 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill-C: Enhanced NL2SQL via Distilled Customization with LLMs
Mar 30, 2025The growing adoption of large language models (LLMs) in business applications has amplified interest in Natural Language to SQL (NL2SQL) solutions, in which there is competing demand for high performance and efficiency. Domain- and customer-specific requirements further complicate the problem. To address this conundrum, we introduce Distill-C, a distilled customization framework tailored for NL2SQL tasks. Distill-C utilizes large teacher LLMs to produce high-quality synthetic data through a robust and scalable pipeline. Finetuning smaller and open-source LLMs on this synthesized data enables them to rival or outperform teacher models an order of magnitude larger. Evaluated on multiple challenging benchmarks, Distill-C achieves an average improvement of 36% in execution accuracy compared to the base models from three distinct LLM families. Additionally, on three internal customer benchmarks, Distill-C demonstrates a 22.6% performance improvement over the base models. Our results demonstrate that Distill-C is an effective, high-performing and generalizable approach for deploying lightweight yet powerful NL2SQL models, delivering exceptional accuracies while maintaining low computational cost.
Polarization Angle Scanning for Wide-band Millimeter-wave Direct Detection
Feb 26, 2025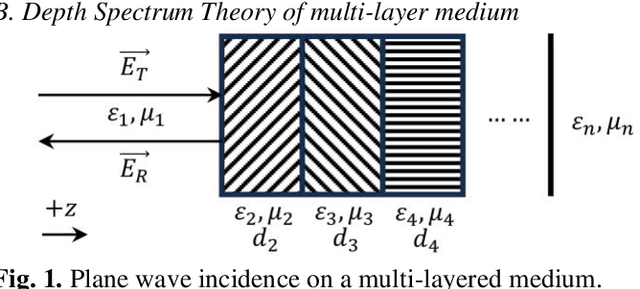
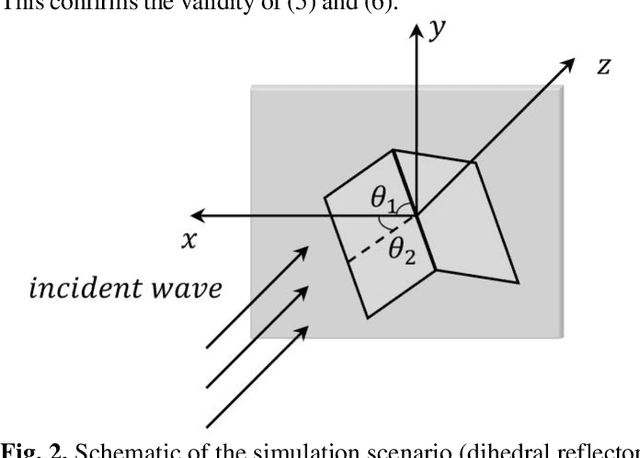
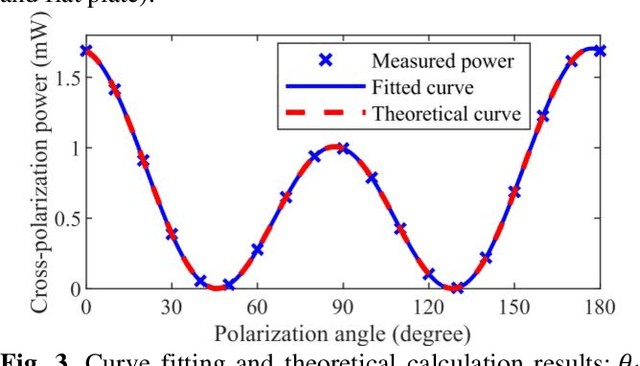
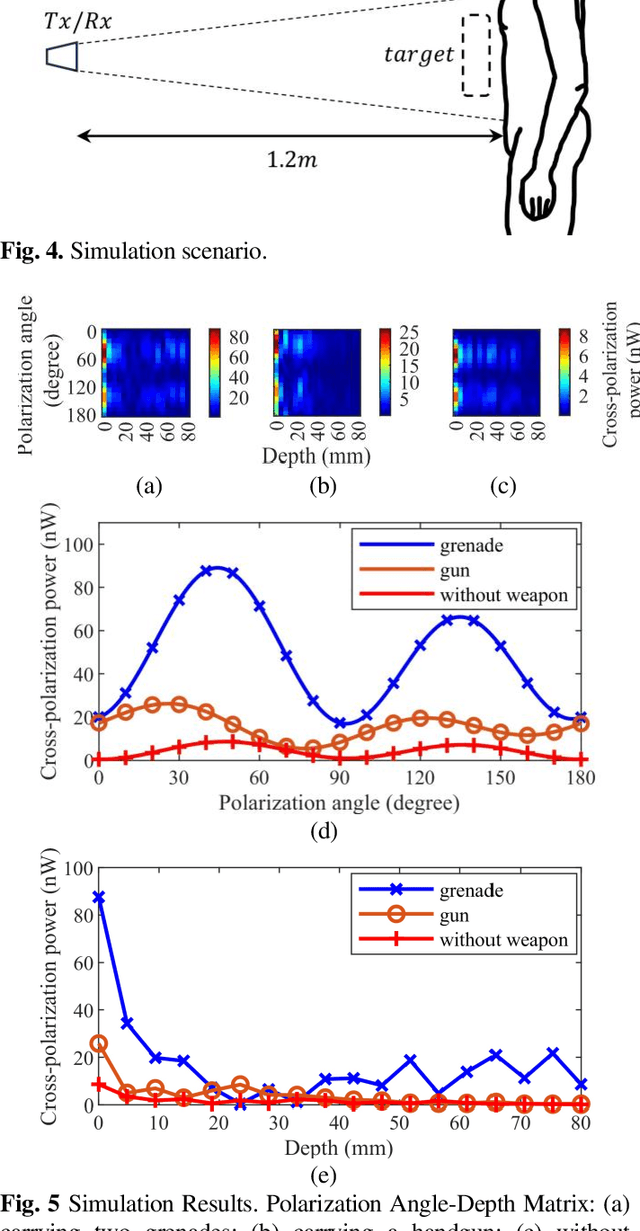
Millimeter-wave (MMW) technology has been widely utilized in human security screening applications due to its superior penetration capabilities through clothing and safety for human exposure. However, existing methods largely rely on fixed polarization modes, neglecting the potential insights from variations in target echoes with respect to incident polarization. This study provides a theoretical