 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverFill: One-Step Inversion for Enhanced Few-Step Diffusion Inpainting
Mar 24, 2026Recent diffusion-based models achieve photorealism in image inpainting but require many sampling steps, limiting practical use. Few-step text-to-image models offer faster generation, but naively applying them to inpainting yields poor harmonization and artifacts between the background and inpainted region. We trace this cause to random Gaussian noise initialization, which under low function evaluations causes semantic misalignment and reduced fidelity. To overcome this, we propose InverFill, a one-step inversion method tailored for inpainting that injects semantic information from the input masked image into the initial noise, enabling high-fidelity few-step inpainting. Instead of training inpainting models, InverFill leverages few-step text-to-image models in a blended sampling pipeline with semantically aligned noise as input, significantly improving vanilla blended sampling and even matching specialized inpainting models at low NFEs. Moreover, InverFill does not require real-image supervision and only adds minimal inference overhead. Extensive experiments show that InverFill consistently boosts baseline few-step models, improving image quality and text coherence without costly retraining or heavy iterative optimization.
SwiftTailor: Efficient 3D Garment Generation with Geometry Image Representation
Mar 19, 2026Realistic and efficient 3D garment generation remains a longstanding challenge in computer vision and digital fashion. Existing methods typically rely on large vision- language models to produce serialized representations of 2D sewing patterns, which are then transformed into simulation-ready 3D meshes using garment modeling framework such as GarmentCode. Although these approaches yield high-quality results, they often suffer from slow inference times, ranging from 30 seconds to a minute. In this work, we introduce SwiftTailor, a novel two-stage framework that unifies sewing-pattern reasoning and geometry-based mesh synthesis through a compact geometry image representation. SwiftTailor comprises two lightweight modules: PatternMaker, an efficient vision-language model that predicts sewing patterns from diverse input modalities, and GarmentSewer, an efficient dense prediction transformer that converts these patterns into a novel Garment Geometry Image, encoding the 3D surface of all garment panels in a unified UV space. The final 3D mesh is reconstructed through an efficient inverse mapping process that incorporates remeshing and dynamic stitching algorithms to directly assemble the garment, thereby amortizing the cost of physical simulation. Extensive experiments on the Multimodal GarmentCodeData demonstrate that SwiftTailor achieves state-of-the-art accuracy and visual fidelity while significantly reducing inference time. This work offers a scalable, interpretable, and high-performance solution for next-generation 3D garment generation.
PixelRush: Ultra-Fast, Training-Free High-Resolution Image Generation via One-step Diffusion
Feb 13, 2026Pre-trained diffusion models excel at generating high-quality images but remain inherently limited by their native training resolution. Recent training-free approaches have attempted to overcome this constraint by introducing interventions during the denoising process; however, these methods incur substantial computational overhead, often requiring more than five minutes to produce a single 4K image. In this paper, we present PixelRush, the first tuning-free framework for practical high-resolution text-to-image generation. Our method builds upon the established patch-based inference paradigm but eliminates the need for multiple inversion and regeneration cycles. Instead, PixelRush enables efficient patch-based denoising within a low-step regime. To address artifacts introduced by patch blending in few-step generation, we propose a seamless blending strategy. Furthermore, we mitigate over-smoothing effects through a noise injection mechanism. PixelRush delivers exceptional efficiency, generating 4K images in approximately 20 seconds representing a 10$\times$ to 35$\times$ speedup over state-of-the-art methods while maintaining superior visual fidelity. Extensive experiments validate both the performance gains and the quality of outputs achieved by our approach.
Semise: Semi-supervised learning for severity representation in medical image
Jan 07, 2025This paper introduces SEMISE, a novel method for representation learning in medical imaging that combines self-supervised and supervised learning. By leveraging both labeled and augmented data, SEMISE addresses the challenge of data scarcity and enhances the encoder's ability to extract meaningful features. This integrated approach leads to more informative representations, improving performance on downstream tasks. As result, our approach achieved a 12% improvement in classification and a 3% improvement in segmentation, outperforming existing methods. These results demonstrate the potential of SIMESE to advance medical image analysis and offer more accurate solutions for healthcare applications, particularly in contexts where labeled data is limited.
SharpDepth: Sharpening Metric Depth Predictions Using Diffusion Distillation
Nov 27, 2024

