 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Accuracy, Less Talk (HALT): Reliable LLMs through Capability-Aligned Finetuning
Jun 04, 2025Large Language Models (LLMs) currently respond to every prompt. However, they can produce incorrect answers when they lack knowledge or capability -- a problem known as hallucination. We instead propose post-training an LLM to generate content only when confident in its correctness and to otherwise (partially) abstain. Specifically, our method, HALT, produces capability-aligned post-training data that encodes what the model can and cannot reliably generate. We generate this data by splitting responses of the pretrained LLM into factual fragments (atomic statements or reasoning steps), and use ground truth information to identify incorrect fragments. We achieve capability-aligned finetuning responses by either removing incorrect fragments or replacing them with "Unsure from Here" -- according to a tunable threshold that allows practitioners to trade off response completeness and mean correctness of the response's fragments. We finetune four open-source models for biography writing, mathematics, coding, and medicine with HALT for three different trade-off thresholds. HALT effectively trades off response completeness for correctness, increasing the mean correctness of response fragments by 15% on average, while resulting in a 4% improvement in the F1 score (mean of completeness and correctness of the response) compared to the relevant baselines. By tuning HALT for highest correctness, we train a single reliable Llama3-70B model with correctness increased from 51% to 87% across all four domains while maintaining 53% of the response completeness achieved with standard finetuning.
Select2Plan: Training-Free ICL-Based Planning through VQA and Memory Retrieval
Nov 06, 2024This study explores the potential of off-the-shelf Vision-Language Models (VLMs) for high-level robot planning in the context of autonomous navigation. Indeed, while most of existing learning-based approaches for path planning require extensive task-specific training/fine-tuning, we demonstrate how such training can be avoided for most practical cases. To do this, we introduce Select2Plan (S2P), a novel training-free framework for high-level robot planning which completely eliminates the need for fine-tuning or specialised training. By leveraging structured Visual Question-Answering (VQA) and In-Context Learning (ICL), our approach drastically reduces the need for data collection, requiring a fraction of the task-specific data typically used by trained models, or even relying only on online data. Our method facilitates the effective use of a generally trained VLM in a flexible and cost-efficient way, and does not require additional sensing except for a simple monocular camera. We demonstrate its adaptability across various scene types, context sources, and sensing setups. We evaluate our approach in two distinct scenarios: traditional First-Person View (FPV) and infrastructure-driven Third-Person View (TPV) navigation, demonstrating the flexibility and simplicity of our method. Our technique significantly enhances the navigational capabilities of a baseline VLM of approximately 50% in TPV scenario, and is comparable to trained models in the FPV one, with as few as 20 demonstrations.
HelloFresh: LLM Evaluations on Streams of Real-World Human Editorial Actions across X Community Notes and Wikipedia edits
Jun 05, 2024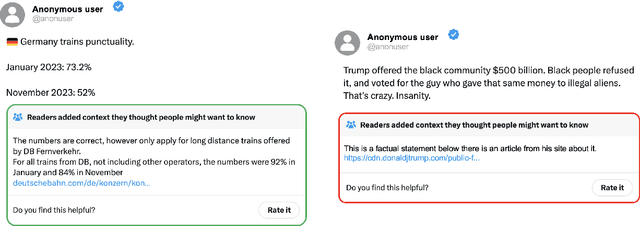


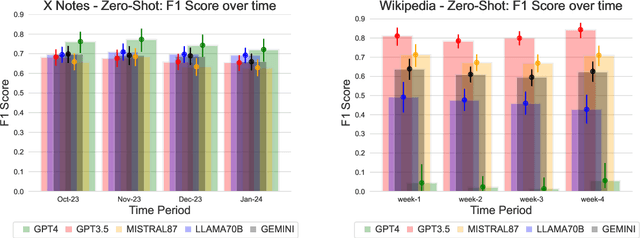
Benchmarks have been essential for driving progress in machine learning. A better understanding of LLM capabilities on real world tasks is vital for safe development. Designing adequate LLM benchmarks is challenging: Data from real-world tasks is hard to collect, public availability of static evaluation data results in test data contamination and benchmark overfitting, and periodically generating new evaluation data is tedious and may result in temporally inconsistent results. We introduce HelloFresh, based on continuous streams of real-world data generated by intrinsically motivated human labelers. It covers recent events from X (formerly Twitter) community notes and edits of Wikipedia pages, mitigating the risk of test data contamination and benchmark overfitting. Any X user can propose an X note to add additional context to a misleading post (formerly tweet); if the community classifies it as helpful, it is shown with the post. Similarly, Wikipedia relies on community-based consensus, allowing users to edit articles or revert edits made by other users. Verifying whether an X note is helpful or whether a Wikipedia edit should be accepted are hard tasks that require grounding by querying the web. We backtest state-of-the-art LLMs supplemented with simple web search access and find that HelloFresh yields a temporally consistent ranking. To enable continuous evaluation on HelloFresh, we host a public leaderboard and periodically updated evaluation data at https://tinyurl.com/hello-fresh-LLM.
