 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill-C: Enhanced NL2SQL via Distilled Customization with LLMs
Mar 30, 2025The growing adoption of large language models (LLMs) in business applications has amplified interest in Natural Language to SQL (NL2SQL) solutions, in which there is competing demand for high performance and efficiency. Domain- and customer-specific requirements further complicate the problem. To address this conundrum, we introduce Distill-C, a distilled customization framework tailored for NL2SQL tasks. Distill-C utilizes large teacher LLMs to produce high-quality synthetic data through a robust and scalable pipeline. Finetuning smaller and open-source LLMs on this synthesized data enables them to rival or outperform teacher models an order of magnitude larger. Evaluated on multiple challenging benchmarks, Distill-C achieves an average improvement of 36% in execution accuracy compared to the base models from three distinct LLM families. Additionally, on three internal customer benchmarks, Distill-C demonstrates a 22.6% performance improvement over the base models. Our results demonstrate that Distill-C is an effective, high-performing and generalizable approach for deploying lightweight yet powerful NL2SQL models, delivering exceptional accuracies while maintaining low computational cost.
SQLong: Enhanced NL2SQL for Longer Contexts with LLMs
Feb 23, 2025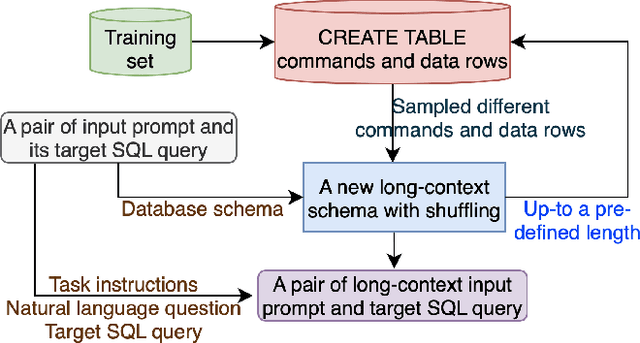
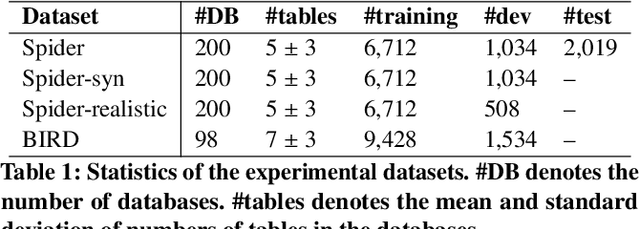

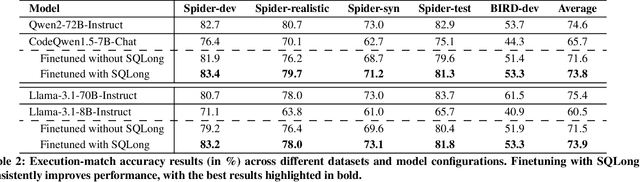
Open-weight large language models (LLMs) have significantly advanced performance in the Natural Language to SQL (NL2SQL) task. However, their effectiveness diminishes when dealing with large database schemas, as the context length increases. To address this limitation, we present SQLong, a novel and efficient data augmentation framework designed to enhance LLM performance in long-context scenarios for the NL2SQL task. SQLong generates augmented datasets by extending existing database schemas with additional synthetic CREATE TABLE commands and corresponding data rows, sampled from diverse schemas in the training data. This approach effectively simulates long-context scenarios during finetuning and evaluation. Through experiments on the Spider and BIRD datasets, we demonstrate that LLMs finetuned with SQLong-augmented data significantly outperform those trained on standard datasets. These imply SQLong's practical implementation and its impact on improving NL2SQL capabilities in real-world settings with complex database schemas.
Moment Matching Training for Neural Machine Translation: A Preliminary Study
Dec 28, 2018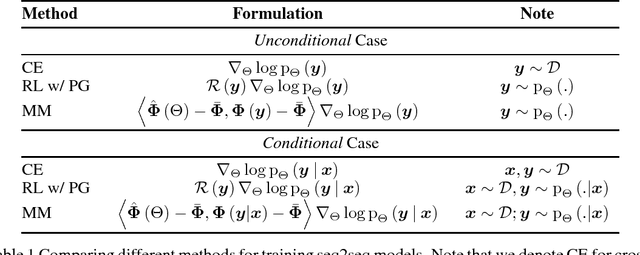