analysis of the cross-polarization echo power as a function of the incident polarization angle under linear polarization conditions. Additionally, based on the transmission characteristics of multi-layer medium, we extended the depth spectrum model employed in direct detection to accommodate scenarios involving multi-layered structures. Building on this foundation, by obtaining multiple depth spectrums through polarization angle scanning, we propose the Polarization Angle-Depth Matrix to characterize target across both the polarization angle and depth dimensions in direct detection. Simulations and experimental validations confirm its accuracy and practical value in detecting concealed weapons in human security screening scenarios.
Learning Compositional Representation for Few-shot Visual Question Answering
Feb 21, 2021

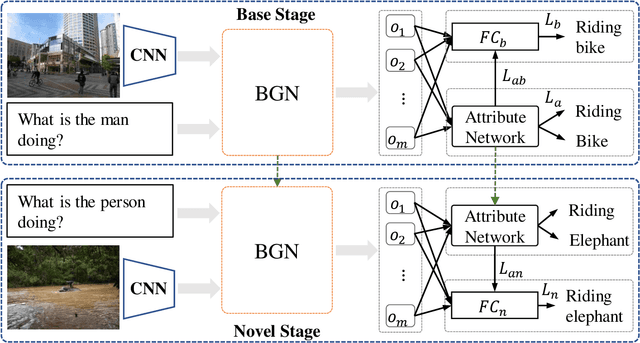

Current methods of Visual Question Answering perform well on the answers with an amount of training data but have limited accuracy on the novel ones with few examples. However, humans can quickly adapt to these new categories with just a few glimpses, as they learn to organize the concepts that have been seen before to figure the novel class, which are hardly explored by the deep learning methods. Therefore, in this paper, we propose to extract the attributes from the answers with enough data, which are later composed to constrain the learning of the few-shot ones. We generate the few-shot dataset of VQA with a variety of answers and their attributes without any human effort. With this dataset, we build our attribute network to disentangle the attributes by learning their features from parts of the image instead of the whole one. Experimental results on the VQA v2.0 validation dataset demonstrate the effectiveness of our proposed attribute network and the constraint between answers and their corresponding attributes, as well as the ability of our method to handle the answers with few training examples.
