 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramidalWan: On Making Pretrained Video Model Pyramidal for Efficient Inference
Jan 08, 2026Recently proposed pyramidal models decompose the conventional forward and backward diffusion processes into multiple stages operating at varying resolutions. These models handle inputs with higher noise levels at lower resolutions, while less noisy inputs are processed at higher resolutions. This hierarchical approach significantly reduces the computational cost of inference in multi-step denoising models. However, existing open-source pyramidal video models have been trained from scratch and tend to underperform compared to state-of-the-art systems in terms of visual plausibility. In this work, we present a pipeline that converts a pretrained diffusion model into a pyramidal one through low-cost finetuning, achieving this transformation without degradation in quality of output videos. Furthermore, we investigate and compare various strategies for step distillation within pyramidal models, aiming to further enhance the inference efficiency. Our results are available at https://qualcomm-ai-research.github.io/PyramidalWan.
Neodragon: Mobile Video Generation using Diffusion Transformer
Nov 08, 2025We introduce Neodragon, a text-to-video system capable of generating 2s (49 frames @24 fps) videos at the 640x1024 resolution directly on a Qualcomm Hexagon NPU in a record 6.7s (7 FPS). Differing from existing transformer-based offline text-to-video generation models, Neodragon is the first to have been specifically optimised for mobile hardware to achieve efficient and high-fidelity video synthesis. We achieve this through four key technical contributions: (1) Replacing the original large 4.762B T5xxl Text-Encoder with a much smaller 0.2B DT5 (DistilT5) with minimal quality loss, enabled through a novel Text-Encoder Distillation procedure. (2) Proposing an Asymmetric Decoder Distillation approach allowing us to replace the native codec-latent-VAE decoder with a more efficient one, without disturbing the generative latent-space of the generation pipeline. (3) Pruning of MMDiT blocks within the denoiser backbone based on their relative importance, with recovery of original performance through a two-stage distillation process. (4) Reducing the NFE (Neural Functional Evaluation) requirement of the denoiser by performing step distillation using DMD adapted for pyramidal flow-matching, thereby substantially accelerating video generation. When paired with an optimised SSD1B first-frame image generator and QuickSRNet for 2x super-resolution, our end-to-end Neodragon system becomes a highly parameter (4.945B full model), memory (3.5GB peak RAM usage), and runtime (6.7s E2E latency) efficient mobile-friendly model, while achieving a VBench total score of 81.61. By enabling low-cost, private, and on-device text-to-video synthesis, Neodragon democratizes AI-based video content creation, empowering creators to generate high-quality videos without reliance on cloud services. Code and model will be made publicly available at our website: https://qualcomm-ai-research.github.io/neodragon
Meta 3D Gen
Jul 02, 2024


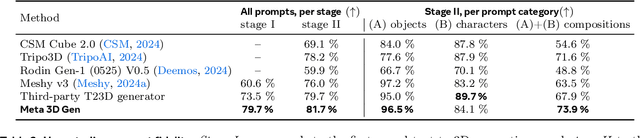
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
GOEnFusion: Gradient Origin Encodings for 3D Forward Diffusion Models
Dec 14, 2023The recently introduced Forward-Diffusion method allows to train a 3D diffusion model using only 2D images for supervision. However, it does not easily generalise to different 3D representations and requires a computationally expensive auto-regressive sampling process to generate the underlying 3D scenes. In this paper, we propose GOEn: Gradient Origin Encoding (pronounced "gone"). GOEn can encode input images into any type of 3D representation without the need to use a pre-trained image feature extractor. It can also handle single, multiple or no source view(s) alike, by design, and tries to maximise the information transfer from the views to the encodings. Our proposed GOEnFusion model pairs GOEn encodings with a realisation of the Forward-Diffusion model which addresses the limitations of the vanilla Forward-Diffusion realisation. We evaluate how much information the GOEn mechanism transfers to the encoded representations, and how well it captures the prior distribution over the underlying 3D scenes, through the lens of a partial AutoEncoder. Lastly, the efficacy of the GOEnFusion model is evaluated on the recently proposed OmniObject3D dataset while comparing to the state-of-the-art Forward and non-Forward-Diffusion models and other 3D generative models.
