 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQLong: Enhanced NL2SQL for Longer Contexts with LLMs
Feb 23, 2025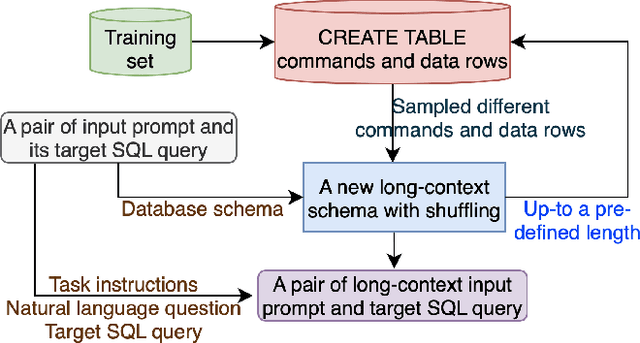
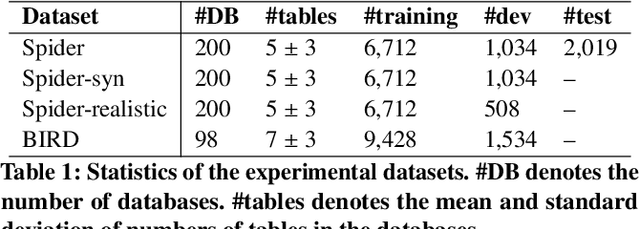

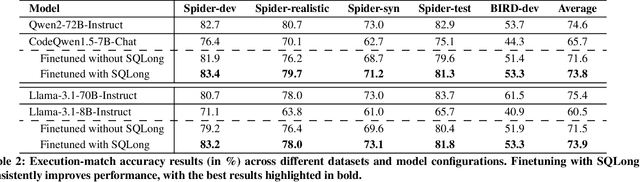
Open-weight large language models (LLMs) have significantly advanced performance in the Natural Language to SQL (NL2SQL) task. However, their effectiveness diminishes when dealing with large database schemas, as the context length increases. To address this limitation, we present SQLong, a novel and efficient data augmentation framework designed to enhance LLM performance in long-context scenarios for the NL2SQL task. SQLong generates augmented datasets by extending existing database schemas with additional synthetic CREATE TABLE commands and corresponding data rows, sampled from diverse schemas in the training data. This approach effectively simulates long-context scenarios during finetuning and evaluation. Through experiments on the Spider and BIRD datasets, we demonstrate that LLMs finetuned with SQLong-augmented data significantly outperform those trained on standard datasets. These imply SQLong's practical implementation and its impact on improving NL2SQL capabilities in real-world settings with complex database schemas.
Supporting Cross-language Cross-project Bug Localization Using Pre-trained Language Models
Jul 03, 2024Automatically locating a bug within a large codebase remains a significant challenge for developers. Existing techniques often struggle with generalizability and deployment due to their reliance on application-specific data and large model sizes. This paper proposes a novel pre-trained language model (PLM) based technique for bug localization that transcends project and language boundaries. Our approach leverages contrastive learning to enhance the representation of bug reports and source code. It then utilizes a novel ranking approach that combines commit messages and code segments. Additionally, we introduce a knowledge distillation technique that reduces model size for practical deployment without compromising performance. This paper presents several key benefits. By incorporating code segment and commit message analysis alongside traditional file-level examination, our technique achieves better bug localization accuracy. Furthermore, our model excels at generalizability - trained on code from various projects and languages, it can effectively identify bugs in unseen codebases. To address computational limitations, we propose a CPU-compatible solution. In essence, proposed work presents a highly effective, generalizable, and efficient bug localization technique with the potential to real-world deployment.