Select to Perfect: Imitating desired behavior from large multi-agent data
May 06, 2024AI agents are commonly trained with large datasets of demonstrations of human behavior. However, not all behaviors are equally safe or desirable. Desired characteristics for an AI agent can be expressed by assigning desirability scores, which we assume are not assigned to individual behaviors but to collective trajectories. For example, in a dataset of vehicle interactions, these scores might relate to the number of incidents that occurred. We first assess the effect of each individual agent's behavior on the collective desirability score, e.g., assessing how likely an agent is to cause incidents. This allows us to selectively imitate agents with a positive effect, e.g., only imitating agents that are unlikely to cause incidents. To enable this, we propose the concept of an agent's Exchange Value, which quantifies an individual agent's contribution to the collective desirability score. The Exchange Value is the expected change in desirability score when substituting the agent for a randomly selected agent. We propose additional methods for estimating Exchange Values from real-world datasets, enabling us to learn desired imitation policies that outperform relevant baselines. The project website can be found at https://tinyurl.com/select-to-perfect.
Rethinking Out-of-Distribution Detection for Reinforcement Learning: Advancing Methods for Evaluation and Detection
Apr 10, 2024While reinforcement learning (RL) algorithms have been successfully applied across numerous sequential decision-making problems, their generalization to unforeseen testing environments remains a significant concern. In this paper, we study the problem of out-of-distribution (OOD) detection in RL, which focuses on identifying situations at test time that RL agents have not encountered in their training environments. We first propose a clarification of terminology for OOD detection in RL, which aligns it with the literature from other machine learning domains. We then present new benchmark scenarios for OOD detection, which introduce anomalies with temporal autocorrelation into different components of the agent-environment loop. We argue that such scenarios have been understudied in the current literature, despite their relevance to real-world situations. Confirming our theoretical predictions, our experimental results suggest that state-of-the-art OOD detectors are not able to identify such anomalies. To address this problem, we propose a novel method for OOD detection, which we call DEXTER (Detection via Extraction of Time Series Representations). By treating environment observations as time series data, DEXTER extracts salient time series features, and then leverages an ensemble of isolation forest algorithms to detect anomalies. We find that DEXTER can reliably identify anomalies across benchmark scenarios, exhibiting superior performance compared to both state-of-the-art OOD detectors and high-dimensional changepoint detectors adopted from statistics.
Extracting Reward Functions from Diffusion Models
Jun 01, 2023Diffusion models have achieved remarkable results in image generation, and have similarly been used to learn high-performing policies in sequential decision-making tasks. Decision-making diffusion models can be trained on lower-quality data, and then be steered with a reward function to generate near-optimal trajectories. We consider the problem of extracting a reward function by comparing a decision-making diffusion model that models low-reward behavior and one that models high-reward behavior; a setting related to inverse reinforcement learning. We first define the notion of a relative reward function of two diffusion models and show conditions under which it exists and is unique. We then devise a practical learning algorithm for extracting it by aligning the gradients of a reward function -- parametrized by a neural network -- to the difference in outputs of both diffusion models. Our method finds correct reward functions in navigation environments, and we demonstrate that steering the base model with the learned reward functions results in significantly increased performance in standard locomotion benchmarks. Finally, we demonstrate that our approach generalizes beyond sequential decision-making by learning a reward-like function from two large-scale image generation diffusion models. The extracted reward function successfully assigns lower rewards to harmful images.
