 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRF-Net: Holistic Radiance Fields from Sparse Inputs
Aug 09, 2022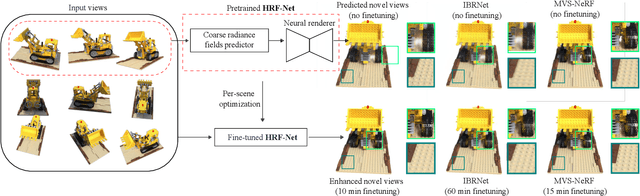
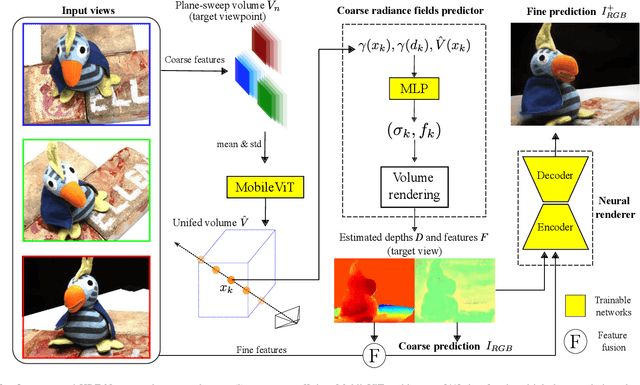
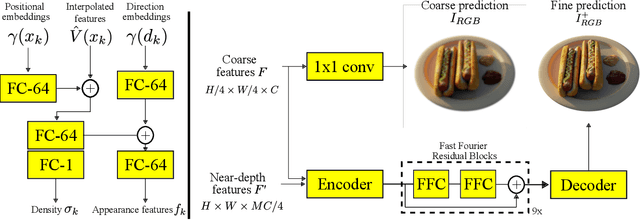
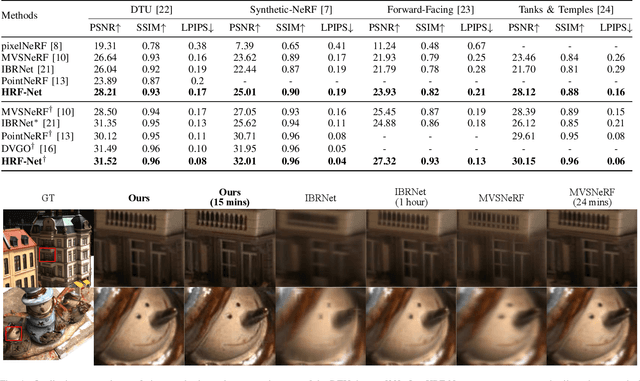
We present HRF-Net, a novel view synthesis method based on holistic radiance fields that renders novel views using a set of sparse inputs. Recent generalizing view synthesis methods also leverage the radiance fields but the rendering speed is not real-time. There are existing methods that can train and render novel views efficiently but they can not generalize to unseen scenes. Our approach addresses the problem of real-time rendering for generalizing view synthesis and consists of two main stages: a holistic radiance fields predictor and a convolutional-based neural renderer. This architecture infers not only consistent scene geometry based on the implicit neural fields but also renders new views efficiently using a single GPU. We first train HRF-Net on multiple 3D scenes of the DTU dataset and the network can produce plausible novel views on unseen real and synthetics data using only photometric losses. Moreover, our method can leverage a denser set of reference images of a single scene to produce accurate novel views without relying on additional explicit representations and still maintains the high-speed rendering of the pre-trained model. Experimental results show that HRF-Net outperforms state-of-the-art generalizable neural rendering methods on various synthetic and real datasets.
