 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIIM: Graph-based Learning of Inter- and Intra-view Dependencies for Multi-view Medical Image Diagnosis
Mar 10, 2026Computer-aided diagnosis (CADx) has become vital in medical imaging, but automated systems often struggle to replicate the nuanced process of clinical interpretation. Expert diagnosis requires a comprehensive analysis of how abnormalities relate to each other across various views and time points, but current multi-view CADx methods frequently overlook these complex dependencies. Specifically, they fail to model the crucial relationships within a single view and the dynamic changes lesions exhibit across different views. This limitation, combined with the common challenge of incomplete data, greatly reduces their predictive reliability. To address these gaps, we reframe the diagnostic task as one of relationship modeling and propose GIIM, a novel graph-based approach. Our framework is uniquely designed to simultaneously capture both critical intra-view dependencies between abnormalities and inter-view dynamics. Furthermore, it ensures diagnostic robustness by incorporating specific techniques to effectively handle missing data, a common clinical issue. We demonstrate the generality of this approach through extensive evaluations on diverse imaging modalities, including CT, MRI, and mammography. The results confirm that our GIIM model significantly enhances diagnostic accuracy and robustness over existing methods, establishing a more effective framework for future CADx systems.
Semise: Semi-supervised learning for severity representation in medical image
Jan 07, 2025This paper introduces SEMISE, a novel method for representation learning in medical imaging that combines self-supervised and supervised learning. By leveraging both labeled and augmented data, SEMISE addresses the challenge of data scarcity and enhances the encoder's ability to extract meaningful features. This integrated approach leads to more informative representations, improving performance on downstream tasks. As result, our approach achieved a 12% improvement in classification and a 3% improvement in segmentation, outperforming existing methods. These results demonstrate the potential of SIMESE to advance medical image analysis and offer more accurate solutions for healthcare applications, particularly in contexts where labeled data is limited.
Detection of Unknown Anomalies in Streaming Videos with Generative Energy-based Boltzmann Models
Sep 29, 2018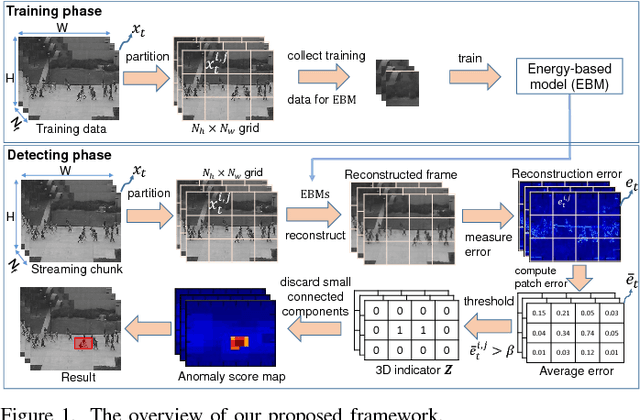

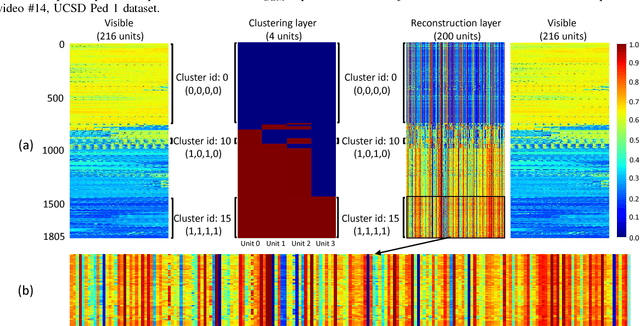
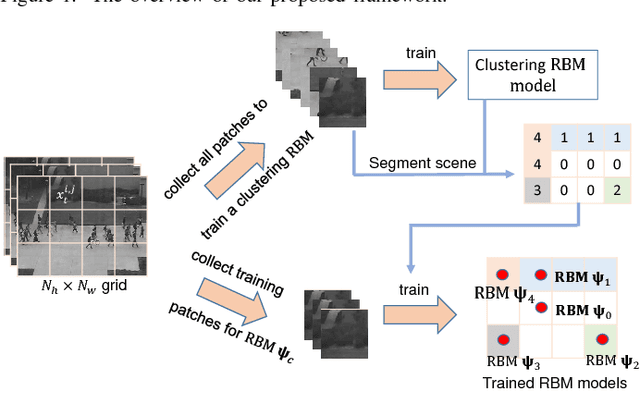
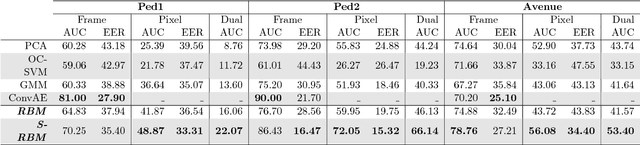
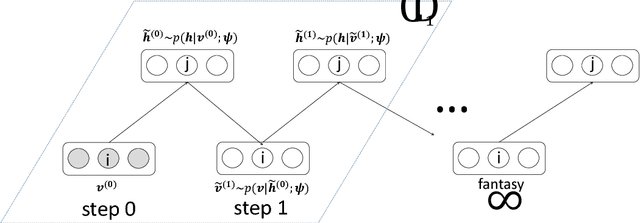
