 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Textual Representations for Citation Recommendation
Jul 08, 2020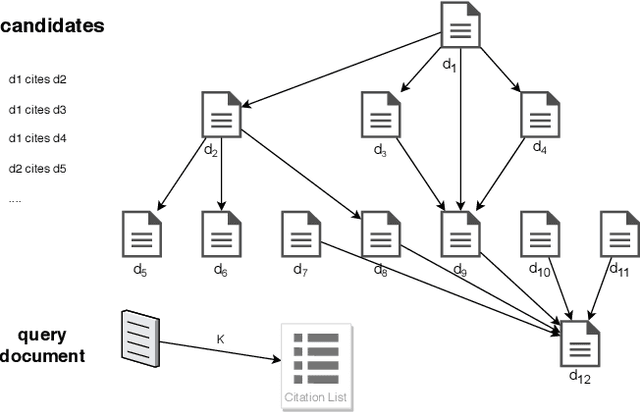
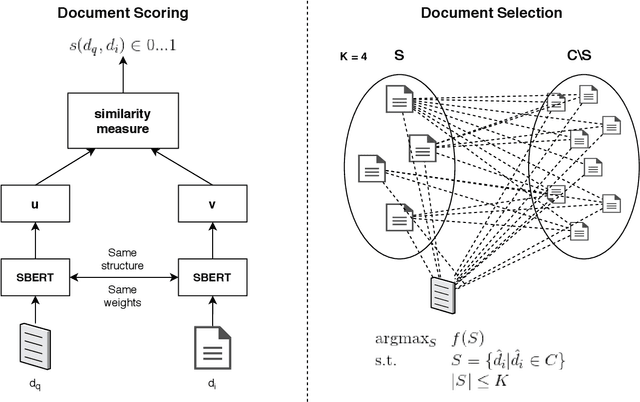
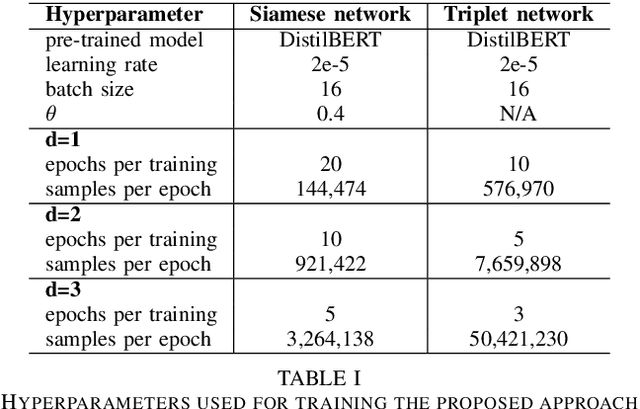
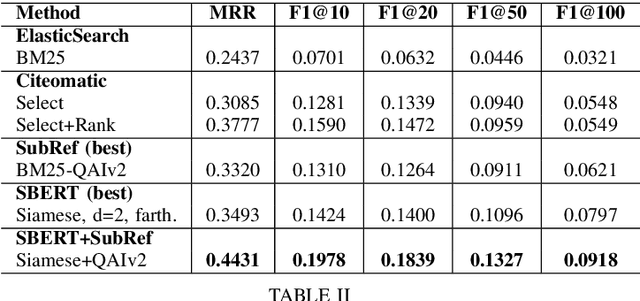
With the rapid growth of the scientific literature, manually selecting appropriate citations for a paper is becoming increasingly challenging and time-consuming. While several approaches for automated citation recommendation have been proposed in the recent years, effective document representations for citation recommendation are still elusive to a large extent. For this reason, in this paper we propose a novel approach to citation recommendation which leverages a deep sequential representation of the documents (Sentence-BERT) cascaded with Siamese and triplet networks in a submodular scoring function. To the best of our knowledge, this is the first approach to combine deep representations and submodular selection for a task of citation recommendation. Experiments have been carried out using a popular benchmark dataset - the ACL Anthology Network corpus - and evaluated against baselines and a state-of-the-art approach using metrics such as the MRR and F1-at-k score. The results show that the proposed approach has been able to outperform all the compared approaches in every measured metric.