Fast Neural Architecture Search for Lightweight Dense Prediction Networks
Mar 09, 2022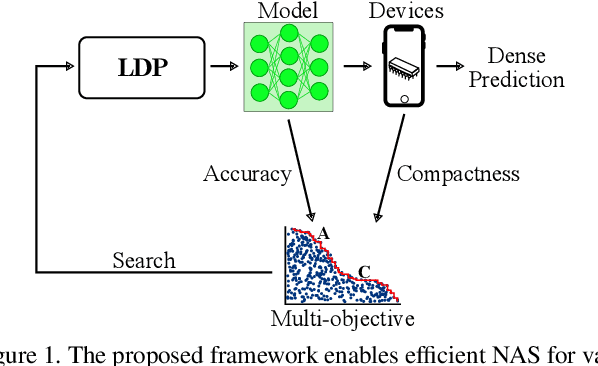
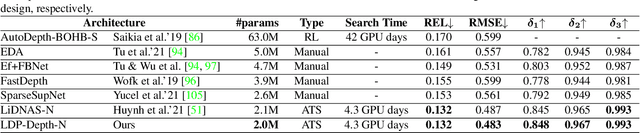
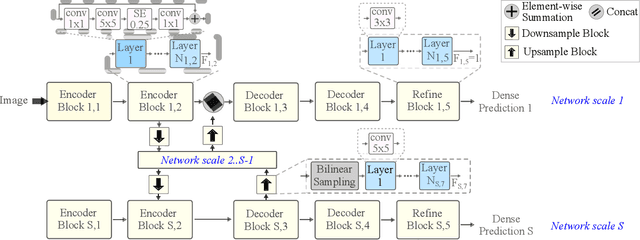
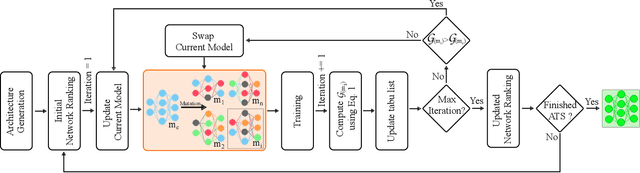
We present LDP, a lightweight dense prediction neural architecture search (NAS) framework. Starting from a pre-defined generic backbone, LDP applies the novel Assisted Tabu Search for efficient architecture exploration. LDP is fast and suitable for various dense estimation problems, unlike previous NAS methods that are either computational demanding or deployed only for a single subtask. The performance of LPD is evaluated on monocular depth estimation, semantic segmentation, and image super-resolution tasks on diverse datasets, including NYU-Depth-v2, KITTI, Cityscapes, COCO-stuff, DIV2K, Set5, Set14, BSD100, Urban100. Experiments show that the proposed framework yields consistent improvements on all tested dense prediction tasks, while being $5\%-315\%$ more compact in terms of the number of model parameters than prior arts.
StressNAS: Affect State and Stress Detection Using Neural Architecture Search
Aug 26, 2021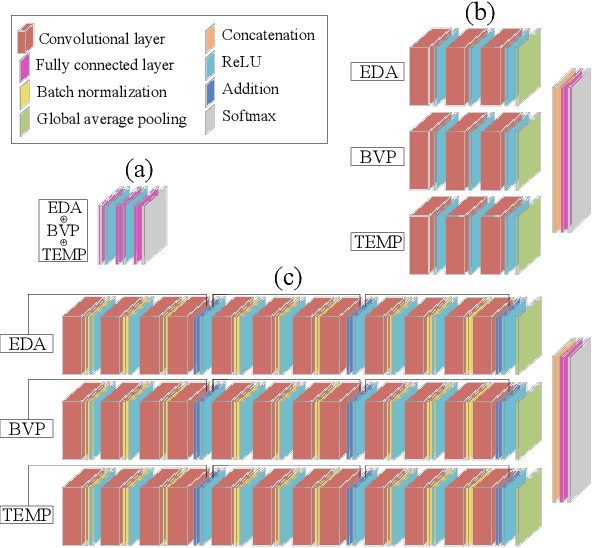
Smartwatches have rapidly evolved towards capabilities to accurately capture physiological signals. As an appealing application, stress detection attracts many studies due to its potential benefits to human health. It is propitious to investigate the applicability of deep neural networks (DNN) to enhance human decision-making through physiological signals. However, manually engineering DNN proves a tedious task especially in stress detection due to the complex nature of this phenomenon. To this end, we propose an optimized deep neural network training scheme using neural architecture search merely using wrist-worn data from WESAD. Experiments show that our approach outperforms traditional ML methods by 8.22% and 6.02% in the three-state and two-state classifiers, respectively, using the combination of WESAD wrist signals. Moreover, the proposed method can minimize the need for human-design DNN while improving performance by 4.39% (three-state) and 8.99% (binary).
