 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2D: Learning to find good correspondences for image matching and manipulation
Jul 16, 2020
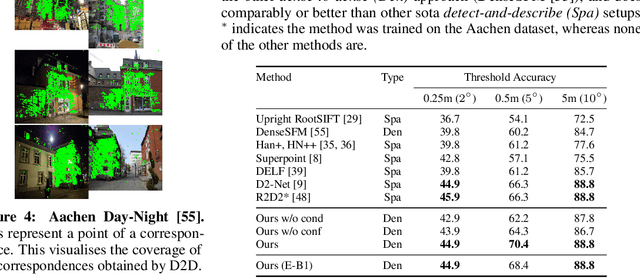
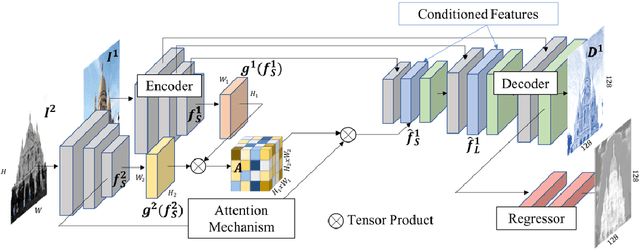
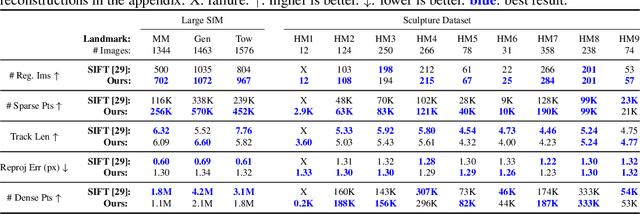
We propose a new approach to determining correspondences between image pairs under large changes in illumination, viewpoint, context, and material. While most approaches seek to extract a set of reliably detectable regions in each image which are then compared (sparse-to-sparse) using increasingly complicated or specialized pipelines, we propose a simple approach for matching all points between the images (dense-to-dense) and subsequently selecting the best matches. The two key parts of our approach are: (i) to condition the learned features on both images, and (ii) to learn a distinctiveness score which is used to choose the best matches at test time. We demonstrate that our model can be used to achieve state of the art or competitive results on a wide range of tasks: local matching, camera localization, 3D reconstruction, and image stylization.
RELATE: Physically Plausible Multi-Object Scene Synthesis Using Structured Latent Spaces
Jul 02, 2020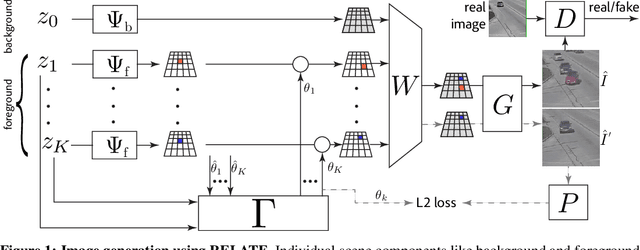

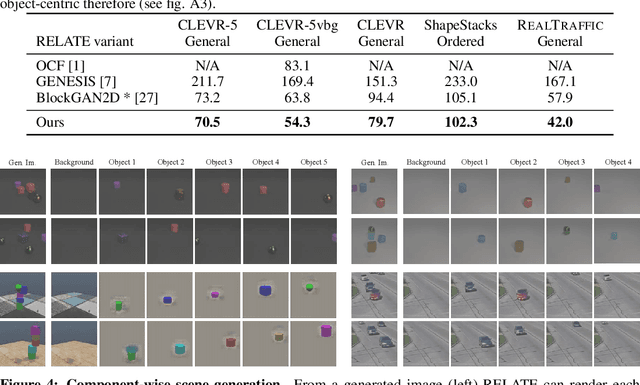

We present RELATE, a model that learns to generate physically plausible scenes and videos of multiple interacting objects. Similar to other generative approaches, RELATE is trained end-to-end on raw, unlabeled data. RELATE combines an object-centric GAN formulation with a model that explicitly accounts for correlations between individual objects. This allows the model to generate realistic scenes and videos from a physically-interpretable parameterization. Furthermore, we show that modeling the object correlation is necessary to learn to disentangle object positions and identity. We find that RELATE is also amenable to physically realistic scene editing and that it significantly outperforms prior art in object-centric scene generation in both synthetic (CLEVR, ShapeStacks) and real-world data (street traffic scenes). In addition, in contrast to state-of-the-art methods in object-centric generative modeling, RELATE also extends naturally to dynamic scenes and generates videos of high visual fidelity
LSD-C: Linearly Separable Deep Clusters
Jun 17, 2020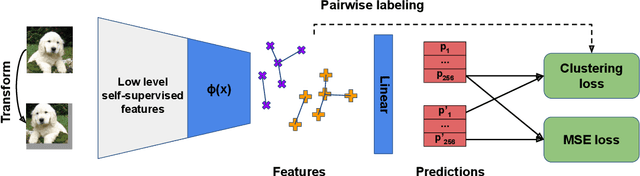



