 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Voxel Dynamics: Learning Implicit 3D Physics via Volumetric Feature Advection
Jun 24, 2026We present a self-supervised framework for learning implicit 3D physical dynamics directly from video-derived supervisory signals. While current generative video models achieve high visual fidelity, they lack a 3D geometric foundation, often resulting in physical inconsistencies and a failure to maintain object permanence. We address this by shifting the predictive bottleneck from 2D image space to a `lifted' 3D Volumetric Latent Space. Our method unprojects semantic features from a Video Joint-Embedding Predictive Architecture (V-JEPA) into a voxelized grid, grounded by monocular depth priors. This lifting enables a Volumetric Feature Advection to learn an action-conditioned transition operator that treats physics as a spatio-temporal state advection problem, i.e., learn implicit 3D physics. Unlike state-of-the-art hybrid models that rely on explicit classical simulators for training and/or inference, our architecture tracks material states implicitly within high-dimensional V-JEPA features. This allows for the emergent simulation of heterogeneous phenomena (e.g., rigid body motion in fluid flow) within a single, unified pipeline. Supervised solely via end-to-end video-derived signal plus action conditions, without access to physics engine internal states, labels, or surrogate models, our model demonstrates good long-term structural stability and physical plausibility on multiple benchmarks (CLEVERER, PhysInOne, PhysGaia). We believe that this work opens a scalable pathway toward general-purpose dynamic world models that internalize the 3D invariants of the physical world solely through passive observation of monocular videos.
Blended Chart Surfaces: A Seamless Explicit Representation for Smooth Surface Fitting
Jun 16, 2026A surface representation suitable for geometry processing should be compact and explicit, provide global smoothness guarantees, support a wide range of surface topologies, and offer reliable access to differential quantities such as normals and surface energies, while remaining compatible with modern differentiable optimization. Existing neural representations typically sacrifice one or more of these properties: implicit fields typically require iso-surfacing for downstream use, while explicit neural maps are constrained by canonical-domain parametrizations or exhibit seam artifacts between local charts. We introduce Blended Chart Surfaces, a compact, network-free, explicit representation that is smooth by construction and anchored to user-provided topology. Given a coarse proxy mesh encoding the intended surface topology and approximate geometry, Blended Chart Surfaces jointly optimize for a polynomial map at each proxy vertex using an off-the-shelf optimizer to fit to an implicit target shape, avoiding the need for an input parametrization. Neighboring maps are fused using a smooth 'one-ring coordinate' blending scheme, decoupling topology and coarse geometry (carried by the proxy) from geometric details (carried by the local patches). The surface is globally smooth, fully differentiable, and enables stable evaluation of derivatives, making differential quantities and surface energies directly accessible. Additionally, our construction is equivariant to rigid motions and scaling of the proxy mesh. We evaluate Blended Chart Surfaces on various topologies and geometric complexity, and compare against explicit alternatives including interpolating-function baselines and mesh-displacement MLPs. Across these, Blended Chart Surfaces achieve a favorable trade-off among compactness, simplicity, access to differential quantities, and expressivity while remaining smooth across patch boundaries.
Learning to Solve PDEs on Neural Shape Representations
Dec 24, 2025



Solving partial differential equations (PDEs) on shapes underpins many shape analysis and engineering tasks; yet, prevailing PDE solvers operate on polygonal/triangle meshes while modern 3D assets increasingly live as neural representations. This mismatch leaves no suitable method to solve surface PDEs directly within the neural domain, forcing explicit mesh extraction or per-instance residual training, preventing end-to-end workflows. We present a novel, mesh-free formulation that learns a local update operator conditioned on neural (local) shape attributes, enabling surface PDEs to be solved directly where the (neural) data lives. The operator integrates naturally with prevalent neural surface representations, is trained once on a single representative shape, and generalizes across shape and topology variations, enabling accurate, fast inference without explicit meshing or per-instance optimization while preserving differentiability. Across analytic benchmarks (heat equation and Poisson solve on sphere) and real neural assets across different representations, our method slightly outperforms CPM while remaining reasonably close to FEM, and, to our knowledge, delivers the first end-to-end pipeline that solves surface PDEs on both neural and classical surface representations. Code will be released on acceptance.
On Unifying Video Generation and Camera Pose Estimation
Jan 02, 2025



Inspired by the emergent 3D capabilities in image generators, we explore whether video generators similarly exhibit 3D awareness. Using structure-from-motion (SfM) as a benchmark for 3D tasks, we investigate if intermediate features from OpenSora, a video generation model, can support camera pose estimation. We first examine native 3D awareness in video generation features by routing raw intermediate outputs to SfM-prediction modules like DUSt3R. Then, we explore the impact of fine-tuning on camera pose estimation to enhance 3D awareness. Results indicate that while video generator features have limited inherent 3D awareness, task-specific supervision significantly boosts their accuracy for camera pose estimation, resulting in competitive performance. The proposed unified model, named JOG3R, produces camera pose estimates with competitive quality without degrading video generation quality.
Track4Gen: Teaching Video Diffusion Models to Track Points Improves Video Generation
Dec 10, 2024While recent foundational video generators produce visually rich output, they still struggle with appearance drift, where objects gradually degrade or change inconsistently across frames, breaking visual coherence. We hypothesize that this is because there is no explicit supervision in terms of spatial tracking at the feature level. We propose Track4Gen, a spatially aware video generator that combines video diffusion loss with point tracking across frames, providing enhanced spatial supervision on the diffusion features. Track4Gen merges the video generation and point tracking tasks into a single network by making minimal changes to existing video generation architectures. Using Stable Video Diffusion as a backbone, Track4Gen demonstrates that it is possible to unify video generation and point tracking, which are typically handled as separate tasks. Our extensive evaluations show that Track4Gen effectively reduces appearance drift, resulting in temporally stable and visually coherent video generation. Project page: hyeonho99.github.io/track4gen
Diffusion Handles: Enabling 3D Edits for Diffusion Models by Lifting Activations to 3D
Dec 06, 2023