Lightweight Monocular Depth with a Novel Neural Architecture Search Method
Aug 25, 2021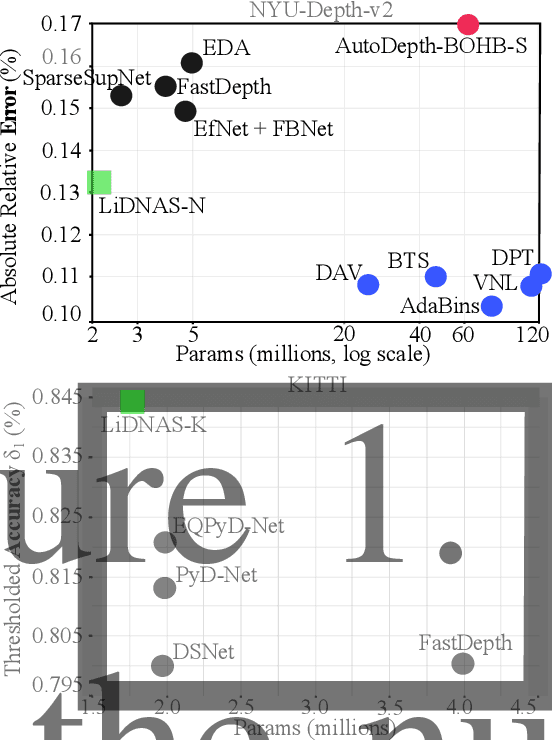

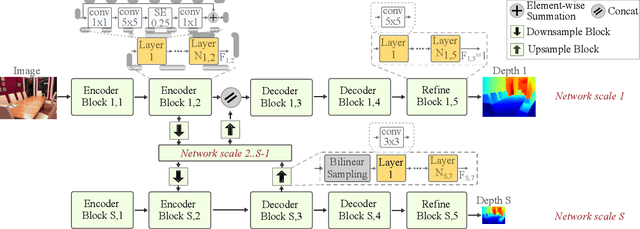
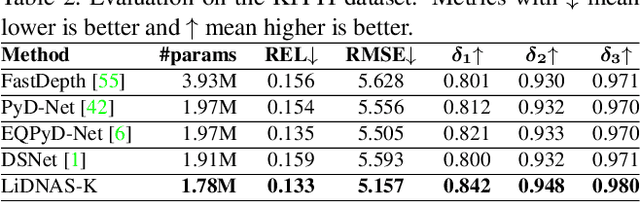
This paper presents a novel neural architecture search method, called LiDNAS, for generating lightweight monocular depth estimation models. Unlike previous neural architecture search (NAS) approaches, where finding optimized networks are computationally highly demanding, the introduced novel Assisted Tabu Search leads to efficient architecture exploration. Moreover, we construct the search space on a pre-defined backbone network to balance layer diversity and search space size. The LiDNAS method outperforms the state-of-the-art NAS approach, proposed for disparity and depth estimation, in terms of search efficiency and output model performance. The LiDNAS optimized models achieve results superior to compact depth estimation state-of-the-art on NYU-Depth-v2, KITTI, and ScanNet, while being 7%-500% more compact in size, i.e the number of model parameters.