Abnormal event detection is one of the important objectives in research and practical applications of video surveillance. However, there are still three challenging problems for most anomaly detection systems in practical setting: limited labeled data, ambiguous definition of "abnormal" and expensive feature engineering steps. This paper introduces a unified detection framework to handle these challenges using energy-based models, which are powerful tools for unsupervised representation learning. Our proposed models are firstly trained on unlabeled raw pixels of image frames from an input video rather than hand-crafted visual features; and then identify the locations of abnormal objects based on the errors between the input video and its reconstruction produced by the models. To handle video stream, we develop an online version of our framework, wherein the model parameters are updated incrementally with the image frames arriving on the fly. Our experiments show that our detectors, using Restricted Boltzmann Machines (RBMs) and Deep Boltzmann Machines (DBMs) as core modules, achieve superior anomaly detection performance to unsupervised baselines and obtain accuracy comparable with the state-of-the-art approaches when evaluating at the pixel-level. More importantly, we discover that our system trained with DBMs is able to simultaneously perform scene clustering and scene reconstruction. This capacity not only distinguishes our method from other existing detectors but also offers a unique tool to investigate and understand how the model works.
Dual Discriminator Generative Adversarial Nets
Sep 12, 2017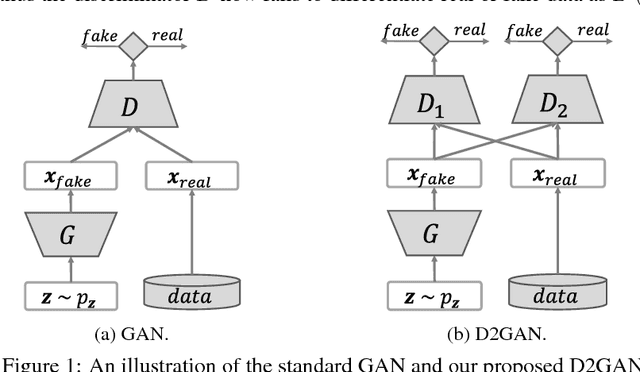


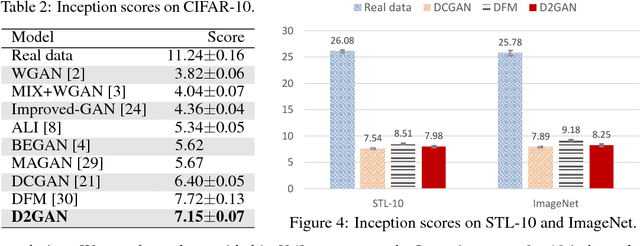
We propose in this paper a novel approach to tackle the problem of mode collapse encountered in generative adversarial network (GAN). Our idea is intuitive but proven to be very effective, especially in addressing some key limitations of GAN. In essence, it combines the Kullback-Leibler (KL) and reverse KL divergences into a unified objective function, thus it exploits the complementary statistical properties from these divergences to effectively diversify the estimated density in capturing multi-modes. We term our method dual discriminator generative adversarial nets (D2GAN) which, unlike GAN, has two discriminators; and together with a generator, it also has the analogy of a minimax game, wherein a discriminator rewards high scores for samples from data distribution whilst another discriminator, conversely, favoring data from the generator, and the generator produces data to fool both two discriminators. We develop theoretical analysis to show that, given the maximal discriminators, optimizing the generator of D2GAN reduces to minimizing both KL and reverse KL divergences between data distribution and the distribution induced from the data generated by the generator, hence effectively avoiding the mode collapsing problem. We conduct extensive experiments on synthetic and real-world large-scale datasets (MNIST, CIFAR-10, STL-10, ImageNet), where we have made our best effort to compare our D2GAN with the latest state-of-the-art GAN's variants in comprehensive qualitative and quantitative evaluations. The experimental results demonstrate the competitive and superior performance of our approach in generating good quality and diverse samples over baselines, and the capability of our method to scale up to ImageNet database.