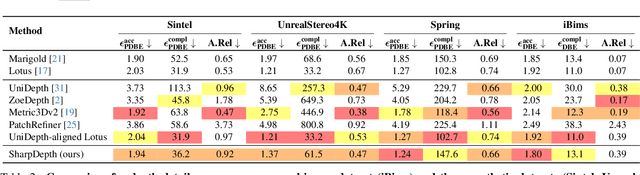

We propose SharpDepth, a novel approach to monocular metric depth estimation that combines the metric accuracy of discriminative depth estimation methods (e.g., Metric3D, UniDepth) with the fine-grained boundary sharpness typically achieved by generative methods (e.g., Marigold, Lotus). Traditional discriminative models trained on real-world data with sparse ground-truth depth can accurately predict metric depth but often produce over-smoothed or low-detail depth maps. Generative models, in contrast, are trained on synthetic data with dense ground truth, generating depth maps with sharp boundaries yet only providing relative depth with low accuracy. Our approach bridges these limitations by integrating metric accuracy with detailed boundary preservation, resulting in depth predictions that are both metrically precise and visually sharp. Our extensive zero-shot evaluations on standard depth estimation benchmarks confirm SharpDepth effectiveness, showing its ability to achieve both high depth accuracy and detailed representation, making it well-suited for applications requiring high-quality depth perception across diverse, real-world environments.
Design and Implementation of Smart Infrastructures and Connected Vehicles in A Mini-city Platform
Aug 08, 2024



This paper presents a 1/10th scale mini-city platform used as a testing bed for evaluating autonomous and connected vehicles. Using the mini-city platform, we can evaluate different driving scenarios including human-driven and autonomous driving. We provide a unique, visual feature-rich environment for evaluating computer vision methods. The conducted experiments utilize onboard sensors mounted on a robotic platform we built, allowing them to navigate in a controlled real-world urban environment. The designed city is occupied by cars, stop signs, a variety of residential and business buildings, and complex intersections mimicking an urban area. Furthermore, We have designed an intelligent infrastructure at one of the intersections in the city which helps safer and more efficient navigation in the presence of multiple cars and pedestrians. We have used the mini-city platform for the analysis of three different applications: city mapping, depth estimation in challenging occluded environments, and smart infrastructure for connected vehicles. Our smart infrastructure is among the first to develop and evaluate Vehicle-to-Infrastructure (V2I) communication at intersections. The intersection-related result shows how inaccuracy in perception, including mapping and localization, can affect safety. The proposed mini-city platform can be considered as a baseline environment for developing research and education in intelligent transportation systems.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
DiverseDream: Diverse Text-to-3D Synthesis with Augmented Text Embedding
Dec 02, 2023Text-to-3D synthesis has recently emerged as a new approach to sampling 3D models by adopting pretrained text-to-image models as guiding visual priors. An intriguing but underexplored problem with existing text-to-3D methods is that 3D models obtained from the sampling-by-optimization procedure tend to have mode collapses, and hence poor diversity in their results. In this paper, we provide an analysis and identify potential causes of such a limited diversity, and then devise a new method that considers the joint generation of different 3D models from the same text prompt, where we propose to use augmented text prompts via textual inversion of reference images to diversify the joint generation. We show that our method leads to improved diversity in text-to-3D synthesis qualitatively and quantitatively.
EmbryosFormer: Deformable Transformer and Collaborative Encoding-Decoding for Embryos Stage Development Classification
Oct 07, 2022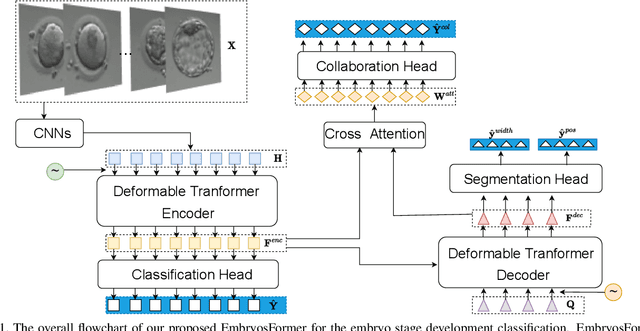