Monocular Depth Estimation Primed by Salient Point Detection and Normalized Hessian Loss
Aug 25, 2021
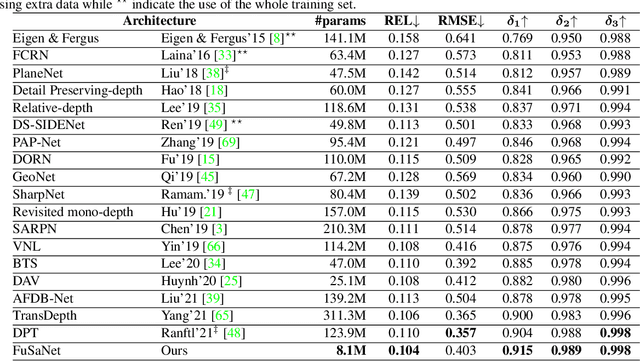
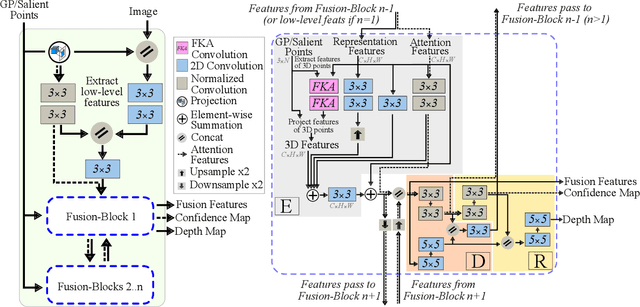
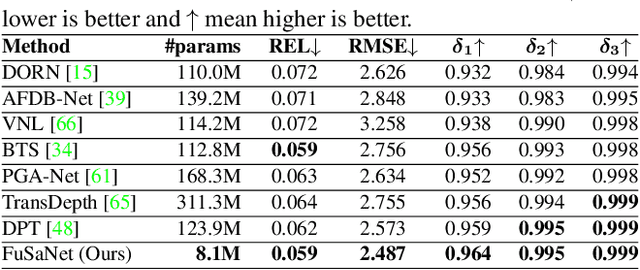
Deep neural networks have recently thrived on single image depth estimation. That being said, current developments on this topic highlight an apparent compromise between accuracy and network size. This work proposes an accurate and lightweight framework for monocular depth estimation based on a self-attention mechanism stemming from salient point detection. Specifically, we utilize a sparse set of keypoints to train a FuSaNet model that consists of two major components: Fusion-Net and Saliency-Net. In addition, we introduce a normalized Hessian loss term invariant to scaling and shear along the depth direction, which is shown to substantially improve the accuracy. The proposed method achieves state-of-the-art results on NYU-Depth-v2 and KITTI while using 3.1-38.4 times smaller model in terms of the number of parameters than baseline approaches. Experiments on the SUN-RGBD further demonstrate the generalizability of the proposed method.
Boosting Monocular Depth Estimation with Lightweight 3D Point Fusion
Dec 18, 2020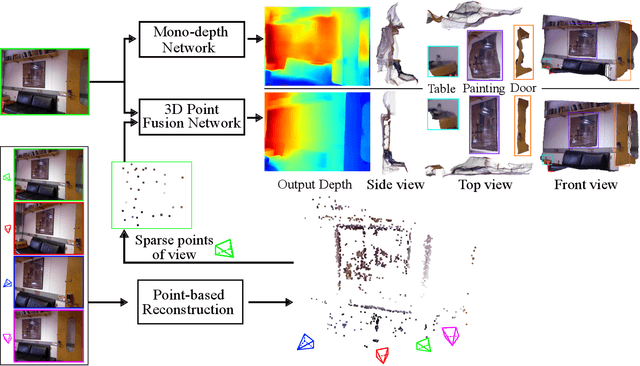
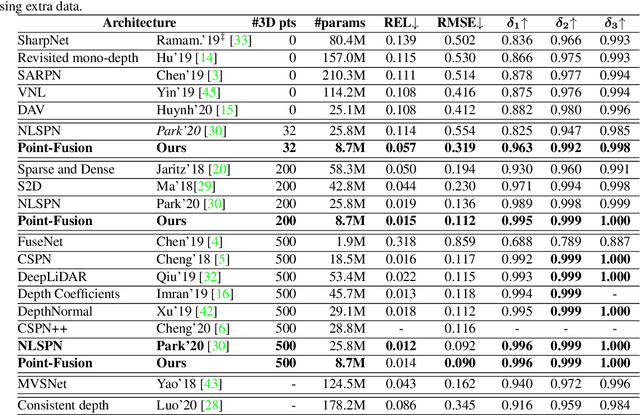
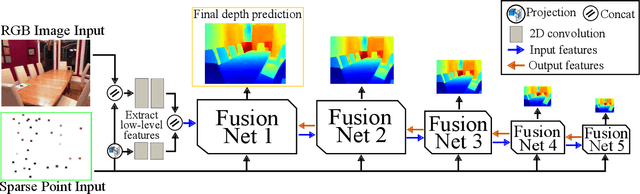
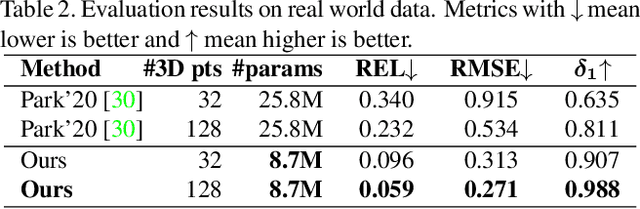
In this paper, we address the problem of fusing monocular depth estimation with a conventional multi-view stereo or SLAM to exploit the best of both worlds, that is, the accurate dense depth of the first one and lightweightness of the second one. More specifically, we use a conventional pipeline to produce a sparse 