Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Post-Editing for Translating Chinese Novels to Vietnamese
Paper and Code
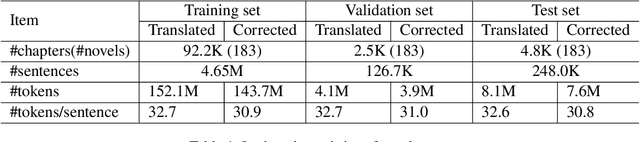
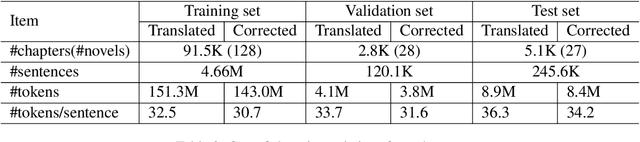
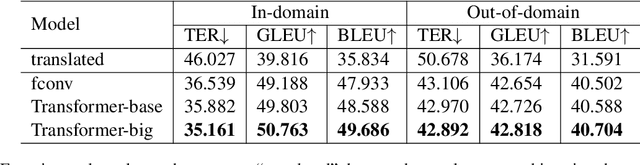
Automatic post-editing (APE) is an important remedy for reducing errors of raw translated texts that are produced by machine translation (MT) systems or software-aided translation. In this paper, we present the first attempt to tackle the APE task for Vietnamese. Specifically, we construct the first large-scale dataset of 5M Vietnamese translated and corrected sentence pairs. We then apply strong neural MT models to handle the APE task, using our constructed dataset. Experimental results from both automatic and human evaluations show the effectiveness of the neural MT models in handling the Vietnamese APE task.
View paper on