Two-view Graph Neural Networks for Knowledge Graph Completion
Dec 16, 2021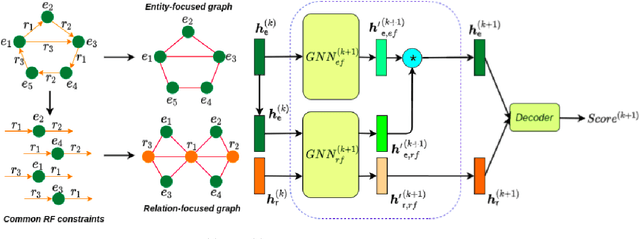

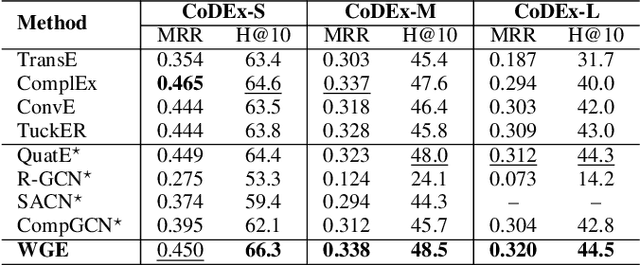
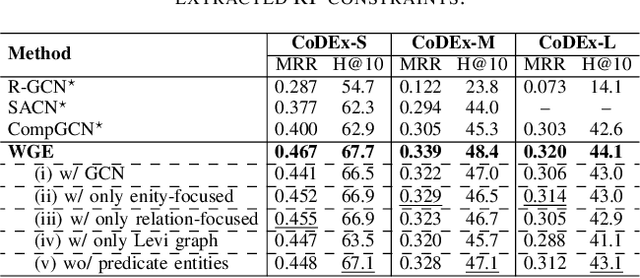
In this paper, we introduce a novel GNN-based knowledge graph embedding model, named WGE, to capture entity-focused graph structure and relation-focused graph structure. In particular, given the knowledge graph, WGE builds a single undirected entity-focused graph that views entities as nodes. In addition, WGE also constructs another single undirected graph from relation-focused constraints, which views entities and relations as nodes. WGE then proposes a new architecture of utilizing two vanilla GNNs directly on these two single graphs to better update vector representations of entities and relations, followed by a weighted score function to return the triple scores. Experimental results show that WGE obtains state-of-the-art performances on three new and challenging benchmark datasets CoDEx for knowledge graph completion.
ReGVD: Revisiting Graph Neural Networks for Vulnerability Detection
Oct 14, 2021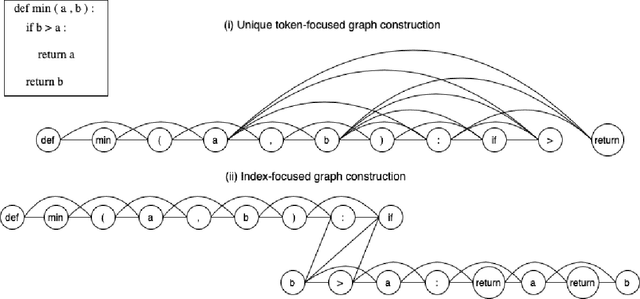
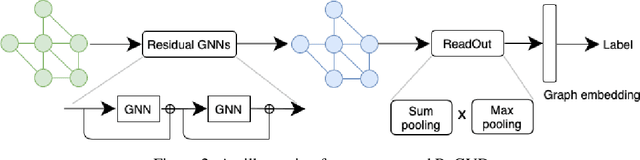
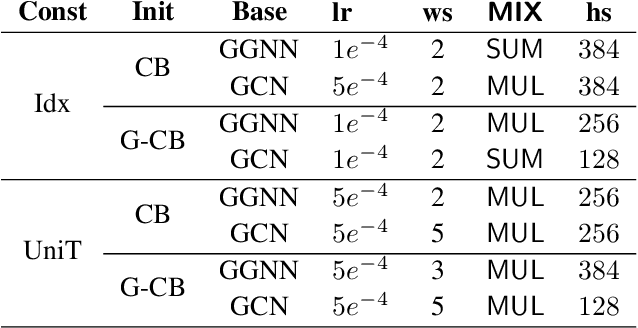
Identifying vulnerabilities in the source code is essential to protect the software systems from cyber security attacks. It, however, is also a challenging step that requires specialized expertise in security and code representation. Inspired by the successful applications of pre-trained programming language (PL) models such as CodeBERT and graph neural networks (GNNs), we propose ReGVD, a general and novel graph neural network-based model for vulnerability detection. In particular, ReGVD views a given source code as a flat sequence of tokens and then examines two effective methods of utilizing unique tokens and indexes respectively to construct a single graph as an input, wherein node features are initialized only by the embedding layer of a pre-trained PL model. Next, ReGVD leverages a practical advantage of residual connection among GNN layers and explores a beneficial mixture of graph-level sum and max poolings to return a graph embedding for the given source code. Experimental results demonstrate that ReGVD outperforms the existing state-of-the-art models and obtain the highest accuracy on the real-world benchmark dataset from CodeXGLUE for vulnerability detection.