Graph Reasoning Networks for Visual Question Answering
Jul 23, 2019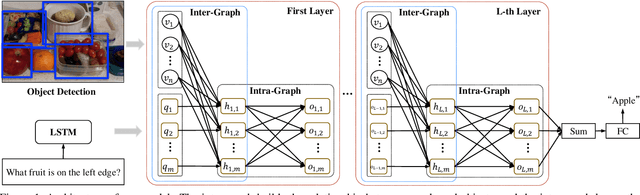


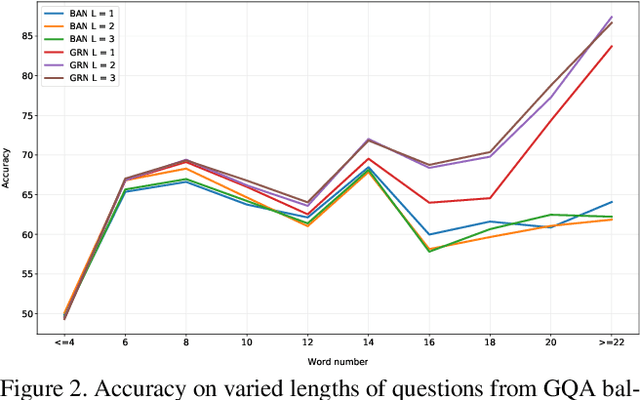
The interaction between language and visual information has been emphasized in visual question answering (VQA) with the help of attention mechanism. However, the relationship between words in question has been underestimated, which makes it hard to answer questions that involve the relationship between multiple entities, such as comparison and counting. In this paper, we develop the graph reasoning networks to tackle this problem. Two kinds of graphs are investigated, namely inter-graph and intra-graph. The inter-graph transfers features of the detected objects to their related query words, enabling the output nodes to have both semantic and factual information. The intra-graph exchanges information between these output nodes from inter-graph to amplify implicit yet important relationship between objects. These two kinds of graphs cooperate with each other, and thus our resulting model can reason the relationship and dependence between objects, which leads to realization of multi-step reasoning. Experimental results on the GQA v1.1 dataset demonstrate the reasoning ability of our method to handle compositional questions about real-world images. We achieve state-of-the-art performance, boosting accuracy to 57.04%. On the VQA 2.0 dataset, we also receive a promising improvement on overall accuracy, especially on counting problem.
Image-Question-Answer Synergistic Network for Visual Dialog
Feb 26, 2019


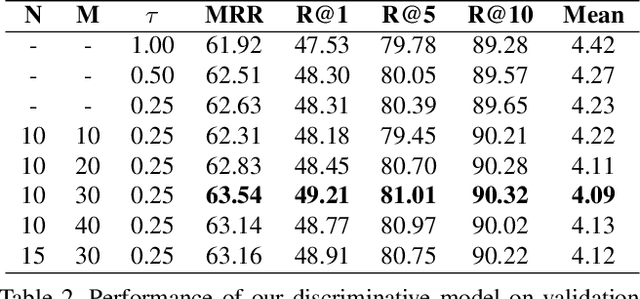
The image, question (combined with the history for de-referencing), and the corresponding answer are three vital components of visual dialog. Classical visual dialog systems integrate the image, question, and history to search for or generate the best matched answer, and so, this approach significantly ignores the role of the answer. In this paper, we devise a novel image-question-answer synergistic network to value the role of the answer for precise visual dialog. We extend the traditional one-stage solution to a two-stage solution. In the first stage, candidate answers are coarsely scored according to their relevance to the image and question pair. Afterward, in the second stage, answers with high probability of being correct are re-ranked by synergizing with image and question. On the Visual Dialog v1.0 dataset, the proposed synergistic network boosts the discriminative visual dialog model to achieve a new state-of-the-art of 57.88\% normalized discounted cumulative gain. A generative visual dialog model equipped with the proposed technique also shows promising improvements.