Diffusion Handles is a novel approach to enabling 3D object edits on diffusion images. We accomplish these edits using existing pre-trained diffusion models, and 2D image depth estimation, without any fine-tuning or 3D object retrieval. The edited results remain plausible, photo-real, and preserve object identity. Diffusion Handles address a critically missing facet of generative image based creative design, and significantly advance the state-of-the-art in generative image editing. Our key insight is to lift diffusion activations for an object to 3D using a proxy depth, 3D-transform the depth and associated activations, and project them back to image space. The diffusion process applied to the manipulated activations with identity control, produces plausible edited images showing complex 3D occlusion and lighting effects. We evaluate Diffusion Handles: quantitatively, on a large synthetic data benchmark; and qualitatively by a user study, showing our output to be more plausible, and better than prior art at both, 3D editing and identity control. Project Webpage: https://diffusionhandles.github.io/
CADTalk: An Algorithm and Benchmark for Semantic Commenting of CAD Programs
Nov 30, 2023



CAD programs are a popular way to compactly encode shapes as a sequence of operations that are easy to parametrically modify. However, without sufficient semantic comments and structure, such programs can be challenging to understand, let alone modify. We introduce the problem of semantic commenting CAD programs, wherein the goal is to segment the input program into code blocks corresponding to semantically meaningful shape parts and assign a semantic label to each block. We solve the problem by combining program parsing with visual-semantic analysis afforded by recent advances in foundational language and vision models. Specifically, by executing the input programs, we create shapes, which we use to generate conditional photorealistic images to make use of semantic annotators for such images. We then distill the information across the images and link back to the original programs to semantically comment on them. Additionally, we collected and annotated a benchmark dataset, CADTalk, consisting of 5,280 machine-made programs and 45 human-made programs with ground truth semantic comments to foster future research. We extensively evaluated our approach, compared to a GPT-based baseline approach, and an open-set shape segmentation baseline, i.e., PartSLIP, and reported an 83.24% accuracy on the new CADTalk dataset. Project page: https://enigma-li.github.io/CADTalk/.
HOLODIFFUSION: Training a 3D Diffusion Model using 2D Images
Mar 29, 2023Diffusion models have emerged as the best approach for generative modeling of 2D images. Part of their success is due to the possibility of training them on millions if not billions of images with a stable learning objective. However, extending these models to 3D remains difficult for two reasons. First, finding a large quantity of 3D training data is much more complex than for 2D images. Second, while it is conceptually trivial to extend the models to operate on 3D rather than 2D grids, the associated cubic growth in memory and compute complexity makes this infeasible. We address the first challenge by introducing a new diffusion setup that can be trained, end-to-end, with only posed 2D images for supervision; and the second challenge by proposing an image formation model that decouples model memory from spatial memory. We evaluate our method on real-world data, using the CO3D dataset which has not been used to train 3D generative models before. We show that our diffusion models are scalable, train robustly, and are competitive in terms of sample quality and fidelity to existing approaches for 3D generative modeling.
3inGAN: Learning a 3D Generative Model from Images of a Self-similar Scene
Nov 27, 2022We introduce 3inGAN, an unconditional 3D generative model trained from 2D images of a single self-similar 3D scene. Such a model can be used to produce 3D "remixes" of a given scene, by mapping spatial latent codes into a 3D volumetric representation, which can subsequently be rendered from arbitrary views using physically based volume rendering. By construction, the generated scenes remain view-consistent across arbitrary camera configurations, without any flickering or spatio-temporal artifacts. During training, we employ a combination of 2D, obtained through differentiable volume tracing, and 3D Generative Adversarial Network (GAN) losses, across multiple scales, enforcing realism on both its 3D structure and the 2D renderings. We show results on semi-stochastic scenes of varying scale and complexity, obtained from real and synthetic sources. We demonstrate, for the first time, the feasibility of learning plausible view-consistent 3D scene variations from a single exemplar scene and provide qualitative and quantitative comparisons against recent related methods.
COFS: Controllable Furniture layout Synthesis
May 29, 2022


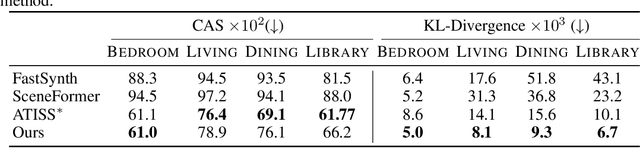
Scalable generation of furniture layouts is essential for many applications in virtual reality, augmented reality, game development and synthetic data generation. Many existing methods tackle this problem as a sequence generation problem which imposes a specific ordering on the elements of the layout making such methods impractical for interactive editing or scene completion. Additionally, most methods focus on generating layouts unconditionally and offer minimal control over the generated layouts. We propose COFS, an architecture based on standard transformer architecture blocks from language modeling. The proposed model is invariant to object order by design, removing the unnatural requirement of specifying an object generation order. Furthermore, the model allows for user interaction at multiple levels enabling fine grained control over the generation process. Our model consistently outperforms other methods which we verify by performing quantitative evaluations. Our method is also faster to train and sample from, compared to existing methods.