 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Neural Rendering with Transformer
Paper and Code
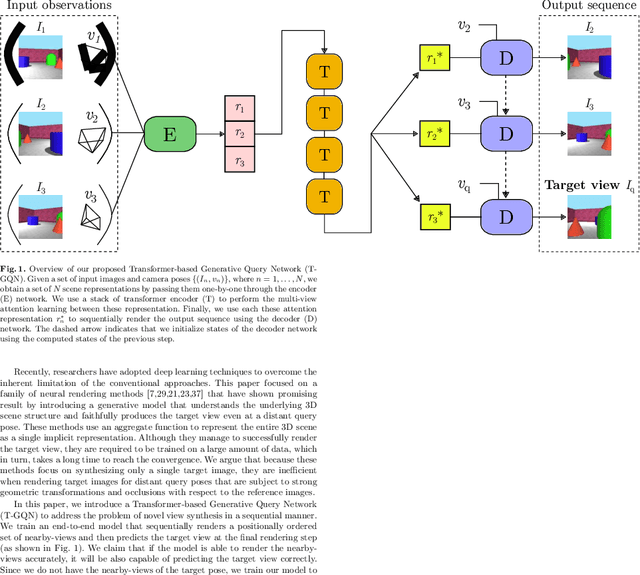
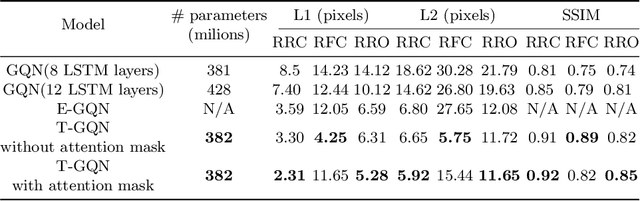
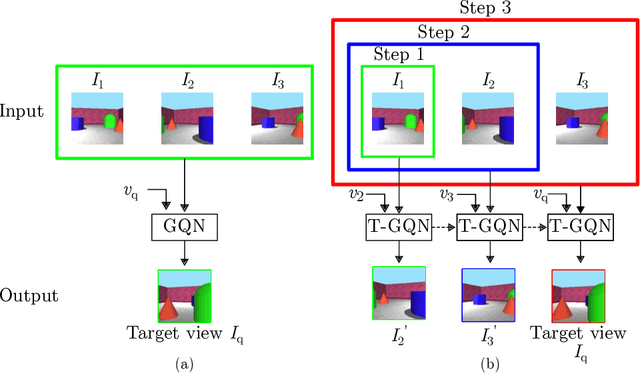

This paper address the problem of novel view synthesis by means of neural rendering, where we are interested in predicting the novel view at an arbitrary camera pose based on a given set of input images from other viewpoints. Using the known query pose and input poses, we create an ordered set of observations that leads to the target view. Thus, the problem of single novel view synthesis is reformulated as a sequential view prediction task. In this paper, the proposed Transformer-based Generative Query Network (T-GQN) extends the neural-rendering methods by adding two new concepts. First, we use multi-view attention learning between context images to obtain multiple implicit scene representations. Second, we introduce a sequential rendering decoder to predict an image sequence, including the target view, based on the learned representations. We evaluate our model on various challenging synthetic datasets and demonstrate that our model can give consistent predictions and achieve faster training convergence than the former architectures.