Automatic Post-Editing for Translating Chinese Novels to Vietnamese
Apr 25, 2021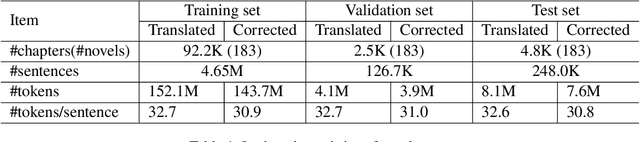
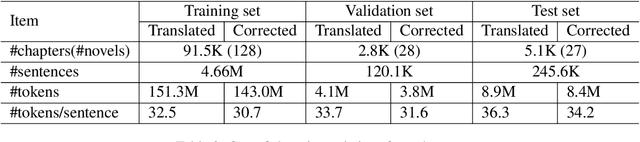
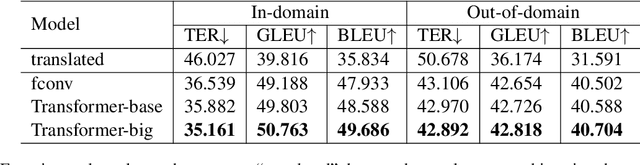
Automatic post-editing (APE) is an important remedy for reducing errors of raw translated texts that are produced by machine translation (MT) systems or software-aided translation. In this paper, we present the first attempt to tackle the APE task for Vietnamese. Specifically, we construct the first large-scale dataset of 5M Vietnamese translated and corrected sentence pairs. We then apply strong neural MT models to handle the APE task, using our constructed dataset. Experimental results from both automatic and human evaluations show the effectiveness of the neural MT models in handling the Vietnamese APE task.
Node Co-occurrence based Graph Neural Networks for Knowledge Graph Link Prediction
Apr 15, 2021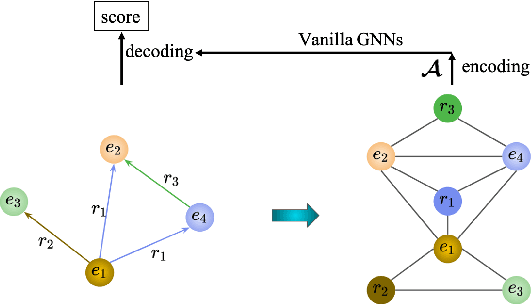
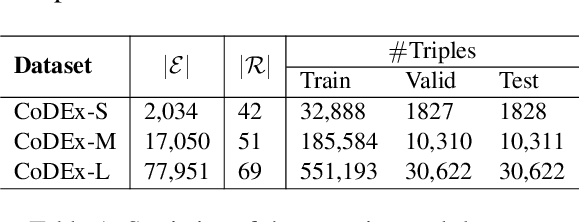
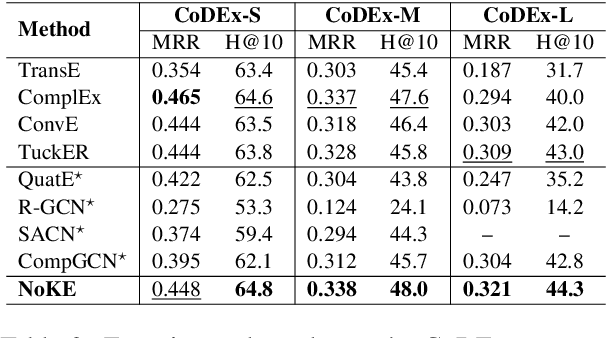
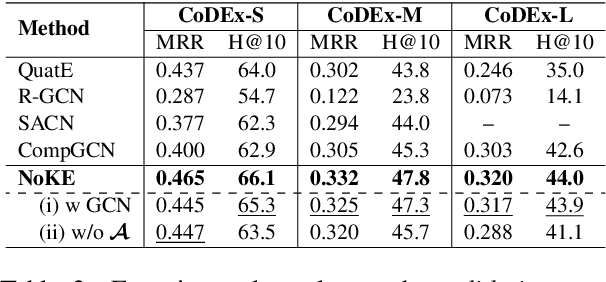
We introduce a novel embedding model, named NoKE, which aims to integrate co-occurrence among entities and relations into graph neural networks to improve knowledge graph completion (i.e., link prediction). Given a knowledge graph, NoKE constructs a single graph considering entities and relations as individual nodes. NoKE then computes weights for edges among nodes based on the co-occurrence of entities and relations. Next, NoKE utilizes vanilla GNNs to update vector representations for entity and relation nodes and then adopts a score function to produce the triple scores. Comprehensive experimental results show that our NoKE obtains state-of-the-art results on three new, challenging, and difficult benchmark datasets CoDEx for knowledge graph completion, demonstrating the power of its simplicity and effectiveness.
