 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect to Perfect: Imitating desired behavior from large multi-agent data
May 06, 2024AI agents are commonly trained with large datasets of demonstrations of human behavior. However, not all behaviors are equally safe or desirable. Desired characteristics for an AI agent can be expressed by assigning desirability scores, which we assume are not assigned to individual behaviors but to collective trajectories. For example, in a dataset of vehicle interactions, these scores might relate to the number of incidents that occurred. We first assess the effect of each individual agent's behavior on the collective desirability score, e.g., assessing how likely an agent is to cause incidents. This allows us to selectively imitate agents with a positive effect, e.g., only imitating agents that are unlikely to cause incidents. To enable this, we propose the concept of an agent's Exchange Value, which quantifies an individual agent's contribution to the collective desirability score. The Exchange Value is the expected change in desirability score when substituting the agent for a randomly selected agent. We propose additional methods for estimating Exchange Values from real-world datasets, enabling us to learn desired imitation policies that outperform relevant baselines. The project website can be found at https://tinyurl.com/select-to-perfect.
Space-Time Crop & Attend: Improving Cross-modal Video Representation Learning
Mar 18, 2021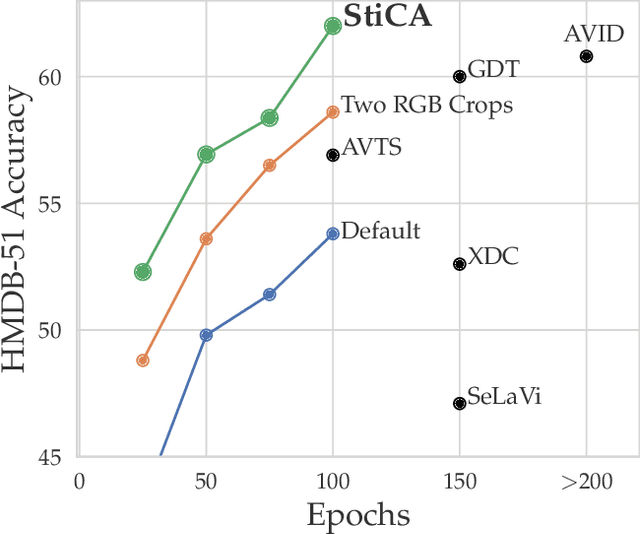
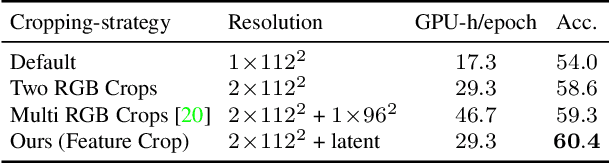
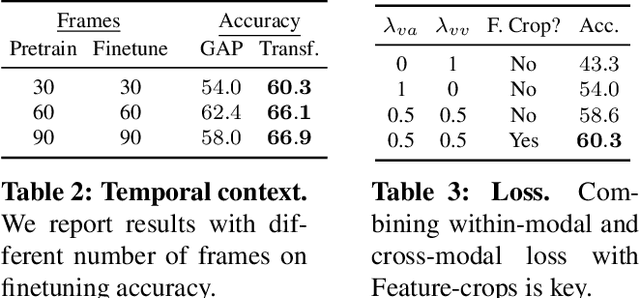
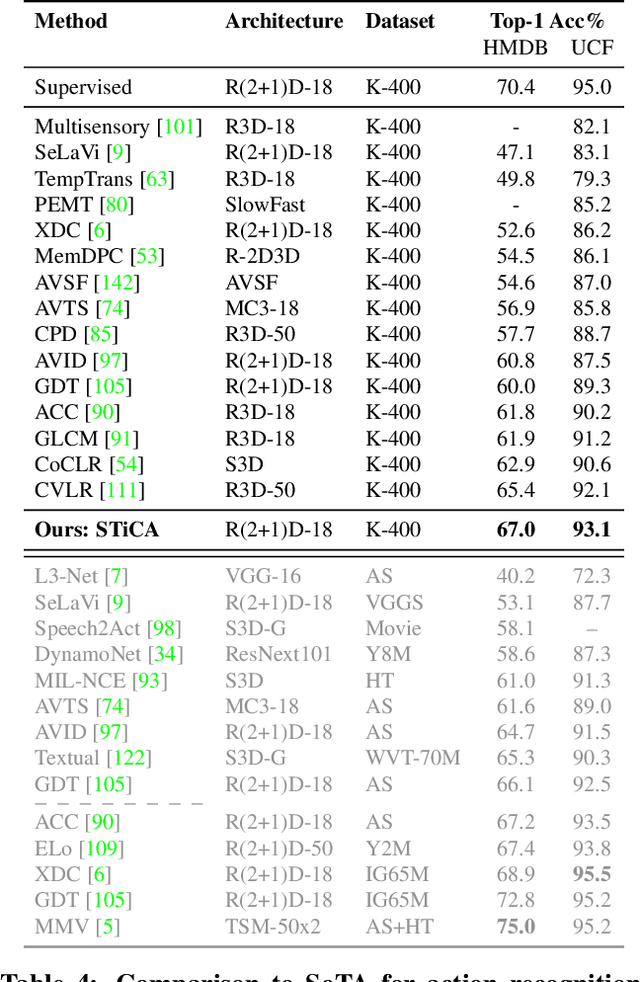
The quality of the image representations obtained from self-supervised learning depends strongly on the type of data augmentations used in the learning formulation. Recent papers have ported these methods from still images to videos and found that leveraging both audio and video signals yields strong gains; however, they did not find that spatial augmentations such as cropping, which are very important for still images, work as well for videos. In this paper, we improve these formulations in two ways unique to the spatio-temporal aspect of videos. First, for space, we show that spatial augmentations such as cropping do work well for videos too, but that previous implementations, due to the high processing and memory cost, could not do this at a scale sufficient for it to work well. To address this issue, we first introduce Feature Crop, a method to simulate such augmentations much more efficiently directly in feature space. Second, we show that as opposed to naive average pooling, the use of transformer-based attention improves performance significantly, and is well suited for processing feature crops. Combining both of our discoveries into a new method, Space-time Crop & Attend (STiCA) we achieve state-of-the-art performance across multiple video-representation learning benchmarks. In particular, we achieve new state-of-the-art accuracies of 67.0% on HMDB-51 and 93.1% on UCF-101 when pre-training on Kinetics-400.