3D point cloud that is fed to a monocular depth estimation network to enhance its performance. In this way, we can achieve accuracy similar to multi-view stereo with a considerably smaller number of weights. We also show that even as few as 32 points is sufficient to outperform the best monocular depth estimation methods, and around 200 points to gain full advantage of the additional information. Moreover, we demonstrate the efficacy of our approach by integrating it with a SLAM system built-in on mobile devices.
RGBD-Net: Predicting color and depth images for novel views synthesis
Nov 29, 2020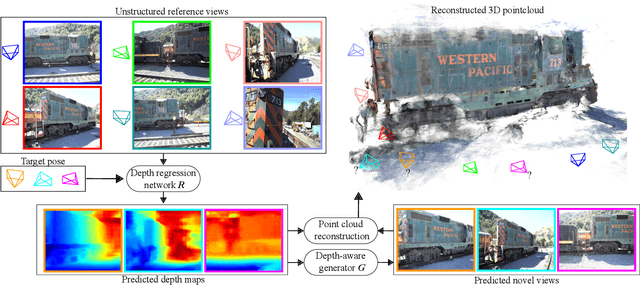
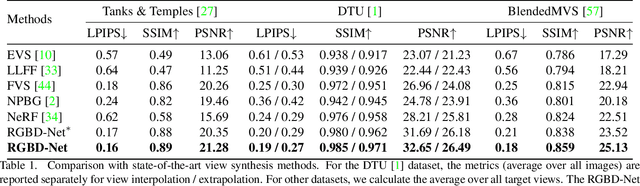
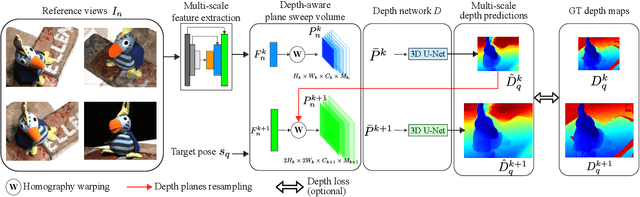
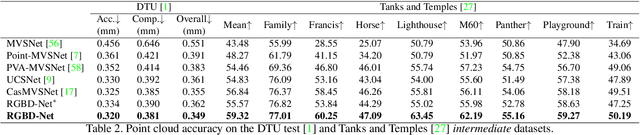
We address the problem of novel view synthesis from an unstructured set of reference images. A new method called RGBD-Net is proposed to predict the depth map and the color images at the target pose in a multi-scale manner. The reference views are warped to the target pose to obtain multi-scale plane sweep volumes, which are then passed to our first module, a hierarchical depth regression network which predicts the depth map of the novel view. Second, a depth-aware generator network refines the warped novel views and renders the final target image. These two networks can be trained with or without depth supervision. In experimental evaluation, RGBD-Net not only produces novel views with higher quality than the previous state-of-the-art methods, but also the obtained depth maps enable reconstruction of more accurate 3D point clouds than the existing multi-view stereo methods. The results indicate that RGBD-Net generalizes well to previously unseen data.