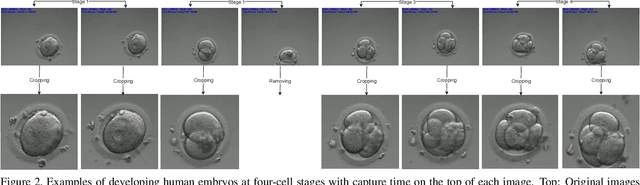
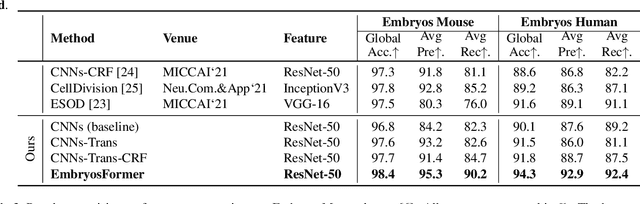
The timing of cell divisions in early embryos during the In-Vitro Fertilization (IVF) process is a key predictor of embryo viability. However, observing cell divisions in Time-Lapse Monitoring (TLM) is a time-consuming process and highly depends on experts. In this paper, we propose EmbryosFormer, a computational model to automatically detect and classify cell divisions from original time-lapse images. Our proposed network is designed as an encoder-decoder deformable transformer with collaborative heads. The transformer contracting path predicts per-image labels and is optimized by a classification head. The transformer expanding path models the temporal coherency between embryo images to ensure monotonic non-decreasing constraint and is optimized by a segmentation head. Both contracting and expanding paths are synergetically learned by a collaboration head. We have benchmarked our proposed EmbryosFormer on two datasets: a public dataset with mouse embryos with 8-cell stage and an in-house dataset with human embryos with 4-cell stage. Source code: https://github.com/UARK-AICV/Embryos.
Human View Synthesis using a Single Sparse RGB-D Input
Dec 30, 2021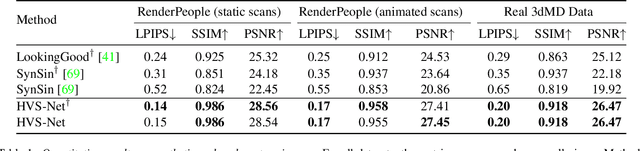

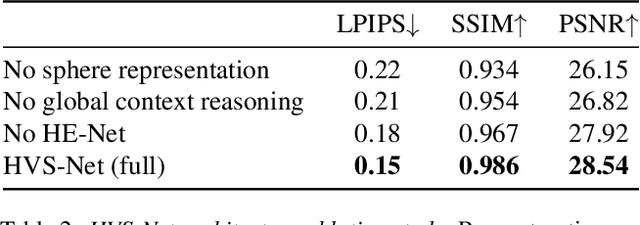
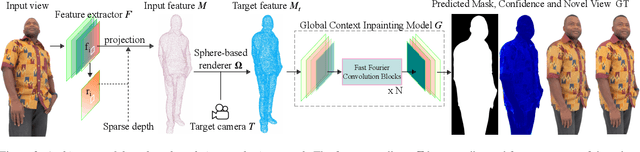
Novel view synthesis for humans in motion is a challenging computer vision problem that enables applications such as free-viewpoint video. Existing methods typically use complex setups with multiple input views, 3D supervision, or pre-trained models that do not generalize well to new identities. Aiming to address these limitations, we present a novel view synthesis framework to generate realistic renders from unseen views of any human captured from a single-view sensor with sparse RGB-D, similar to a low-cost depth camera, and without actor-specific models. We propose an architecture to learn dense features in novel views obtained by sphere-based neural rendering, and create complete renders using a global context inpainting model. Additionally, an enhancer network leverages the overall fidelity, even in occluded areas from the original view, producing crisp renders with fine details. We show our method generates high-quality novel views of synthetic and real human actors given a single sparse RGB-D input. It generalizes to unseen identities, new poses and faithfully reconstructs facial expressions. Our approach outperforms prior human view synthesis methods and is robust to different levels of input sparsity.