 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuatRE: Relation-Aware Quaternions for Knowledge Graph Embeddings
Sep 26, 2020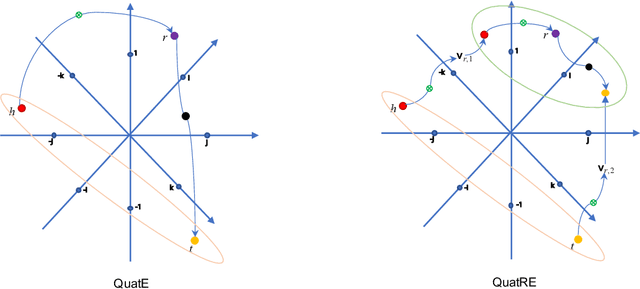
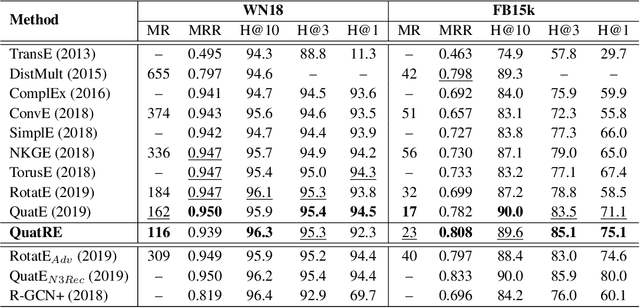
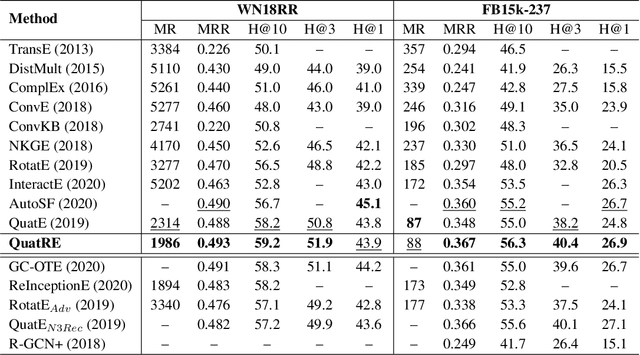
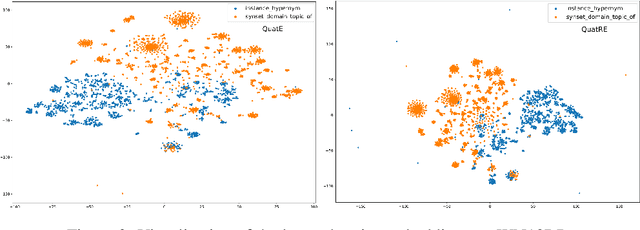
We propose a simple and effective embedding model, named QuatRE, to learn quaternion embeddings for entities and relations in knowledge graphs. QuatRE aims to enhance correlations between head and tail entities given a relation within the Quaternion space with Hamilton product. QuatRE achieves this by associating each relation with two quaternion vectors which are used to rotate the quaternion embeddings of the head and tail entities, respectively. To obtain the triple score, QuatRE rotates the rotated embedding of the head entity using the normalized quaternion embedding of the relation, followed by a quaternion-inner product with the rotated embedding of the tail entity. Experimental results show that our QuatRE outperforms up-to-date embedding models on well-known benchmark datasets for knowledge graph completion.