Automatic Recall Machines: Internal Replay, Continual Learning and the Brain
Jul 15, 2020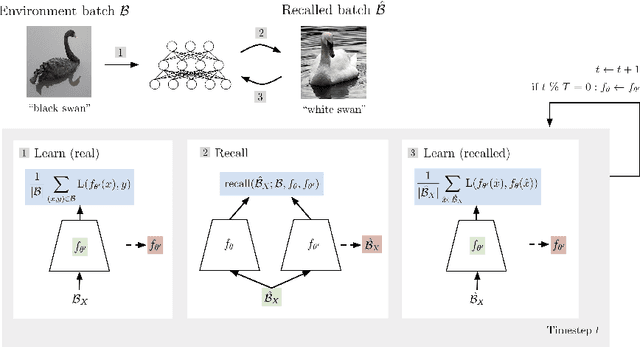
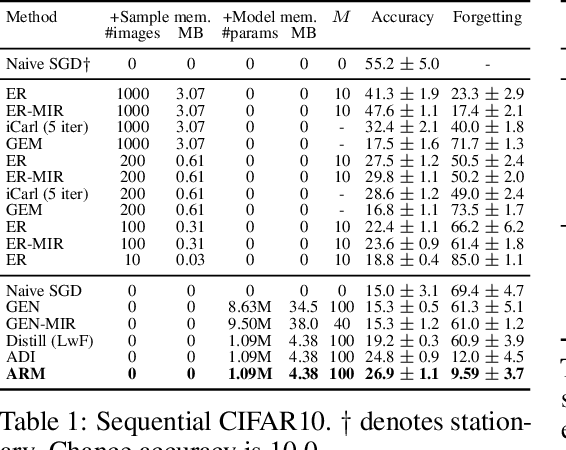

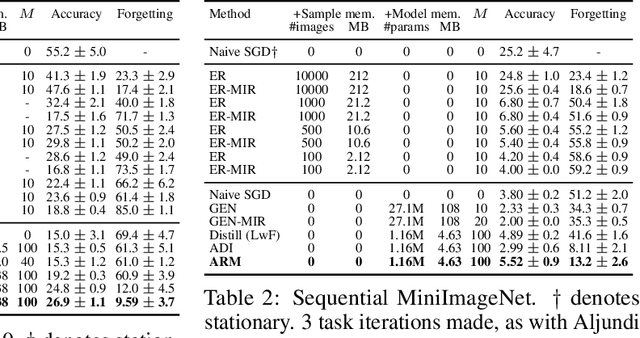
Replay in neural networks involves training on sequential data with memorized samples, which counteracts forgetting of previous behavior caused by non-stationarity. We present a method where these auxiliary samples are generated on the fly, given only the model that is being trained for the assessed objective, without extraneous buffers or generator networks. Instead the implicit memory of learned samples within the assessed model itself is exploited. Furthermore, whereas existing work focuses on reinforcing the full seen data distribution, we show that optimizing for not forgetting calls for the generation of samples that are specialized to each real training batch, which is more efficient and scalable. We consider high-level parallels with the brain, notably the use of a single model for inference and recall, the dependency of recalled samples on the current environment batch, top-down modulation of activations and learning, abstract recall, and the dependency between the degree to which a task is learned and the degree to which it is recalled. These characteristics emerge naturally from the method without being controlled for.
Deep Industrial Espionage
Apr 01, 2019



The theory of deep learning is now considered largely solved, and is well understood by researchers and influencers alike. To maintain our relevance, we therefore seek to apply our skills to under-explored, lucrative applications of this technology. To this end, we propose and Deep Industrial Espionage, an efficient end-to-end framework for industrial information propagation and productisation. Specifically, given a single image of a product or service, we aim to reverse-engineer, rebrand and distribute a copycat of the product at a profitable price-point to consumers in an emerging market---all within in a single forward pass of a Neural Network. Differently from prior work in machine perception which has been restricted to classifying, detecting and reasoning about object instances, our method offers tangible business value in a wide range of corporate settings. Our approach draws heavily on a promising recent arxiv paper until its original authors' names can no longer be read (we use felt tip pen). We then rephrase the anonymised paper, add the word "novel" to the title, and submit it a prestigious, closed-access espionage journal who assure us that someday, we will be entitled to some fraction of their extortionate readership fees.