Energy-based Models for Video Anomaly Detection
Aug 17, 2017
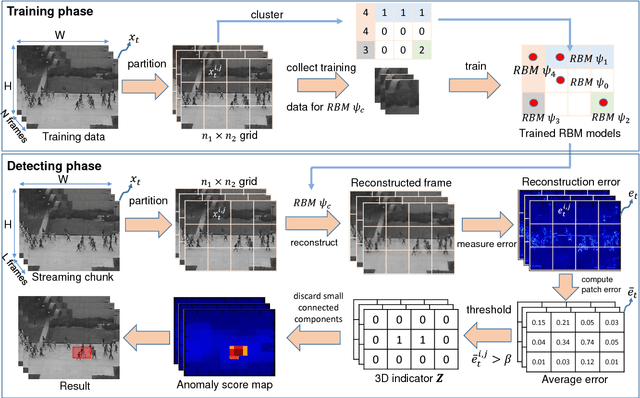
Automated detection of abnormalities in data has been studied in research area in recent years because of its diverse applications in practice including video surveillance, industrial damage detection and network intrusion detection. However, building an effective anomaly detection system is a non-trivial task since it requires to tackle challenging issues of the shortage of annotated data, inability of defining anomaly objects explicitly and the expensive cost of feature engineering procedure. Unlike existing appoaches which only partially solve these problems, we develop a unique framework to cope the problems above simultaneously. Instead of hanlding with ambiguous definition of anomaly objects, we propose to work with regular patterns whose unlabeled data is abundant and usually easy to collect in practice. This allows our system to be trained completely in an unsupervised procedure and liberate us from the need for costly data annotation. By learning generative model that capture the normality distribution in data, we can isolate abnormal data points that result in low normality scores (high abnormality scores). Moreover, by leverage on the power of generative networks, i.e. energy-based models, we are also able to learn the feature representation automatically rather than replying on hand-crafted features that have been dominating anomaly detection research over many decades. We demonstrate our proposal on the specific application of video anomaly detection and the experimental results indicate that our method performs better than baselines and are comparable with state-of-the-art methods in many benchmark video anomaly detection datasets.
Geometric Enclosing Networks
Aug 17, 2017


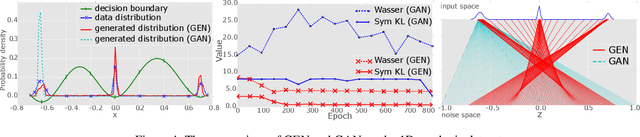
Training model to generate data has increasingly attracted research attention and become important in modern world applications. We propose in this paper a new geometry-based optimization approach to address this problem. Orthogonal to current state-of-the-art density-based approaches, most notably VAE and GAN, we present a fresh new idea that borrows the principle of minimal enclosing ball to train a generator G\left(\bz\right) in such a way that both training and generated data, after being mapped to the feature space, are enclosed in the same sphere. We develop theory to guarantee that the mapping is bijective so that its inverse from feature space to data space results in expressive nonlinear contours to describe the data manifold, hence ensuring data generated are also lying on the data manifold learned from training data. Our model enjoys a nice geometric interpretation, hence termed Geometric Enclosing Networks (GEN), and possesses some key advantages over its rivals, namely simple and easy-to-control optimization formulation, avoidance of mode collapsing and efficiently learn data manifold representation in a completely unsupervised manner. We conducted extensive experiments on synthesis and real-world datasets to illustrate the behaviors, strength and weakness of our proposed GEN, in particular its ability to handle multi-modal data and quality of generated data.