Quaternion Graph Neural Networks
Aug 12, 2020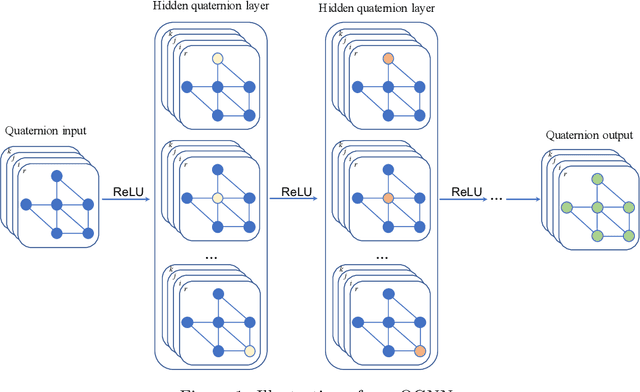
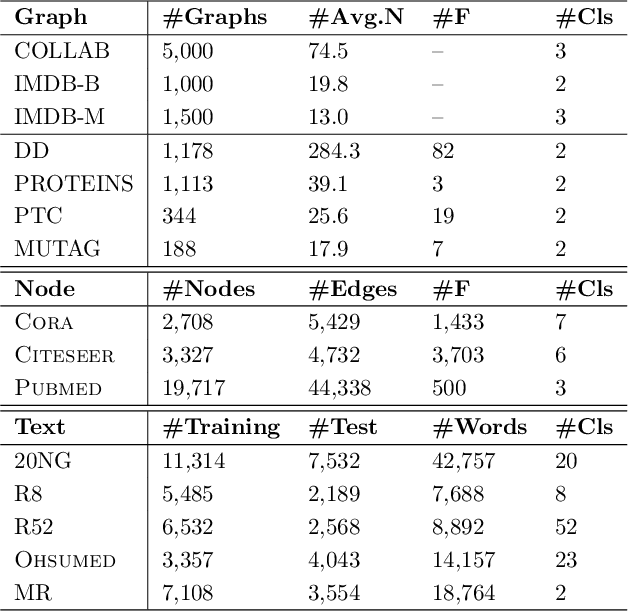
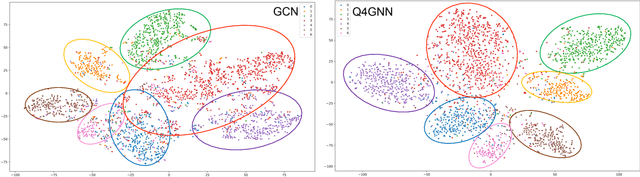
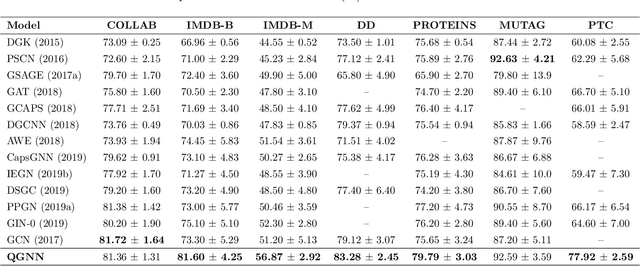
We consider reducing model parameters and moving beyond the Euclidean space to a hyper-complex space in graph neural networks (GNNs). To this end, we utilize the Quaternion space to learn quaternion node and graph embeddings. The Quaternion space, a hyper-complex space, provides highly meaningful computations through Hamilton product compared to the Euclidean and complex spaces. In particular, we propose QGNN -- a new architecture for graph neural networks which is a generalization of GCNs within the Quaternion space. QGNN reduces the model size up to four times and enhances learning graph representations. Experimental results show that our proposed QGNN produces state-of-the-art performances on a range of benchmark datasets for three downstream tasks, including graph classification, semi-supervised node classification, and text classification.