Learn what matters: cross-domain imitation learning with task-relevant embeddings
Sep 24, 2022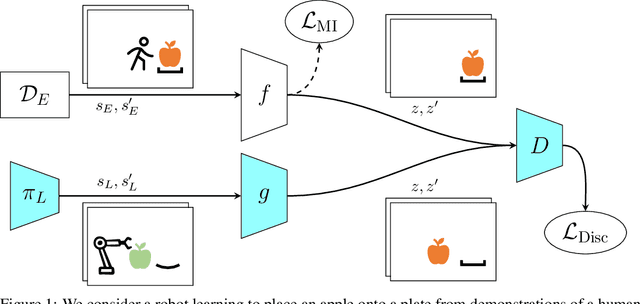


We study how an autonomous agent learns to perform a task from demonstrations in a different domain, such as a different environment or different agent. Such cross-domain imitation learning is required to, for example, train an artificial agent from demonstrations of a human expert. We propose a scalable framework that enables cross-domain imitation learning without access to additional demonstrations or further domain knowledge. We jointly train the learner agent's policy and learn a mapping between the learner and expert domains with adversarial training. We effect this by using a mutual information criterion to find an embedding of the expert's state space that contains task-relevant information and is invariant to domain specifics. This step significantly simplifies estimating the mapping between the learner and expert domains and hence facilitates end-to-end learning. We demonstrate successful transfer of policies between considerably different domains, without extra supervision such as additional demonstrations, and in situations where other methods fail.
Illusionary Attacks on Sequential Decision Makers and Countermeasures
Jul 20, 2022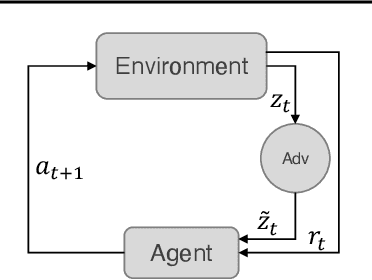
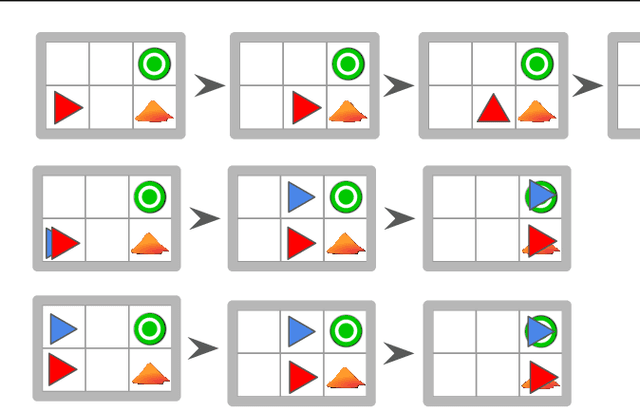
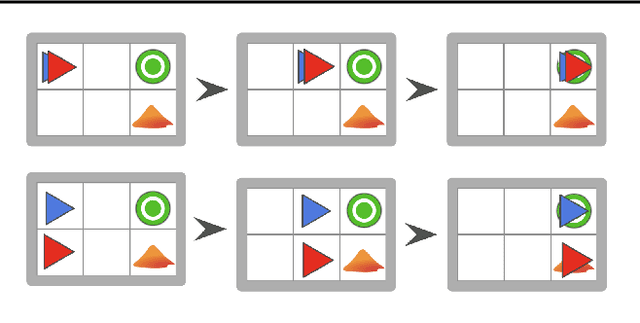
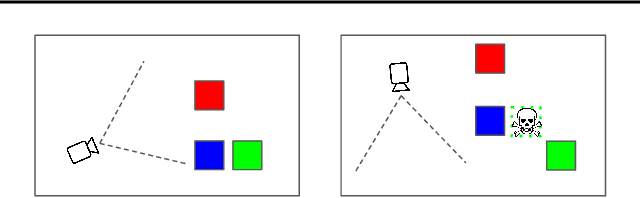
Autonomous intelligent agents deployed to the real-world need to be robust against adversarial attacks on sensory inputs. Existing work in reinforcement learning focuses on minimum-norm perturbation attacks, which were originally introduced to mimic a notion of perceptual invariance in computer vision. In this paper, we note that such minimum-norm perturbation attacks can be trivially detected by victim agents, as these result in observation sequences that are not consistent with the victim agent's actions. Furthermore, many real-world agents, such as physical robots, commonly operate under human supervisors, which are not susceptible to such perturbation attacks. As a result, we propose to instead focus on illusionary attacks, a novel form of attack that is consistent with the world model of the victim agent. We provide a formal definition of this novel attack framework, explore its characteristics under a variety of conditions, and conclude that agents must seek realism feedback to be robust to illusionary attacks.
