 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill-C: Enhanced NL2SQL via Distilled Customization with LLMs
Mar 30, 2025The growing adoption of large language models (LLMs) in business applications has amplified interest in Natural Language to SQL (NL2SQL) solutions, in which there is competing demand for high performance and efficiency. Domain- and customer-specific requirements further complicate the problem. To address this conundrum, we introduce Distill-C, a distilled customization framework tailored for NL2SQL tasks. Distill-C utilizes large teacher LLMs to produce high-quality synthetic data through a robust and scalable pipeline. Finetuning smaller and open-source LLMs on this synthesized data enables them to rival or outperform teacher models an order of magnitude larger. Evaluated on multiple challenging benchmarks, Distill-C achieves an average improvement of 36% in execution accuracy compared to the base models from three distinct LLM families. Additionally, on three internal customer benchmarks, Distill-C demonstrates a 22.6% performance improvement over the base models. Our results demonstrate that Distill-C is an effective, high-performing and generalizable approach for deploying lightweight yet powerful NL2SQL models, delivering exceptional accuracies while maintaining low computational cost.
SQLong: Enhanced NL2SQL for Longer Contexts with LLMs
Feb 23, 2025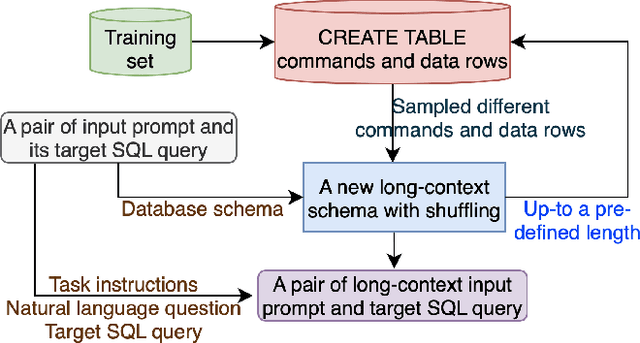
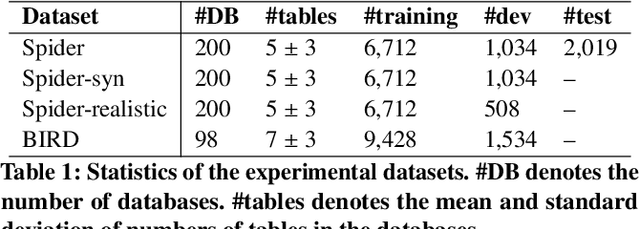

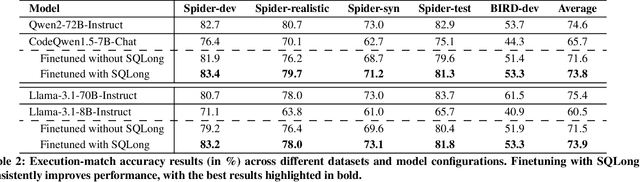
Open-weight large language models (LLMs) have significantly advanced performance in the Natural Language to SQL (NL2SQL) task. However, their effectiveness diminishes when dealing with large database schemas, as the context length increases. To address this limitation, we present SQLong, a novel and efficient data augmentation framework designed to enhance LLM performance in long-context scenarios for the NL2SQL task. SQLong generates augmented datasets by extending existing database schemas with additional synthetic CREATE TABLE commands and corresponding data rows, sampled from diverse schemas in the training data. This approach effectively simulates long-context scenarios during finetuning and evaluation. Through experiments on the Spider and BIRD datasets, we demonstrate that LLMs finetuned with SQLong-augmented data significantly outperform those trained on standard datasets. These imply SQLong's practical implementation and its impact on improving NL2SQL capabilities in real-world settings with complex database schemas.