A Self-Attention Network based Node Embedding Model
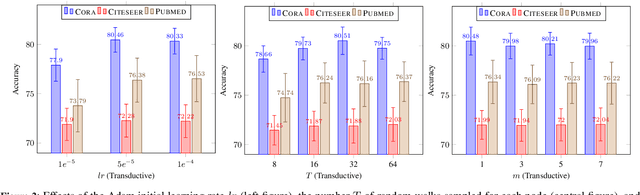
Jun 22, 2020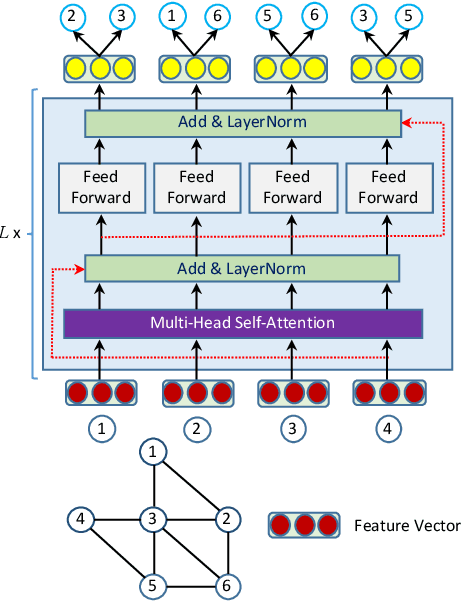

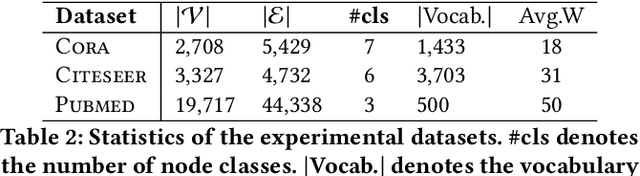
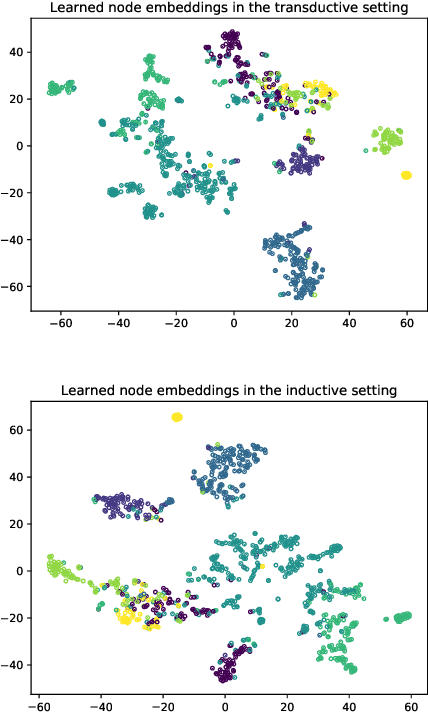
Despite several signs of progress have been made recently, limited research has been conducted for an inductive setting where embeddings are required for newly unseen nodes -- a setting encountered commonly in practical applications of deep learning for graph networks. This significantly affects the performances of downstream tasks such as node classification, link prediction or community extraction. To this end, we propose SANNE -- a novel unsupervised embedding model -- whose central idea is to employ a transformer self-attention network to iteratively aggregate vector representations of nodes in random walks. Our SANNE aims to produce plausible embeddings not only for present nodes, but also for newly unseen nodes. Experimental results show that the proposed SANNE obtains state-of-the-art results for the node classification task on well-known benchmark datasets.
A Capsule Network-based Model for Learning Node Embeddings
Nov 12, 2019


In this paper, we focus on learning low-dimensional embeddings of entity nodes from graph-structured data, where we can use the learned node embeddings for a downstream task of node classification. Existing node embedding models often suffer from a limitation of exploiting graph information to infer plausible embeddings of unseen nodes. To address this issue, we propose Caps2NE---a new unsupervised embedding model using a network of two capsule layers. Given a target node and its context nodes, Caps2NE applies a routing process to aggregate features of the context nodes at the first capsule layer, then feed these features into the second capsule layer to produce an embedding vector. This embedding vector is then used to infer a plausible embedding for the target node. Experimental results for the node classification task on six well-known benchmark datasets show that our Caps2NE obtains state-of-the-art performances.