We present LSD-C, a novel method to identify clusters in an unlabeled dataset. Our algorithm first establishes pairwise connections in the feature space between the samples of the minibatch based on a similarity metric. Then it regroups in clusters the connected samples and enforces a linear separation between clusters. This is achieved by using the pairwise connections as targets together with a binary cross-entropy loss on the predictions that the associated pairs of samples belong to the same cluster. This way, the feature representation of the network will evolve such that similar samples in this feature space will belong to the same linearly separated cluster. Our method draws inspiration from recent semi-supervised learning practice and proposes to combine our clustering algorithm with self-supervised pretraining and strong data augmentation. We show that our approach significantly outperforms competitors on popular public image benchmarks including CIFAR 10/100, STL 10 and MNIST, as well as the document classification dataset Reuters 10K.
Automatically Discovering and Learning New Visual Categories with Ranking Statistics
Feb 13, 2020
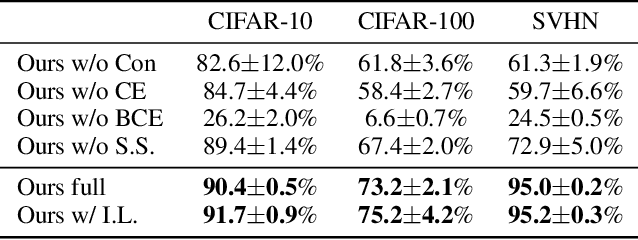

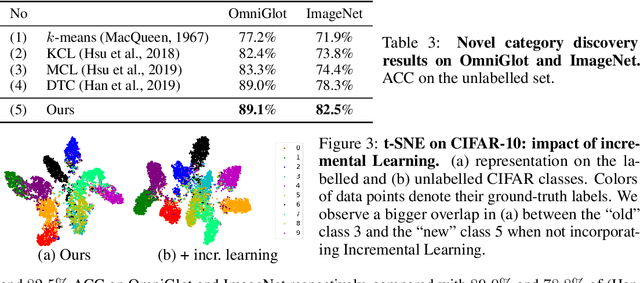
We tackle the problem of discovering novel classes in an image collection given labelled examples of other classes. This setting is similar to semi-supervised learning, but significantly harder because there are no labelled examples for the new classes. The challenge, then, is to leverage the information contained in the labelled images in order to learn a general-purpose clustering model and use the latter to identify the new classes in the unlabelled data. In this work we address this problem by combining three ideas: (1) we suggest that the common approach of bootstrapping an image representation using the labeled data only introduces an unwanted bias, and that this can be avoided by using self-supervised learning to train the representation from scratch on the union of labelled and unlabelled data; (2) we use rank statistics to transfer the model's knowledge of the labelled classes to the problem of clustering the unlabelled images; and, (3) we train the data representation by optimizing a joint objective function on the labelled and unlabelled subsets of the data, improving both the supervised classification of the labelled data, and the clustering of the unlabelled data. We evaluate our approach on standard classification benchmarks and outperform current methods for novel category discovery by a significant margin.