In previous works, neural sequence models have been shown to improve significantly if external prior knowledge can be provided, for instance by allowing the model to access the embeddings of explicit features during both training and inference. In this work, we propose a different point of view on how to incorporate prior knowledge in a principled way, using a moment matching framework. In this approach, the standard local cross-entropy training of the sequential model is combined with a moment matching training mode that encourages the equality of the expectations of certain predefined features between the model distribution and the empirical distribution. In particular, we show how to derive unbiased estimates of some stochastic gradients that are central to the training, and compare our framework with a formally related one: policy gradient training in reinforcement learning, pointing out some important differences in terms of the kinds of prior assumptions in both approaches. Our initial results are promising, showing the effectiveness of our proposed framework.
Towards Decoding as Continuous Optimization in Neural Machine Translation
Jul 22, 2017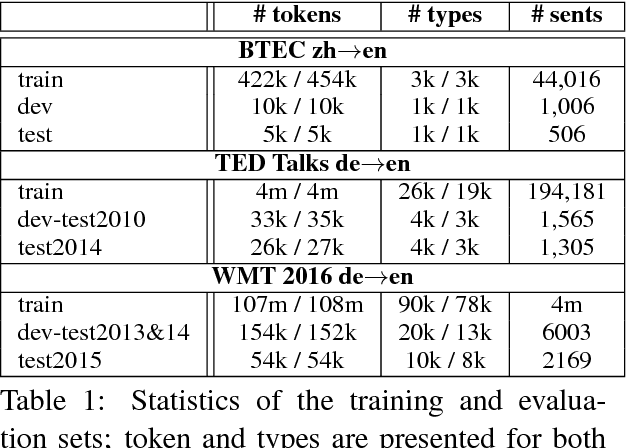
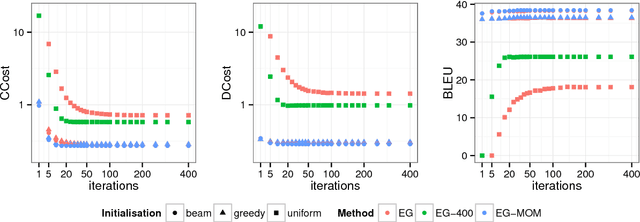


We propose a novel decoding approach for neural machine translation (NMT) based on continuous optimisation. We convert decoding - basically a discrete optimization problem - into a continuous optimization problem. The resulting constrained continuous optimisation problem is then tackled using gradient-based methods. Our powerful decoding framework enables decoding intractable models such as the intersection of left-to-right and right-to-left (bidirectional) as well as source-to-target and target-to-source (bilingual) NMT models. Our empirical results show that our decoding framework is effective, and leads to substantial improvements in translations generated from the intersected models where the typical greedy or beam search is not feasible. We also compare our framework against reranking, and analyse its advantages and disadvantages.
Incorporating Structural Alignment Biases into an Attentional Neural Translation Model
Jan 06, 2016
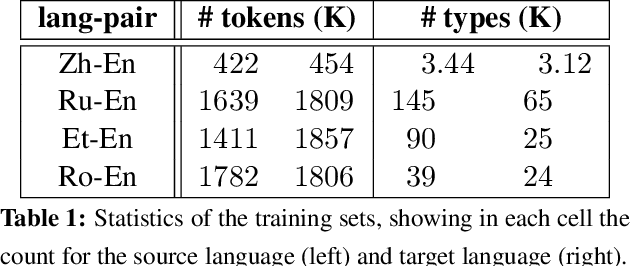
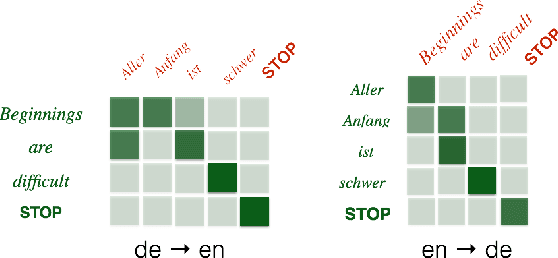

Neural encoder-decoder models of machine translation have achieved impressive results, rivalling traditional translation models. However their modelling formulation is overly simplistic, and omits several key inductive biases built into traditional models. In this paper we extend the attentional neural translation model to include structural biases from word based alignment models, including positional bias, Markov conditioning, fertility and agreement over translation directions. We show improvements over a baseline attentional model and standard phrase-based model over several language pairs, evaluating on difficult languages in a low resource setting.