Unsupervised Universal Self-Attention Network for Graph Classification
Sep 26, 2019
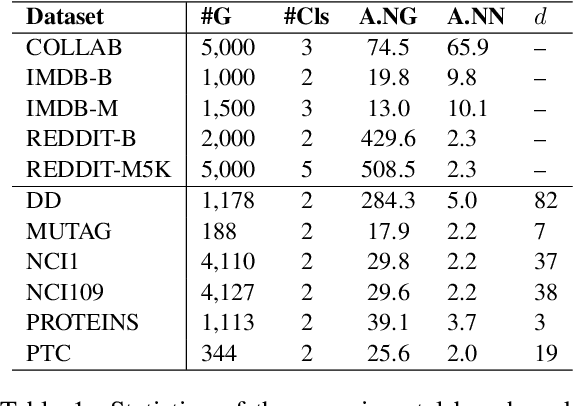


Existing graph embedding models often have weaknesses in exploiting graph structure similarities, potential dependencies among nodes and global network properties. To this end, we present U2GAN, a novel unsupervised model leveraging on the strength of the recently introduced universal self-attention network (Dehghani et al., 2019), to learn low-dimensional embeddings of graphs which can be used for graph classification. In particular, given an input graph, U2GAN first applies a self-attention computation, which is then followed by a recurrent transition to iteratively memorize its attention on vector representations of each node and its neighbors across each iteration. Thus, U2GAN can address the weaknesses in the existing models in order to produce plausible node embeddings whose sum is the final embedding of the whole graph. Experimental results show that our unsupervised U2GAN produces new state-of-the-art performances on a range of well-known benchmark datasets for the graph classification task. It even outperforms supervised methods in most of benchmark cases.
Relational Memory-based Knowledge Graph Embedding
Jul 13, 2019

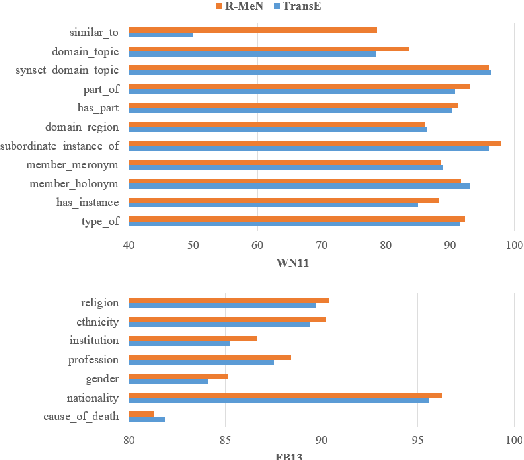
Knowledge graph embedding models often suffer from a limitation of remembering existing triples to predict new triples. To overcome this issue, we introduce a novel embedding model, named R-MeN, that explores a relational memory network to model relationship triples. In R-MeN, we simply represent each triple as a sequence of 3 input vectors which recurrently interact with a relational memory. This memory network is constructed to incorporate new information using a self-attention mechanism over the memory and input vectors to return a corresponding output vector for every timestep. Consequently, we obtain 3 output vectors which are then multiplied element-wisely into a single one; and finally, we feed this vector to a linear neural layer to produce a scalar score for the triple. Experimental results show that our proposed R-MeN obtains state-of-the-art results on two well-known benchmark datasets WN11 and FB13 for triple classification task.