QuatRE: Relation-Aware Quaternions for Knowledge Graph Embeddings
Sep 26, 2020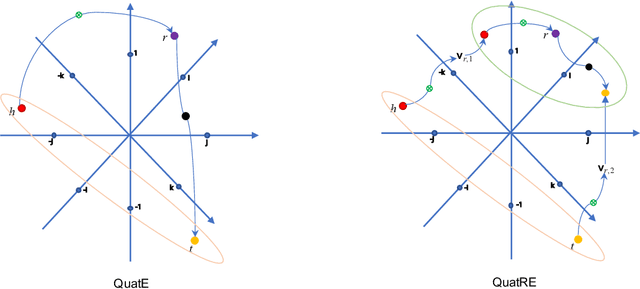
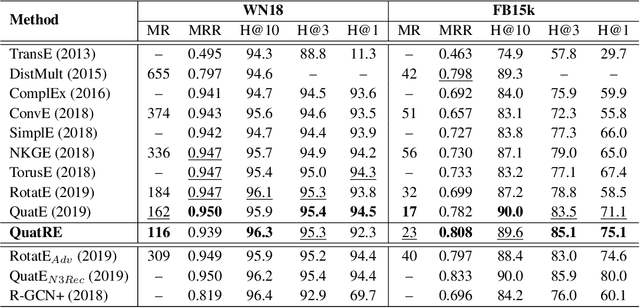
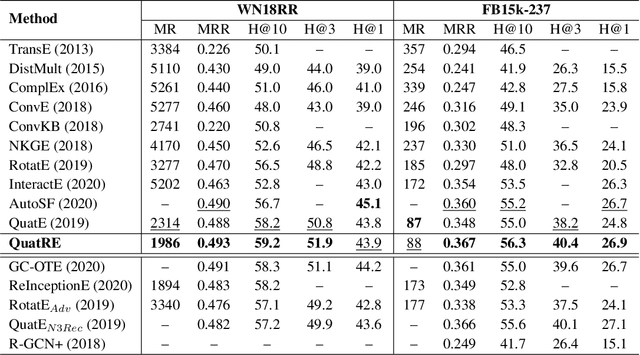
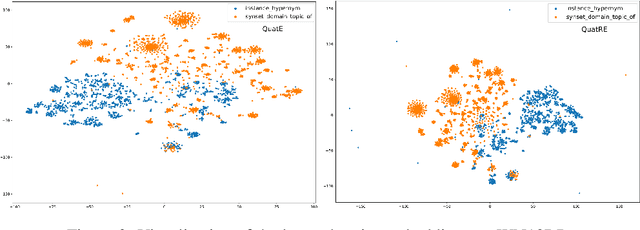
We propose a simple and effective embedding model, named QuatRE, to learn quaternion embeddings for entities and relations in knowledge graphs. QuatRE aims to enhance correlations between head and tail entities given a relation within the Quaternion space with Hamilton product. QuatRE achieves this by associating each relation with two quaternion vectors which are used to rotate the quaternion embeddings of the head and tail entities, respectively. To obtain the triple score, QuatRE rotates the rotated embedding of the head entity using the normalized quaternion embedding of the relation, followed by a quaternion-inner product with the rotated embedding of the tail entity. Experimental results show that our QuatRE outperforms up-to-date embedding models on well-known benchmark datasets for knowledge graph completion.