A Vietnamese Text-Based Conversational Agent
Nov 26, 2019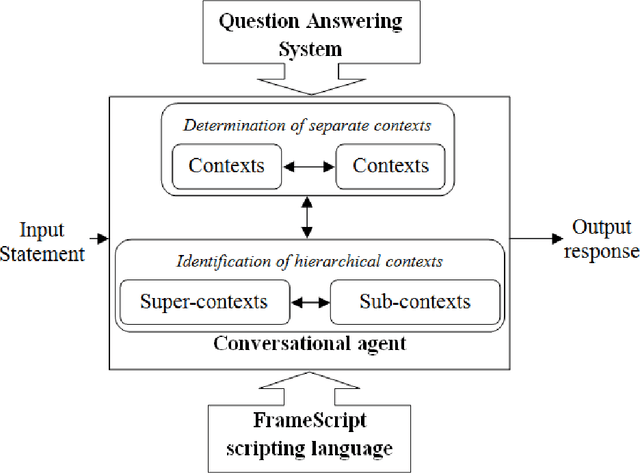


This paper introduces a Vietnamese text-based conversational agent architecture on specific knowledge domain which is integrated in a question answering system. When the question answering system fails to provide answers to users' input, our conversational agent can step in to interact with users to provide answers to users. Experimental results are promising where our Vietnamese text-based conversational agent achieves positive feedback in a study conducted in the university academic regulation domain.
A Vietnamese Question Answering System
