approach, kNN-CLIP, leverages a database of instance embeddings to enable open-vocabulary segmentation approaches to continually expand their vocabulary on any given domain with a single-pass through data, while only storing embeddings minimizing both compute and memory costs. This method achieves state-of-the-art mIoU performance across large-vocabulary semantic and panoptic segmentation datasets. We hope kNN-CLIP represents a step forward in enabling more efficient and adaptable continual segmentation, paving the way for advances in real-world large-vocabulary continual segmentation methods.
CLIP as RNN: Segment Countless Visual Concepts without Training Endeavor
Dec 21, 2023



Existing open-vocabulary image segmentation methods require a fine-tuning step on mask annotations and/or image-text datasets. Mask labels are labor-intensive, which limits the number of categories in segmentation datasets. As a result, the open-vocabulary capacity of pre-trained VLMs is severely reduced after fine-tuning. However, without fine-tuning, VLMs trained under weak image-text supervision tend to make suboptimal mask predictions when there are text queries referring to non-existing concepts in the image. To alleviate these issues, we introduce a novel recurrent framework that progressively filters out irrelevant texts and enhances mask quality without training efforts. The recurrent unit is a two-stage segmenter built upon a VLM with frozen weights. Thus, our model retains the VLM's broad vocabulary space and strengthens its segmentation capability. Experimental results show that our method outperforms not only the training-free counterparts, but also those fine-tuned with millions of additional data samples, and sets new state-of-the-art records for both zero-shot semantic and referring image segmentation tasks. Specifically, we improve the current record by 28.8, 16.0, and 6.9 mIoU on Pascal VOC, COCO Object, and Pascal Context.
OxfordTVG-HIC: Can Machine Make Humorous Captions from Images?
Jul 21, 2023



This paper presents OxfordTVG-HIC (Humorous Image Captions), a large-scale dataset for humour generation and understanding. Humour is an abstract, subjective, and context-dependent cognitive construct involving several cognitive factors, making it a challenging task to generate and interpret. Hence, humour generation and understanding can serve as a new task for evaluating the ability of deep-learning methods to process abstract and subjective information. Due to the scarcity of data, humour-related generation tasks such as captioning remain under-explored. To address this gap, OxfordTVG-HIC offers approximately 2.9M image-text pairs with humour scores to train a generalizable humour captioning model. Contrary to existing captioning datasets, OxfordTVG-HIC features a wide range of emotional and semantic diversity resulting in out-of-context examples that are particularly conducive to generating humour. Moreover, OxfordTVG-HIC is curated devoid of offensive content. We also show how OxfordTVG-HIC can be leveraged for evaluating the humour of a generated text. Through explainability analysis of the trained models, we identify the visual and linguistic cues influential for evoking humour prediction (and generation). We observe qualitatively that these cues are aligned with the benign violation theory of humour in cognitive psychology.