HoloFusion: Towards Photo-realistic 3D Generative Modeling
Aug 28, 2023Diffusion-based image generators can now produce high-quality and diverse samples, but their success has yet to fully translate to 3D generation: existing diffusion methods can either generate low-resolution but 3D consistent outputs, or detailed 2D views of 3D objects but with potential structural defects and lacking view consistency or realism. We present HoloFusion, a method that combines the best of these approaches to produce high-fidelity, plausible, and diverse 3D samples while learning from a collection of multi-view 2D images only. The method first generates coarse 3D samples using a variant of the recently proposed HoloDiffusion generator. Then, it independently renders and upsamples a large number of views of the coarse 3D model, super-resolves them to add detail, and distills those into a single, high-fidelity implicit 3D representation, which also ensures view consistency of the final renders. The super-resolution network is trained as an integral part of HoloFusion, end-to-end, and the final distillation uses a new sampling scheme to capture the space of super-resolved signals. We compare our method against existing baselines, including DreamFusion, Get3D, EG3D, and HoloDiffusion, and achieve, to the best of our knowledge, the most realistic results on the challenging CO3Dv2 dataset.
HOLODIFFUSION: Training a 3D Diffusion Model using 2D Images
Mar 29, 2023Diffusion models have emerged as the best approach for generative modeling of 2D images. Part of their success is due to the possibility of training them on millions if not billions of images with a stable learning objective. However, extending these models to 3D remains difficult for two reasons. First, finding a large quantity of 3D training data is much more complex than for 2D images. Second, while it is conceptually trivial to extend the models to operate on 3D rather than 2D grids, the associated cubic growth in memory and compute complexity makes this infeasible. We address the first challenge by introducing a new diffusion setup that can be trained, end-to-end, with only posed 2D images for supervision; and the second challenge by proposing an image formation model that decouples model memory from spatial memory. We evaluate our method on real-world data, using the CO3D dataset which has not been used to train 3D generative models before. We show that our diffusion models are scalable, train robustly, and are competitive in terms of sample quality and fidelity to existing approaches for 3D generative modeling.
3inGAN: Learning a 3D Generative Model from Images of a Self-similar Scene
Nov 27, 2022We introduce 3inGAN, an unconditional 3D generative model trained from 2D images of a single self-similar 3D scene. Such a model can be used to produce 3D "remixes" of a given scene, by mapping spatial latent codes into a 3D volumetric representation, which can subsequently be rendered from arbitrary views using physically based volume rendering. By construction, the generated scenes remain view-consistent across arbitrary camera configurations, without any flickering or spatio-temporal artifacts. During training, we employ a combination of 2D, obtained through differentiable volume tracing, and 3D Generative Adversarial Network (GAN) losses, across multiple scales, enforcing realism on both its 3D structure and the 2D renderings. We show results on semi-stochastic scenes of varying scale and complexity, obtained from real and synthetic sources. We demonstrate, for the first time, the feasibility of learning plausible view-consistent 3D scene variations from a single exemplar scene and provide qualitative and quantitative comparisons against recent related methods.
ReLU Fields: The Little Non-linearity That Could
May 22, 2022



In many recent works, multi-layer perceptions (MLPs) have been shown to be suitable for modeling complex spatially-varying functions including images and 3D scenes. Although the MLPs are able to represent complex scenes with unprecedented quality and memory footprint, this expressive power of the MLPs, however, comes at the cost of long training and inference times. On the other hand, bilinear/trilinear interpolation on regular grid based representations can give fast training and inference times, but cannot match the quality of MLPs without requiring significant additional memory. Hence, in this work, we investigate what is the smallest change to grid-based representations that allows for retaining the high fidelity result of MLPs while enabling fast reconstruction and rendering times. We introduce a surprisingly simple change that achieves this task -- simply allowing a fixed non-linearity (ReLU) on interpolated grid values. When combined with coarse to-fine optimization, we show that such an approach becomes competitive with the state-of-the-art. We report results on radiance fields, and occupancy fields, and compare against multiple existing alternatives. Code and data for the paper are available at https://geometry.cs.ucl.ac.uk/projects/2022/relu_fields.