Nov 26, 2019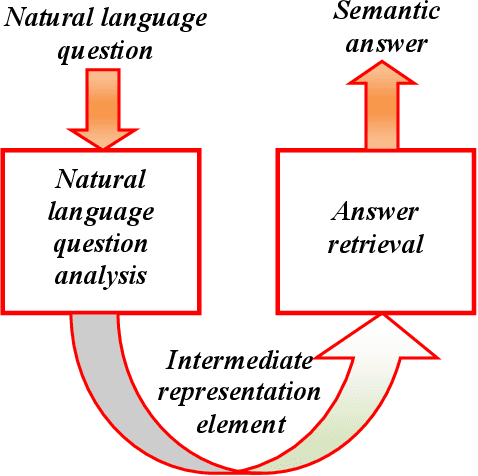
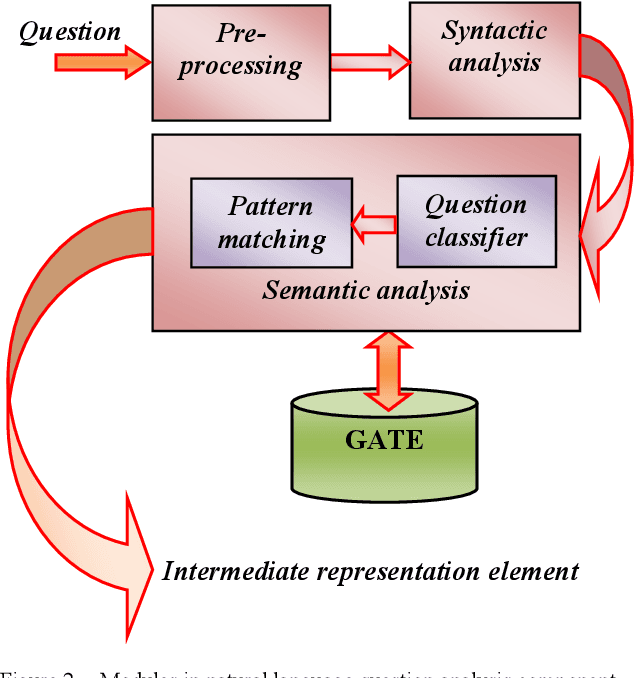
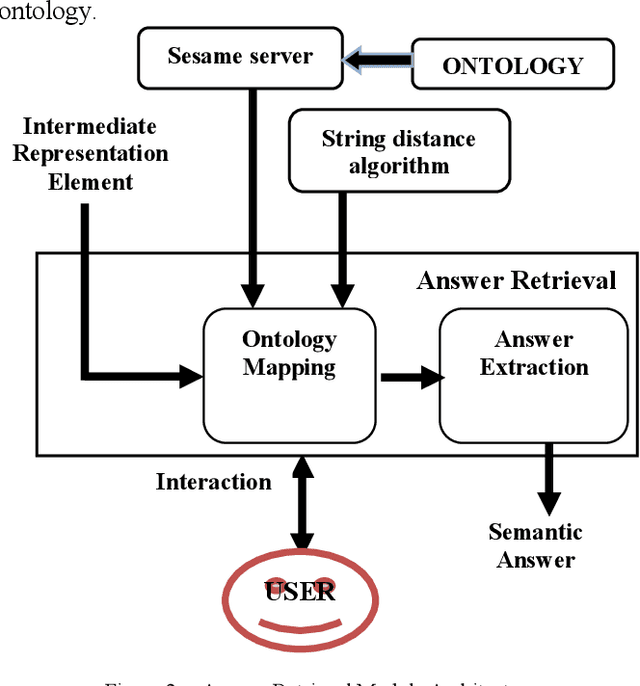
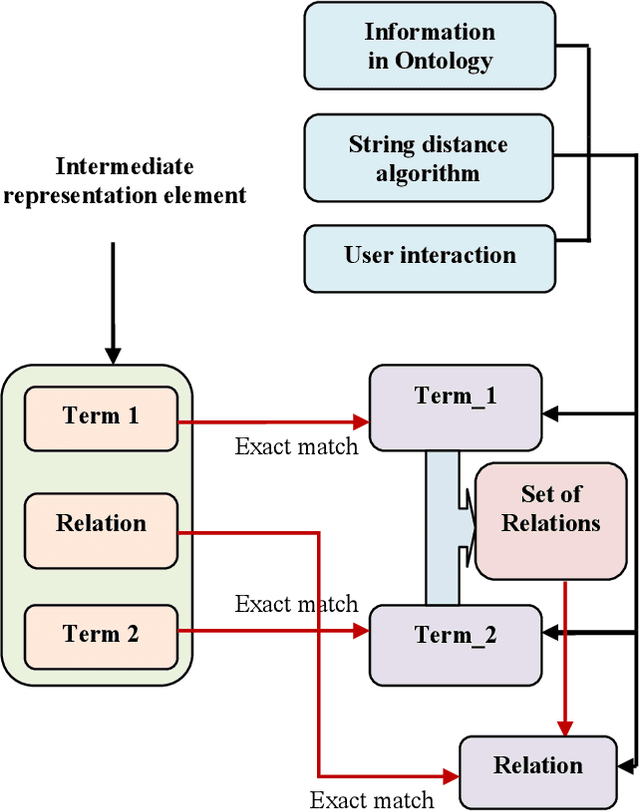
Question answering systems aim to produce exact answers to users' questions instead of a list of related documents as used by current search engines. In this paper, we propose an ontology-based Vietnamese question answering system that allows users to express their questions in natural language. To the best of our knowledge, this is the first attempt to enable users to query an ontological knowledge base using Vietnamese natural language. Experiments of our system on an organizational ontology show promising results.