Detection of Unknown Anomalies in Streaming Videos with Generative Energy-based Boltzmann Models
Sep 29, 2018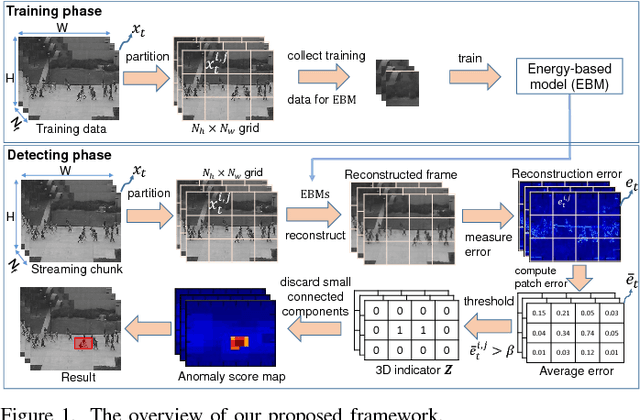

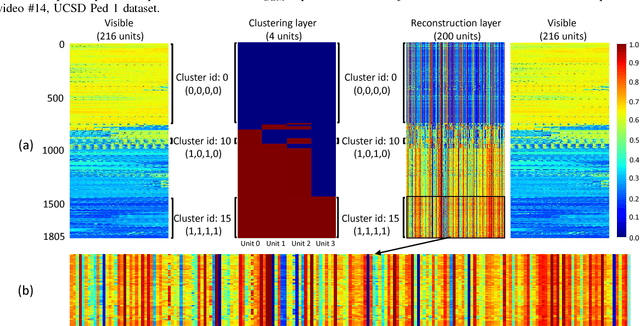
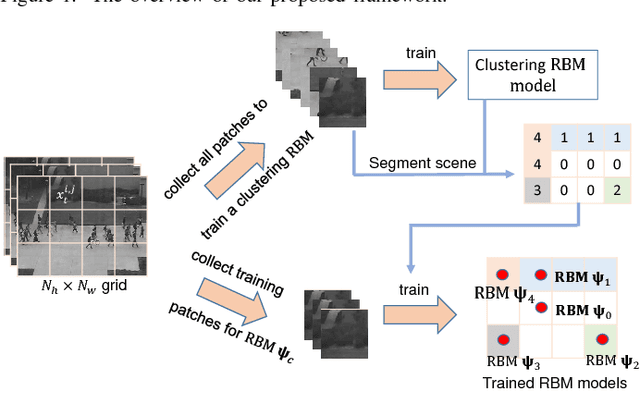
Abnormal event detection is one of the important objectives in research and practical applications of video surveillance. However, there are still three challenging problems for most anomaly detection systems in practical setting: limited labeled data, ambiguous definition of "abnormal" and expensive feature engineering steps. This paper introduces a unified detection framework to handle these challenges using energy-based models, which are powerful tools for unsupervised representation learning. Our proposed models are firstly trained on unlabeled raw pixels of image frames from an input video rather than hand-crafted visual features; and then identify the locations of abnormal objects based on the errors between the input video and its reconstruction produced by the models. To handle video stream, we develop an online version of our framework, wherein the model parameters are updated incrementally with the image frames arriving on the fly. Our experiments show that our detectors, using Restricted Boltzmann Machines (RBMs) and Deep Boltzmann Machines (DBMs) as core modules, achieve superior anomaly detection performance to unsupervised baselines and obtain accuracy comparable with the state-of-the-art approaches when evaluating at the pixel-level. More importantly, we discover that our system trained with DBMs is able to simultaneously perform scene clustering and scene reconstruction. This capacity not only distinguishes our method from other existing detectors but also offers a unique tool to investigate and understand how the model works.
A Capsule Network-based Embedding Model for Knowledge Graph Completion and Search Personalization
Aug 19, 2018


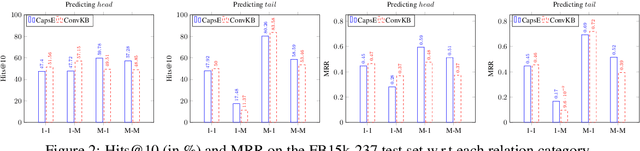
In this paper, we introduce an embedding model, named CapsE, exploring a capsule network to model relationship triples (subject, relation, object). Our CapsE represents each triple as a 3-column matrix where each column vector represents the embedding of an element in the triple. This 3-column matrix is then fed to a convolution layer where multiple filters are operated to generate different feature maps. These feature maps are used to construct capsules in the first capsule layer. Capsule layers are connected via dynamic routing mechanism. The last capsule layer consists of only one capsule to produce a vector output. The length of this vector output is used to measure the plausibility of the triple. Our proposed CapsE obtains state-of-the-art link prediction results for knowledge graph completion on two benchmark datasets: WN18RR and FB15k-237, and outperforms strong search personalization baselines on SEARCH17 dataset.