Semi-Supervised Learning with Scarce Annotations
May 21, 2019

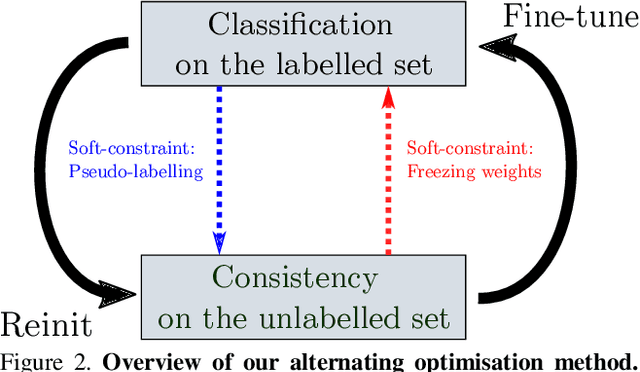

While semi-supervised learning (SSL) algorithms provide an efficient way to make use of both labelled and unlabelled data, they generally struggle when the number of annotated samples is very small. In this work, we consider the problem of SSL multi-class classification with very few labelled instances. We introduce two key ideas. The first is a simple but effective one: we leverage the power of transfer learning among different tasks and self-supervision to initialize a good representation of the data without making use of any label. The second idea is a new algorithm for SSL that can exploit well such a pre-trained representation. The algorithm works by alternating two phases, one fitting the labelled points and one fitting the unlabelled ones, with carefully-controlled information flow between them. The benefits are greatly reducing overfitting of the labelled data and avoiding issue with balancing labelled and unlabelled losses during training. We show empirically that this method can successfully train competitive models with as few as 10 labelled data points per class. More in general, we show that the idea of bootstrapping features using self-supervised learning always improves SSL on standard benchmarks. We show that our algorithm works increasingly well compared to other methods when refining from other tasks or datasets.
Deep Industrial Espionage
Apr 01, 2019



The theory of deep learning is now considered largely solved, and is well understood by researchers and influencers alike. To maintain our relevance, we therefore seek to apply our skills to under-explored, lucrative applications of this technology. To this end, we propose and Deep Industrial Espionage, an efficient end-to-end framework for industrial information propagation and productisation. Specifically, given a single image of a product or service, we aim to reverse-engineer, rebrand and distribute a copycat of the product at a profitable price-point to consumers in an emerging market---all within in a single forward pass of a Neural Network. Differently from prior work in machine perception which has been restricted to classifying, detecting and reasoning about object instances, our method offers tangible business value in a wide range of corporate settings. Our approach draws heavily on a promising recent arxiv paper until its original authors' names can no longer be read (we use felt tip pen). We then rephrase the anonymised paper, add the word "novel" to the title, and submit it a prestigious, closed-access espionage journal who assure us that someday, we will be entitled to some fraction of their extortionate readership fees.
Small steps and giant leaps: Minimal Newton solvers for Deep Learning
May 21, 2018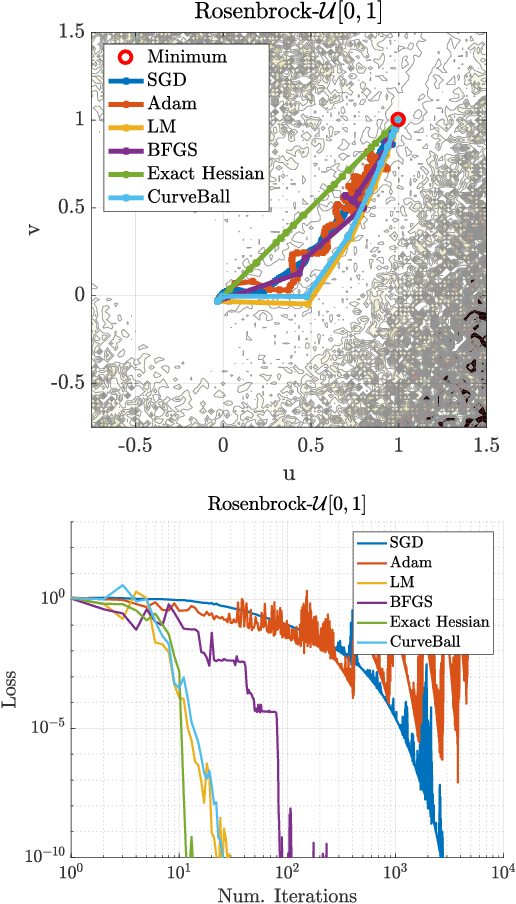

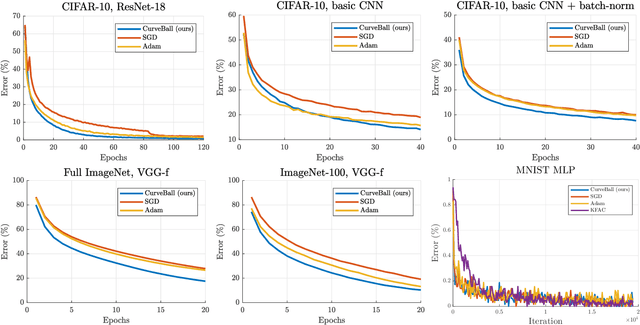
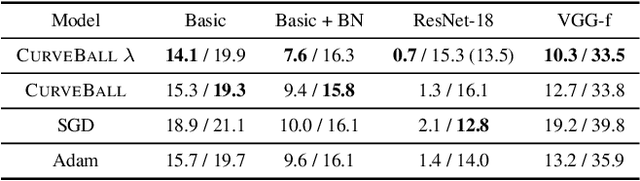