Sequential Neural Rendering with Transformer
Apr 09, 2020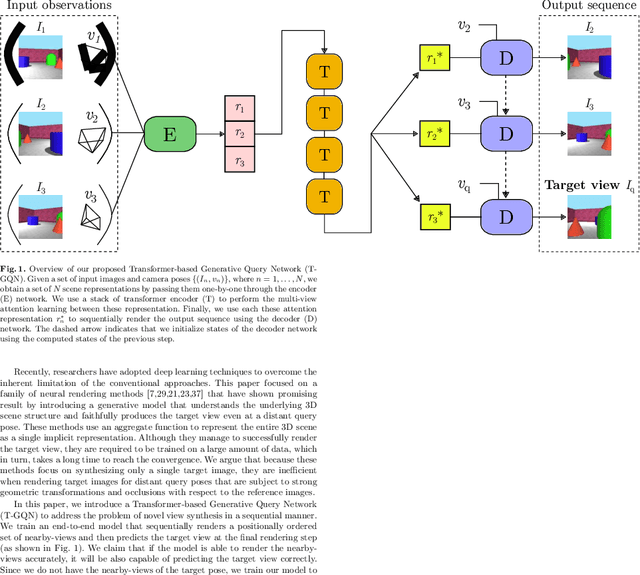
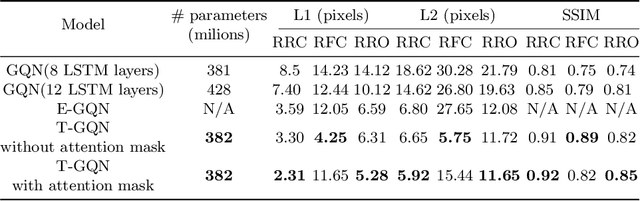
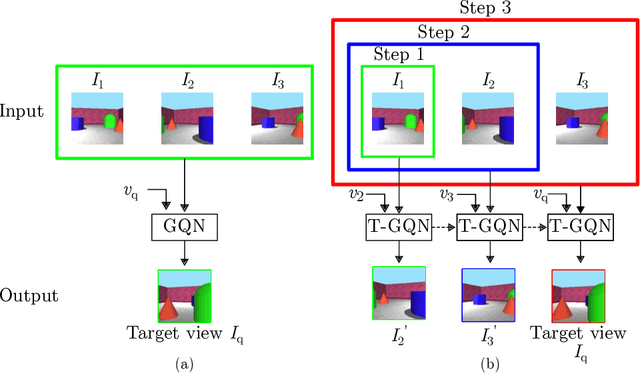

This paper address the problem of novel view synthesis by means of neural rendering, where we are interested in predicting the novel view at an arbitrary camera pose based on a given set of input images from other viewpoints. Using the known query pose and input poses, we create an ordered set of observations that leads to the target view. Thus, the problem of single novel view synthesis is reformulated as a sequential view prediction task. In this paper, the proposed Transformer-based Generative Query Network (T-GQN) extends the neural-rendering methods by adding two new concepts. First, we use multi-view attention learning between context images to obtain multiple implicit scene representations. Second, we introduce a sequential rendering decoder to predict an image sequence, including the target view, based on the learned representations. We evaluate our model on various challenging synthetic datasets and demonstrate that our model can give consistent predictions and achieve faster training convergence than the former architectures.
