 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting Cross-language Cross-project Bug Localization Using Pre-trained Language Models
Jul 03, 2024Automatically locating a bug within a large codebase remains a significant challenge for developers. Existing techniques often struggle with generalizability and deployment due to their reliance on application-specific data and large model sizes. This paper proposes a novel pre-trained language model (PLM) based technique for bug localization that transcends project and language boundaries. Our approach leverages contrastive learning to enhance the representation of bug reports and source code. It then utilizes a novel ranking approach that combines commit messages and code segments. Additionally, we introduce a knowledge distillation technique that reduces model size for practical deployment without compromising performance. This paper presents several key benefits. By incorporating code segment and commit message analysis alongside traditional file-level examination, our technique achieves better bug localization accuracy. Furthermore, our model excels at generalizability - trained on code from various projects and languages, it can effectively identify bugs in unseen codebases. To address computational limitations, we propose a CPU-compatible solution. In essence, proposed work presents a highly effective, generalizable, and efficient bug localization technique with the potential to real-world deployment.
graph2vec: Learning Distributed Representations of Graphs
Jul 17, 2017
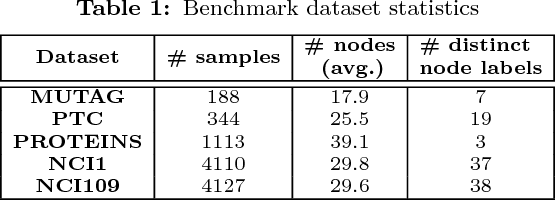
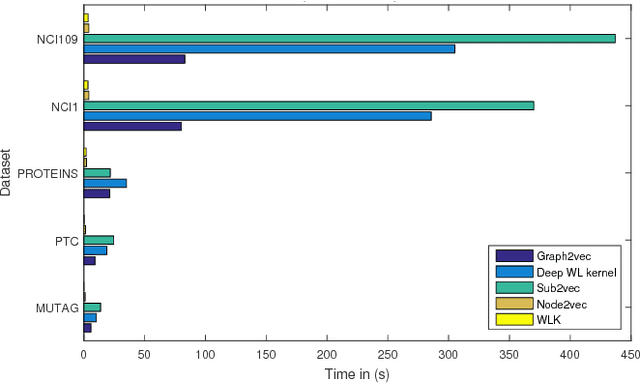

Recent works on representation learning for graph structured data predominantly focus on learning distributed representations of graph substructures such as nodes and subgraphs. However, many graph analytics tasks such as graph classification and clustering require representing entire graphs as fixed length feature vectors. While the aforementioned approaches are naturally unequipped to learn such representations, graph kernels remain as the most effective way of obtaining them. However, these graph kernels use handcrafted features (e.g., shortest paths, graphlets, etc.) and hence are hampered by problems such as poor generalization. To address this limitation, in this work, we propose a neural embedding framework named graph2vec to learn data-driven distributed representations of arbitrary sized graphs. graph2vec's embeddings are learnt in an unsupervised manner and are task agnostic. Hence, they could be used for any downstream task such as graph classification, clustering and even seeding supervised representation learning approaches. Our experiments on several benchmark and large real-world datasets show that graph2vec achieves significant improvements in classification and clustering accuracies over substructure representation learning approaches and are competitive with state-of-the-art graph kernels.