Quaternion Graph Neural Networks
Aug 12, 2020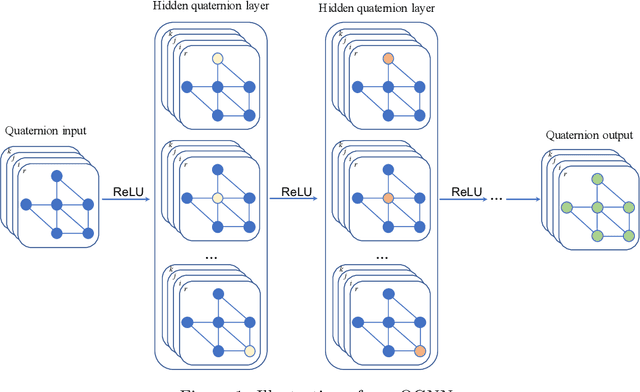
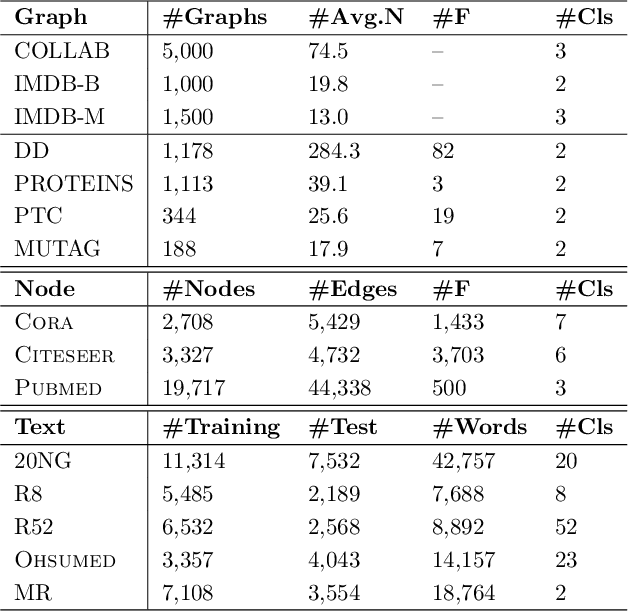
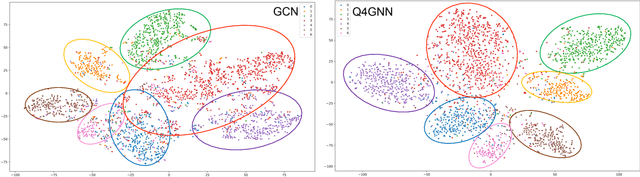
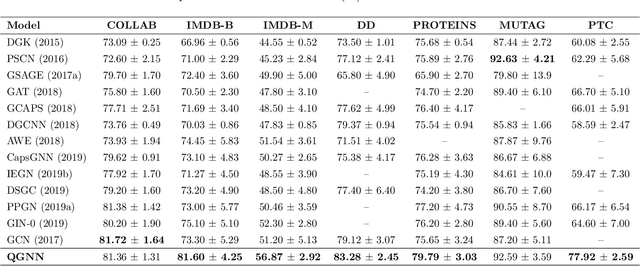
We consider reducing model parameters and moving beyond the Euclidean space to a hyper-complex space in graph neural networks (GNNs). To this end, we utilize the Quaternion space to learn quaternion node and graph embeddings. The Quaternion space, a hyper-complex space, provides highly meaningful computations through Hamilton product compared to the Euclidean and complex spaces. In particular, we propose QGNN -- a new architecture for graph neural networks which is a generalization of GCNs within the Quaternion space. QGNN reduces the model size up to four times and enhances learning graph representations. Experimental results show that our proposed QGNN produces state-of-the-art performances on a range of benchmark datasets for three downstream tasks, including graph classification, semi-supervised node classification, and text classification.