We propose a fast second-order method that can be used as a drop-in replacement for current deep learning solvers. Compared to stochastic gradient descent (SGD), it only requires two additional forward-mode automatic differentiation operations per iteration, which has a computational cost comparable to two standard forward passes and is easy to implement. Our method addresses long-standing issues with current second-order solvers, which invert an approximate Hessian matrix every iteration exactly or by conjugate-gradient methods, a procedure that is both costly and sensitive to noise. Instead, we propose to keep a single estimate of the gradient projected by the inverse Hessian matrix, and update it once per iteration. This estimate has the same size and is similar to the momentum variable that is commonly used in SGD. No estimate of the Hessian is maintained. We first validate our method, called CurveBall, on small problems with known closed-form solutions (noisy Rosenbrock function and degenerate 2-layer linear networks), where current deep learning solvers seem to struggle. We then train several large models on CIFAR and ImageNet, including ResNet and VGG-f networks, where we demonstrate faster convergence with no hyperparameter tuning. Code is available.
Unsupervised Intuitive Physics from Visual Observations
May 14, 2018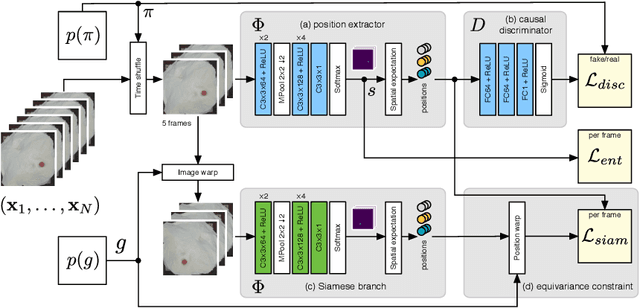
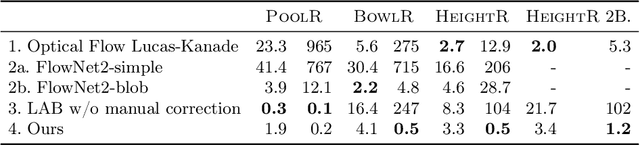
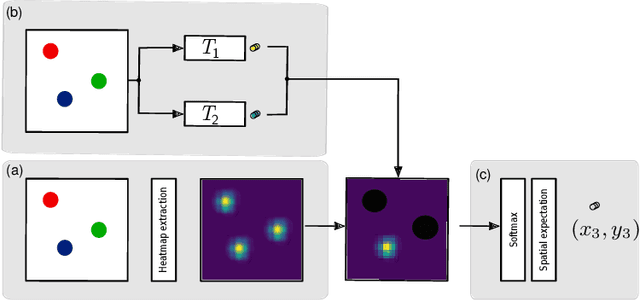
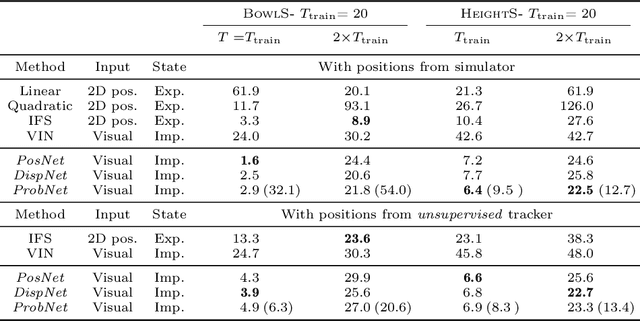
While learning models of intuitive physics is an increasingly active area of research, current approaches still fall short of natural intelligences in one important regard: they require external supervision, such as explicit access to physical states, at training and sometimes even at test times. Some authors have relaxed such requirements by supplementing the model with an handcrafted physical simulator. Still, the resulting methods are unable to automatically learn new complex environments and to understand physical interactions within them. In this work, we demonstrated for the first time learning such predictors directly from raw visual observations and without relying on simulators. We do so in two steps: first, we learn to track mechanically-salient objects in videos using causality and equivariance, two unsupervised learning principles that do not require auto-encoding. Second, we demonstrate that the extracted positions are sufficient to successfully train visual motion predictors that can take the underlying environment into account. We validate our predictors on synthetic datasets; then, we introduce a new dataset, ROLL4REAL, consisting of real objects rolling on complex terrains (pool table, elliptical bowl, and random height-field). We show that in all such cases it is possible to learn reliable extrapolators of the object trajectories from raw videos alone, without any form of external supervision and with no more prior knowledge than the choice of a convolutional neural network architecture.