RGBD-Net: Predicting color and depth images for novel views synthesis
Nov 29, 2020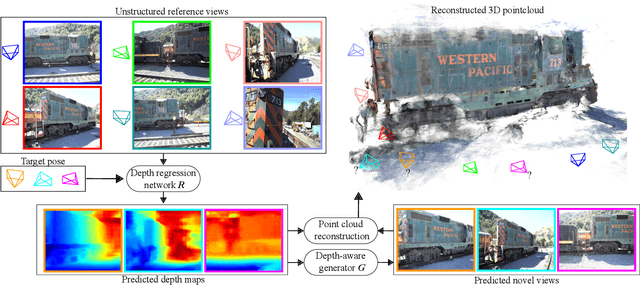
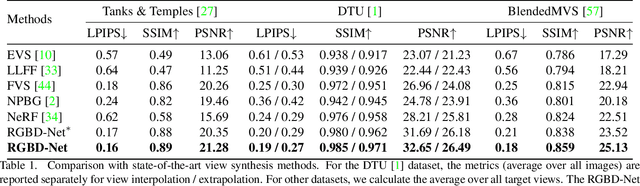
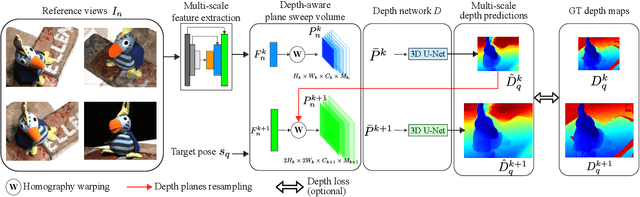
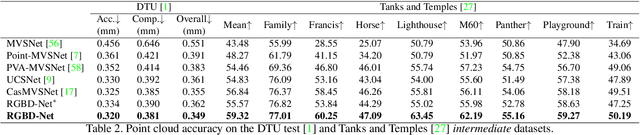
We address the problem of novel view synthesis from an unstructured set of reference images. A new method called RGBD-Net is proposed to predict the depth map and the color images at the target pose in a multi-scale manner. The reference views are warped to the target pose to obtain multi-scale plane sweep volumes, which are then passed to our first module, a hierarchical depth regression network which predicts the depth map of the novel view. Second, a depth-aware generator network refines the warped novel views and renders the final target image. These two networks can be trained with or without depth supervision. In experimental evaluation, RGBD-Net not only produces novel views with higher quality than the previous state-of-the-art methods, but also the obtained depth maps enable reconstruction of more accurate 3D point clouds than the existing multi-view stereo methods. The results indicate that RGBD-Net generalizes well to previously unseen data.
MSG-GAN: Multi-Scale Gradient GAN for Stable Image Synthesis
Mar 22, 2019



While Generative Adversarial Networks (GANs) have seen huge successes in image synthesis tasks, they are notoriously difficult to use, in part due to instability during training. One commonly accepted reason for this instability is that gradients passing from the discriminator to the generator can quickly become uninformative, due to a learning imbalance during training. In this work, we propose the Multi-Scale Gradient Generative Adversarial Network (MSG-GAN), a simple but effective technique for addressing this problem which allows the flow of gradients from the discriminator to the generator at multiple scales. This technique provides a stable approach for generating synchronized multi-scale images. We present a very intuitive implementation of the mathematical MSG-GAN framework which uses the concatenation operation in the discriminator computations. We empirically validate the effect of our MSG-GAN approach through experiments on the CIFAR10 and Oxford102 flowers datasets and compare it with other relevant techniques which perform multi-scale image synthesis. In addition, we also provide details of our experiment on CelebA-HQ dataset for synthesizing 1024 x 1024 high resolution images.