Learning Altruistic Behaviours in Reinforcement Learning without External Rewards
Jul 22, 2021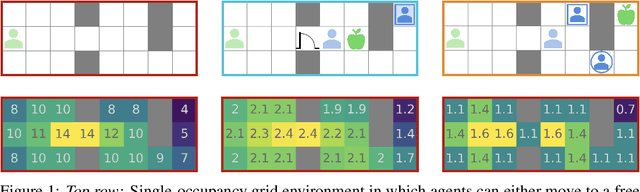
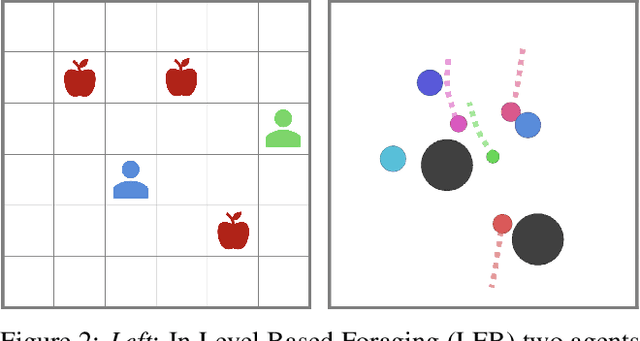
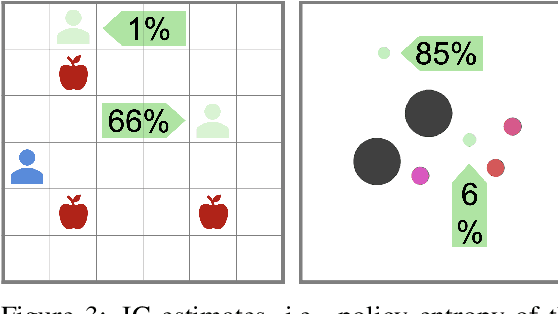

Can artificial agents learn to assist others in achieving their goals without knowing what those goals are? Generic reinforcement learning agents could be trained to behave altruistically towards others by rewarding them for altruistic behaviour, i.e., rewarding them for benefiting other agents in a given situation. Such an approach assumes that other agents' goals are known so that the altruistic agent can cooperate in achieving those goals. However, explicit knowledge of other agents' goals is often difficult to acquire. Even assuming such knowledge to be given, training of altruistic agents would require manually-tuned external rewards for each new environment. Thus, it is beneficial to develop agents that do not depend on external supervision and can learn altruistic behaviour in a task-agnostic manner. Assuming that other agents rationally pursue their goals, we hypothesize that giving them more choices will allow them to pursue those goals better. Some concrete examples include opening a door for others or safeguarding them to pursue their objectives without interference. We formalize this concept and propose an altruistic agent that learns to increase the choices another agent has by maximizing the number of states that the other agent can reach in its future. We evaluate our approach on three different multi-agent environments where another agent's success depends on the altruistic agent's behaviour. Finally, we show that our unsupervised agents can perform comparably to agents explicitly trained to work cooperatively. In some cases, our agents can even outperform the supervised ones.