Taking Visual Motion Prediction To New Heightfields
Dec 22, 2017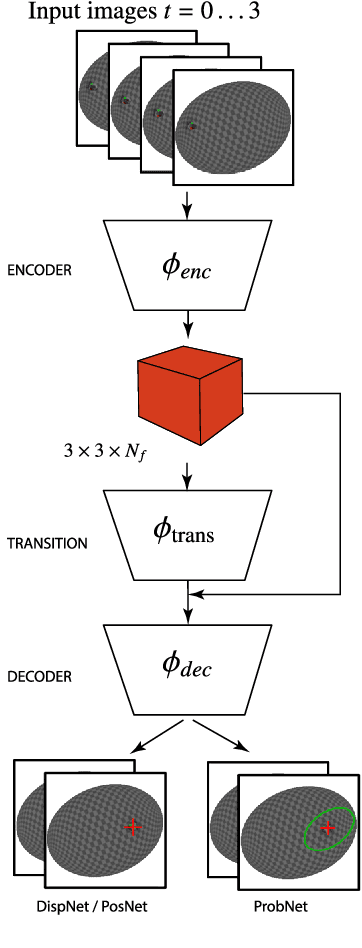

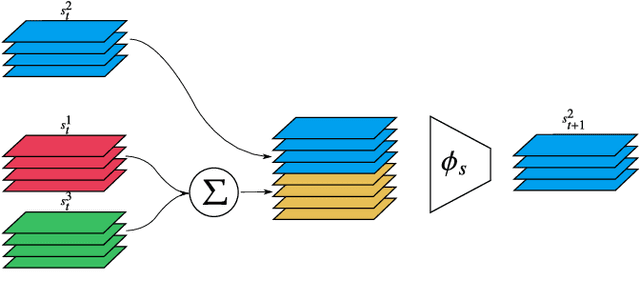
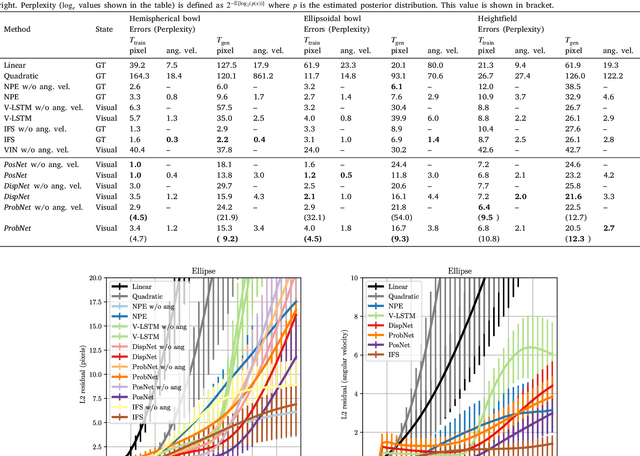
While the basic laws of Newtonian mechanics are well understood, explaining a physical scenario still requires manually modeling the problem with suitable equations and estimating the associated parameters. In order to be able to leverage the approximation capabilities of artificial intelligence techniques in such physics related contexts, researchers have handcrafted the relevant states, and then used neural networks to learn the state transitions using simulation runs as training data. Unfortunately, such approaches are unsuited for modeling complex real-world scenarios, where manually authoring relevant state spaces tend to be tedious and challenging. In this work, we investigate if neural networks can implicitly learn physical states of real-world mechanical processes only based on visual data while internally modeling non-homogeneous environment and in the process enable long-term physical extrapolation. We develop a recurrent neural network architecture for this task and also characterize resultant uncertainties in the form of evolving variance estimates. We evaluate our setup to extrapolate motion of rolling ball(s) on bowls of varying shape and orientation, and on arbitrary heightfields using only images as input. We report significant improvements over existing image-based methods both in terms of accuracy of predictions and complexity of scenarios; and report competitive performance with approaches that, unlike us, assume access to internal physical states.