Context-aware, Adaptive and Scalable Android Malware Detection through Online Learning (extended version)
Jul 06, 2017



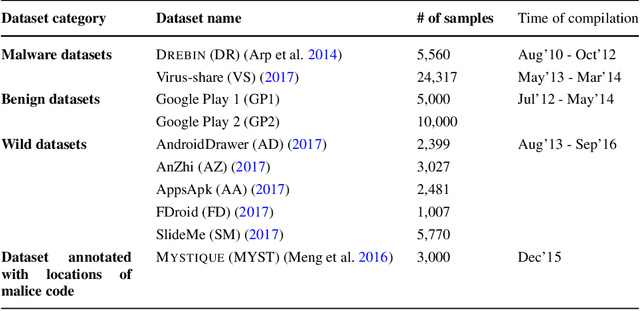
It is well-known that Android malware constantly evolves so as to evade detection. This causes the entire malware population to be non-stationary. Contrary to this fact, most of the prior works on Machine Learning based Android malware detection have assumed that the distribution of the observed malware characteristics (i.e., features) does not change over time. In this work, we address the problem of malware population drift and propose a novel online learning based framework to detect malware, named CASANDRA (Contextaware, Adaptive and Scalable ANDRoid mAlware detector). In order to perform accurate detection, a novel graph kernel that facilitates capturing apps' security-sensitive behaviors along with their context information from dependency graphs is proposed. Besides being accurate and scalable, CASANDRA has specific advantages: i) being adaptive to the evolution in malware features over time ii) explaining the significant features that led to an app's classification as being malicious or benign. In a large-scale comparative analysis, CASANDRA outperforms two state-of-the-art techniques on a benchmark dataset achieving 99.23% F-measure. When evaluated with more than 87,000 apps collected in-the-wild, CASANDRA achieves 89.92% accuracy, outperforming existing techniques by more than 25% in their typical batch learning setting and more than 7% when they are continuously retained, while maintaining comparable efficiency.
A Multi-view Context-aware Approach to Android Malware Detection and Malicious Code Localization
Apr 08, 2017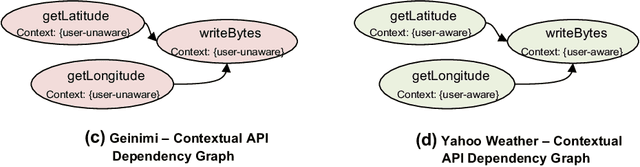
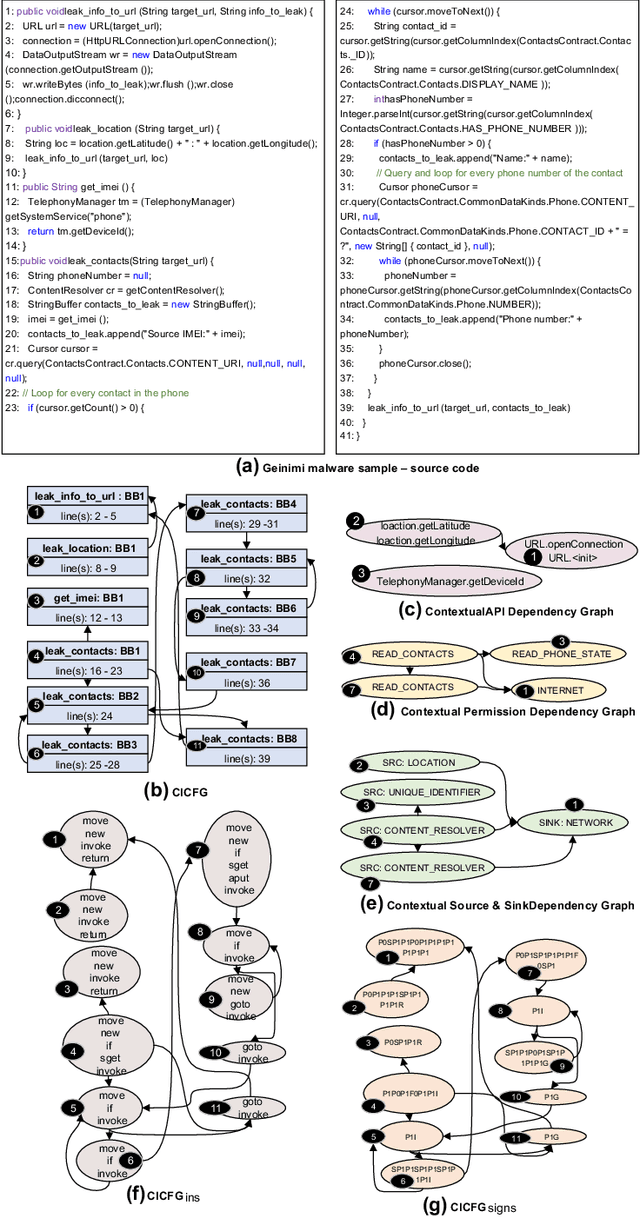
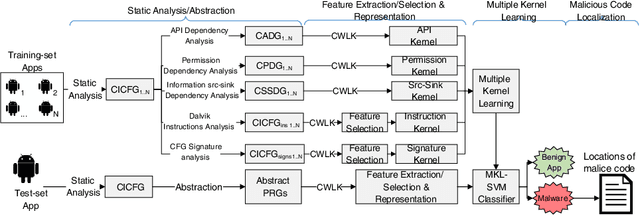
Existing Android malware detection approaches use a variety of features such as security sensitive APIs, system calls, control-flow structures and information flows in conjunction with Machine Learning classifiers to achieve accurate detection. Each of these feature sets provides a unique semantic perspective (or view) of apps' behaviours with inherent strengths and limitations. Meaning, some views are more amenable to detect certain attacks but may not be suitable to characterise several other attacks. Most of the existing malware detection approaches use only one (or a selected few) of the aforementioned feature sets which prevent them from detecting a vast majority of attacks. Addressing this limitation, we propose MKLDroid, a unified framework that systematically