 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Intuitive Physics from Visual Observations
Paper and Code
May 14, 2018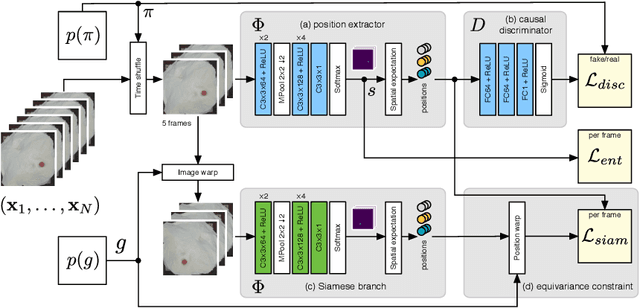
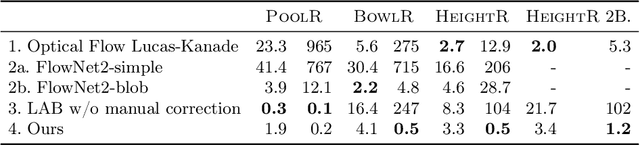
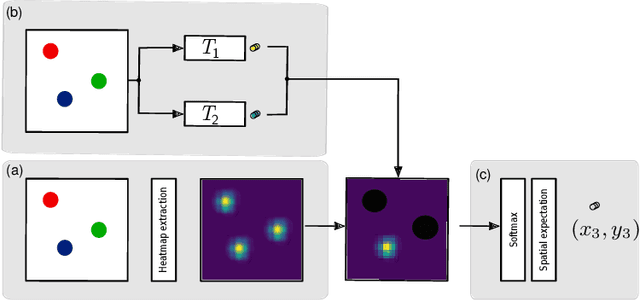
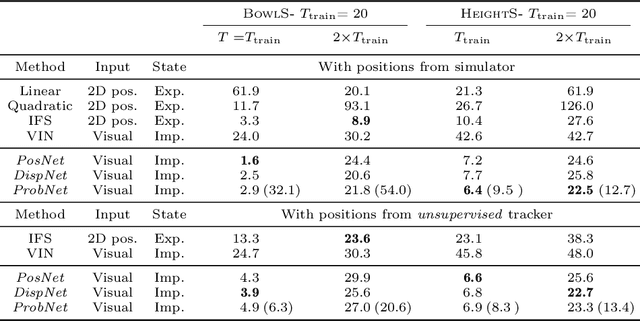
While learning models of intuitive physics is an increasingly active area of research, current approaches still fall short of natural intelligences in one important regard: they require external supervision, such as explicit access to physical states, at training and sometimes even at test times. Some authors have relaxed such requirements by supplementing the model with an handcrafted physical simulator. Still, the resulting methods are unable to automatically learn new complex environments and to understand physical interactions within them. In this work, we demonstrated for the first time learning such predictors directly from raw visual observations and without relying on simulators. We do so in two steps: first, we learn to track mechanically-salient objects in videos using causality and equivariance, two unsupervised learning principles that do not require auto-encoding. Second, we demonstrate that the extracted positions are sufficient to successfully train visual motion predictors that can take the underlying environment into account. We validate our predictors on synthetic datasets; then, we introduce a new dataset, ROLL4REAL, consisting of real objects rolling on complex terrains (pool table, elliptical bowl, and random height-field). We show that in all such cases it is possible to learn reliable extrapolators of the object trajectories from raw videos alone, without any form of external supervision and with no more prior knowledge than the choice of a convolutional neural network architecture.