Guiding Monocular Depth Estimation Using Depth-Attention Volume
Apr 06, 2020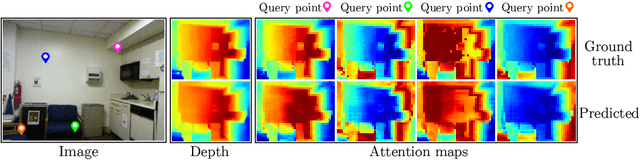
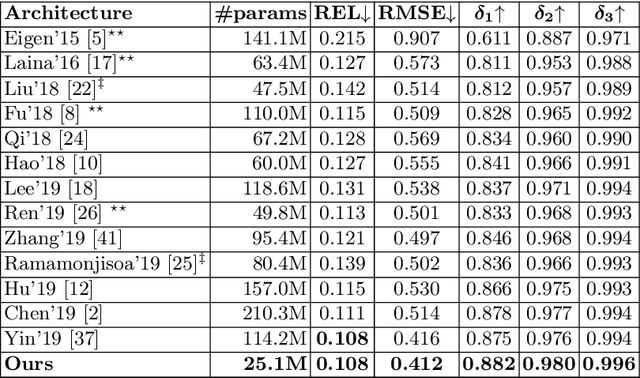
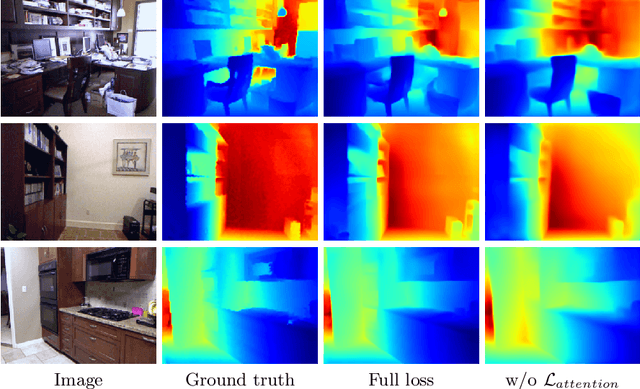
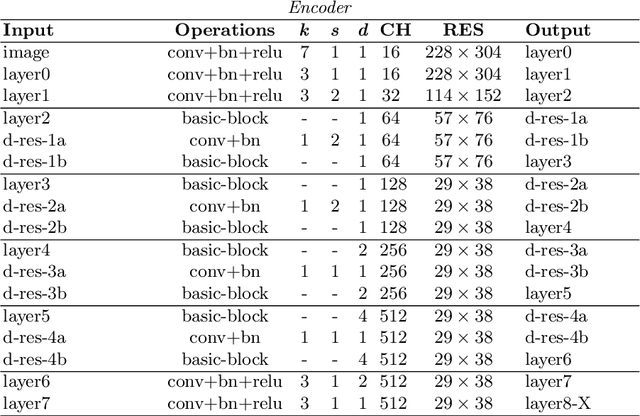
Recovering the scene depth from a single image is an ill-posed problem that requires additional priors, often referred to as monocular depth cues, to disambiguate different 3D interpretations. In recent works, those priors have been learned in an end-to-end manner from large datasets by using deep neural networks. In this paper, we propose guiding depth estimation to favor planar structures that are ubiquitous especially in indoor environments. This is achieved by incorporating a non-local coplanarity constraint to the network with a novel attention mechanism called depth-attention volume (DAV). Experiments on two popular indoor datasets, namely NYU-Depth-v2 and ScanNet, show that our method achieves state-of-the-art depth estimation results while using only a fraction of the number of parameters needed by the competing methods.
Predicting Novel Views Using Generative Adversarial Query Network
Apr 10, 2019The problem of predicting a novel view of the scene using an arbitrary number of observations is a challenging problem for computers as well as for humans. This paper introduces the Generative Adversarial Query Network (GAQN), a general learning framework for novel view synthesis that combines Generative Query Network (GQN) and Generative Adversarial Networks (GANs). The conventional GQN encodes input views into a latent representation that is used to generate a new view through a recurrent variational decoder. The proposed GAQN builds on this work by adding two novel aspects: First, we extend the current GQN architecture with an adversarial loss function for improving the visual quality and convergence speed. Second, we introduce a feature-matching loss function for stabilizing the training procedure. The experiments demonstrate that GAQN is able to produce high-quality results and faster convergence compared to the conventional approach.