integrates multiple views of apps for performing comprehensive malware detection and malicious code localisation. The rationale is that, while a malware app can disguise itself in some views, disguising in every view while maintaining malicious intent will be much harder. MKLDroid uses a graph kernel to capture structural and contextual information from apps' dependency graphs and identify malice code patterns in each view. Subsequently, it employs Multiple Kernel Learning (MKL) to find a weighted combination of the views which yields the best detection accuracy. Besides multi-view learning, MKLDroid's unique and salient trait is its ability to locate fine-grained malice code portions in dependency graphs (e.g., methods/classes). Through our large-scale experiments on several datasets (incl. wild apps), we demonstrate that MKLDroid outperforms three state-of-the-art techniques consistently, in terms of accuracy while maintaining comparable efficiency. In our malicious code localisation experiments on a dataset of repackaged malware, MKLDroid was able to identify all the malice classes with 94% average recall.
subgraph2vec: Learning Distributed Representations of Rooted Sub-graphs from Large Graphs
Jun 29, 2016


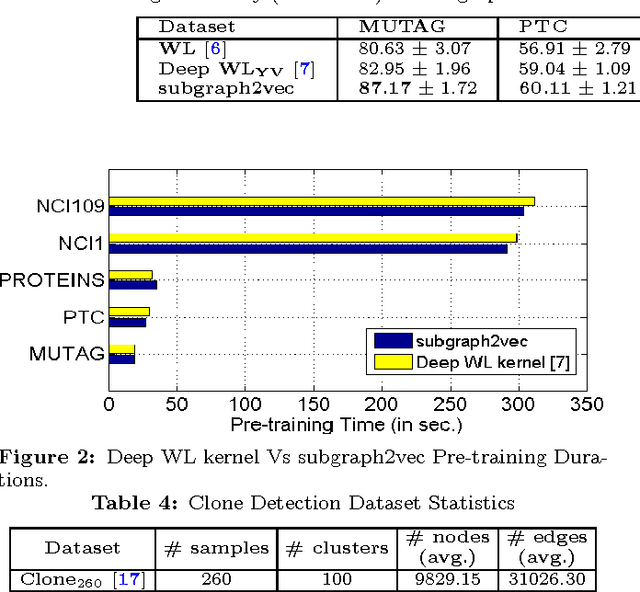
In this paper, we present subgraph2vec, a novel approach for learning latent representations of rooted subgraphs from large graphs inspired by recent advancements in Deep Learning and Graph Kernels. These latent representations encode semantic substructure dependencies in a continuous vector space, which is easily exploited by statistical models for tasks such as graph classification, clustering, link prediction and community detection. subgraph2vec leverages on local information obtained from neighbourhoods of nodes to learn their latent representations in an unsupervised fashion. We demonstrate that subgraph vectors learnt by our approach could be used in conjunction with classifiers such as CNNs, SVMs and relational data clustering algorithms to achieve significantly superior accuracies. Also, we show that the subgraph vectors could be used for building a deep learning variant of Weisfeiler-Lehman graph kernel. Our experiments on several benchmark and large-scale real-world datasets reveal that subgraph2vec achieves significant improvements in accuracies over existing graph kernels on both supervised and unsupervised learning tasks. Specifically, on two realworld program analysis tasks, namely, code clone and malware detection, subgraph2vec outperforms state-of-the-art kernels by more than 17% and 4%, respectively.