A Capsule Network-based Embedding Model for Search Personalization
Apr 12, 2018
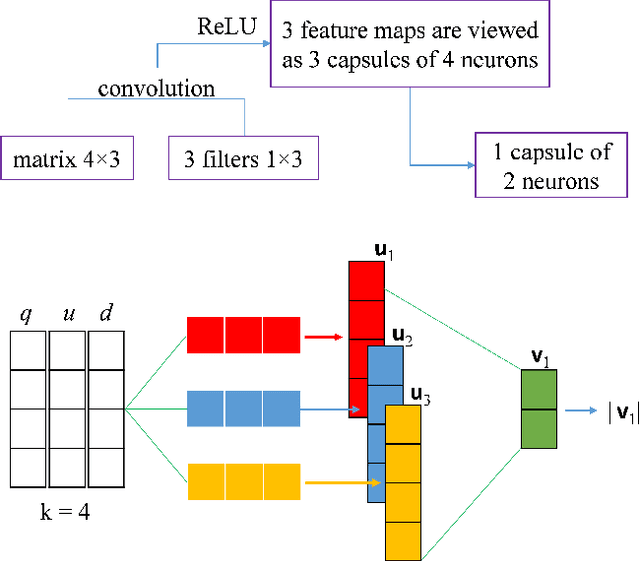

Search personalization aims to tailor search results to each specific user based on the user's personal interests and preferences (i.e., the user profile). Recent research approaches to search personalization by modelling the potential 3-way relationship between the submitted query, the user and the search results (i.e., documents). That relationship is then used to personalize the search results to that user. In this paper, we introduce a novel embedding model based on capsule network, which recently is a breakthrough in deep learning, to model the 3-way relationships for search personalization. In the model, each user (submitted query or returned document) is embedded by a vector in the same vector space. The 3-way relationship is described as a triple of (query, user, document) which is then modeled as a 3-column matrix containing the three embedding vectors. After that, the 3-column matrix is fed into a deep learning architecture to re-rank the search results returned by a basis ranker. Experimental results on query logs from a commercial web search engine show that our model achieves better performances than the basis ranker as well as strong search personalization baselines.
A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network
Mar 13, 2018

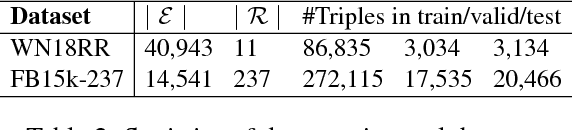
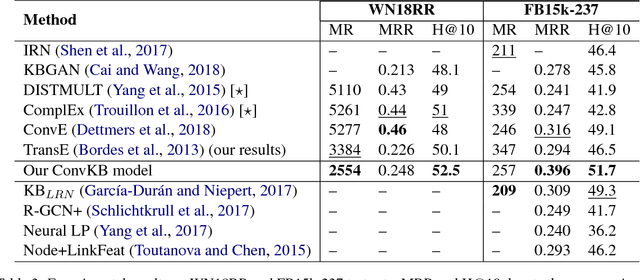
In this paper, we propose a novel embedding model, named ConvKB, for knowledge base completion. Our model ConvKB advances state-of-the-art models by employing a convolutional neural network, so that it can capture global relationships and transitional characteristics between entities and relations in knowledge bases. In ConvKB, each triple (head entity, relation, tail entity) is represented as a 3-column matrix where each column vector represents a triple element. This 3-column matrix is then fed to a convolution layer where multiple filters are operated on the matrix to generate different feature maps. These feature maps are then concatenated into a single feature vector representing the input triple. The feature vector is multiplied with a weight vector via a dot product to return a score. This score is then used to predict whether the triple is valid or not. Experiments show that ConvKB achieves better link prediction performance than previous state-of-the-art embedding models on two benchmark datasets WN18RR and FB15k-237.