Learning A Physical Long-term Predictor
Mar 01, 2017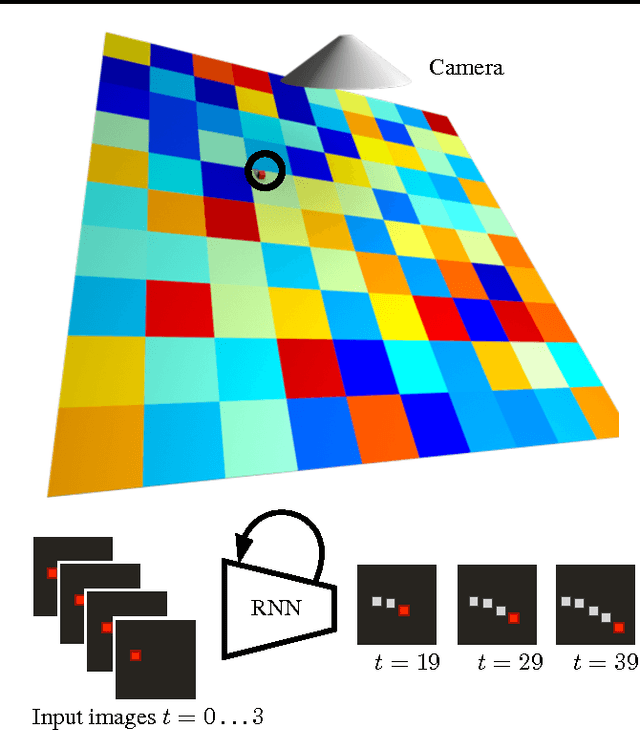
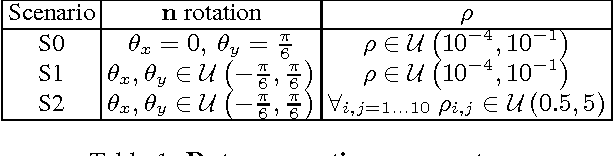
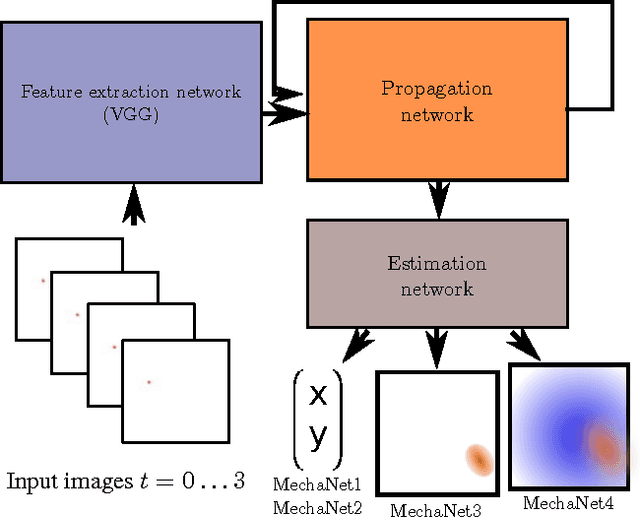
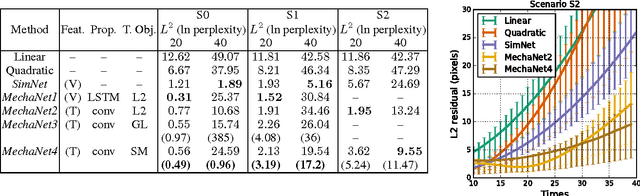
Evolution has resulted in highly developed abilities in many natural intelligences to quickly and accurately predict mechanical phenomena. Humans have successfully developed laws of physics to abstract and model such mechanical phenomena. In the context of artificial intelligence, a recent line of work has focused on estimating physical parameters based on sensory data and use them in physical simulators to make long-term predictions. In contrast, we investigate the effectiveness of a single neural network for end-to-end long-term prediction of mechanical phenomena. Based on extensive evaluation, we demonstrate that such networks can outperform alternate approaches having even access to ground-truth physical simulators, especially when some physical parameters are unobserved or not known a-priori. Further, our network outputs a distribution of outcomes to capture the inherent uncertainty in the data. Our approach demonstrates for the first time the possibility of making actionable long-term predictions from sensor data without requiring to explicitly model the underlying physical laws.