A Self-Attention Network based Node Embedding Model
Jun 22, 2020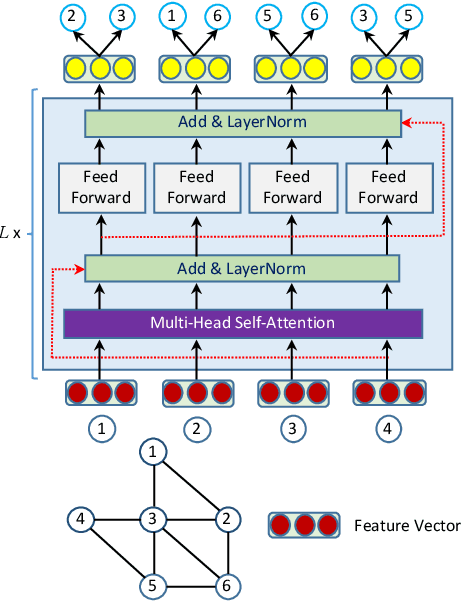

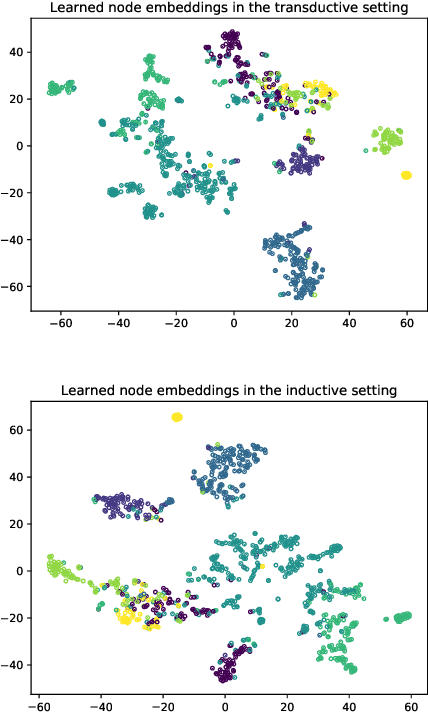
Despite several signs of progress have been made recently, limited research has been conducted for an inductive setting where embeddings are required for newly unseen nodes -- a setting encountered commonly in practical applications of deep learning for graph networks. This significantly affects the performances of downstream tasks such as node classification, link prediction or community extraction. To this end, we propose SANNE -- a novel unsupervised embedding model -- whose central idea is to employ a transformer self-attention network to iteratively aggregate vector representations of nodes in random walks. Our SANNE aims to produce plausible embeddings not only for present nodes, but also for newly unseen nodes. Experimental results show that the proposed SANNE obtains state-of-the-art results for the node classification task on well-known benchmark datasets.
A Vietnamese Text-Based Conversational Agent
Nov 26, 2019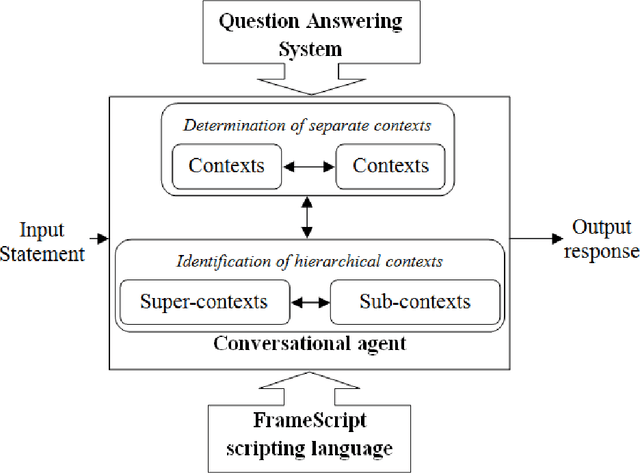


This paper introduces a Vietnamese text-based conversational agent architecture on specific knowledge domain which is integrated in a question answering system. When the question answering system fails to provide answers to users' input, our conversational agent can step in to interact with users to provide answers to users. Experimental results are promising where our Vietnamese text-based conversational agent achieves positive feedback in a study conducted in the university academic regulation domain.