 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoment Matching Training for Neural Machine Translation: A Preliminary Study
Paper and Code
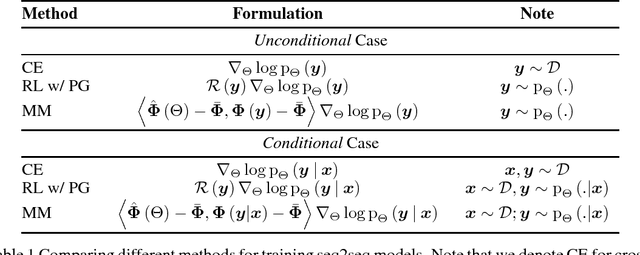


In previous works, neural sequence models have been shown to improve significantly if external prior knowledge can be provided, for instance by allowing the model to access the embeddings of explicit features during both training and inference. In this work, we propose a different point of view on how to incorporate prior knowledge in a principled way, using a moment matching framework. In this approach, the standard local cross-entropy training of the sequential model is combined with a moment matching training mode that encourages the equality of the expectations of certain predefined features between the model distribution and the empirical distribution. In particular, we show how to derive unbiased estimates of some stochastic gradients that are central to the training, and compare our framework with a formally related one: policy gradient training in reinforcement learning, pointing out some important differences in terms of the kinds of prior assumptions in both approaches. Our initial results are promising, showing the effectiveness of our proposed framework.