Dialogue Act Segmentation for Vietnamese Human-Human Conversational Texts
Aug 16, 2017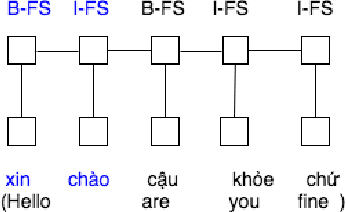
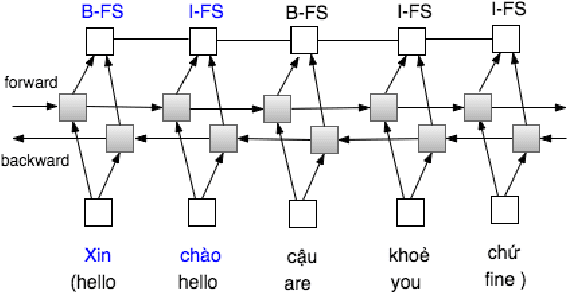
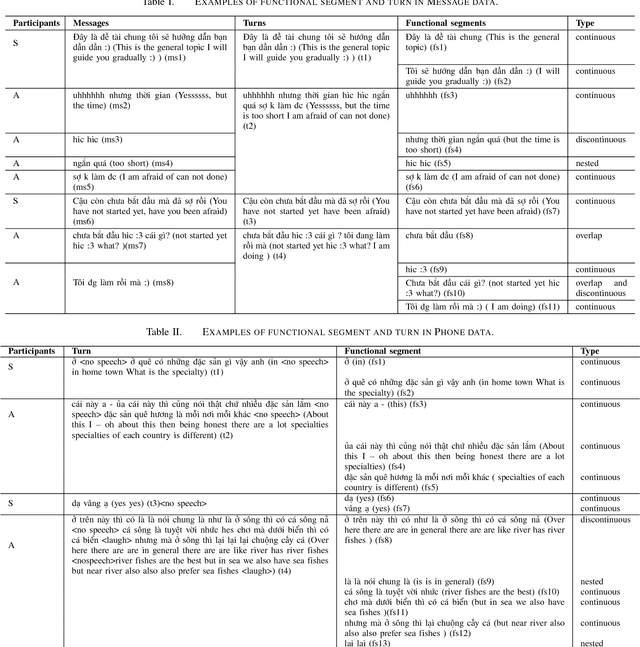
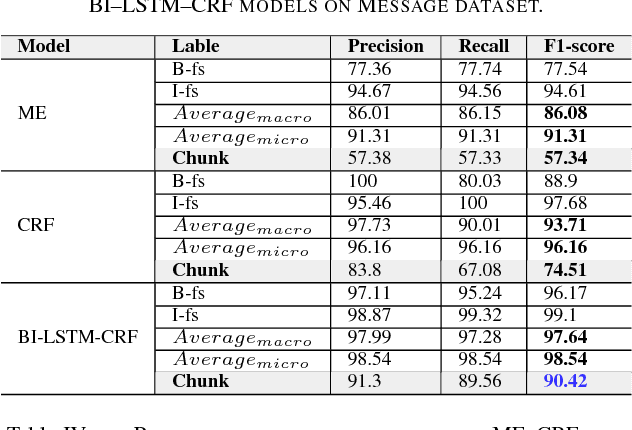
Dialog act identification plays an important role in understanding conversations. It has been widely applied in many fields such as dialogue systems, automatic machine translation, automatic speech recognition, and especially useful in systems with human-computer natural language dialogue interfaces such as virtual assistants and chatbots. The first step of identifying dialog act is identifying the boundary of the dialog act in utterances. In this paper, we focus on segmenting the utterance according to the dialog act boundaries, i.e. functional segments identification, for Vietnamese utterances. We investigate carefully functional segment identification in two approaches: (1) machine learning approach using maximum entropy (ME) and conditional random fields (CRFs); (2) deep learning approach using bidirectional Long Short-Term Memory (LSTM) with a CRF layer (Bi-LSTM-CRF) on two different conversational datasets: (1) Facebook messages (Message data); (2) transcription from phone conversations (Phone data). To the best of our knowledge, this is the first work that applies deep learning based approach to dialog act segmentation. As the results show, deep learning approach performs appreciably better as to compare with traditional machine learning approaches. Moreover, it is also the first study that tackles dialog act and functional segment identification for Vietnamese.
A Robust Transformation-Based Learning Approach Using Ripple Down Rules for Part-of-Speech Tagging
Dec 19, 2015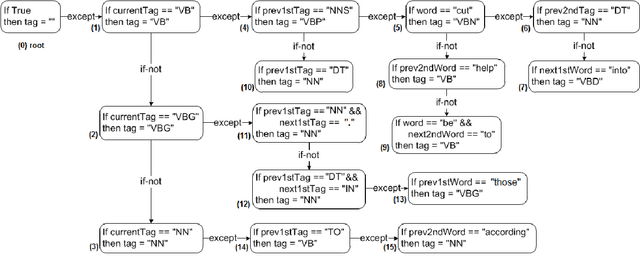

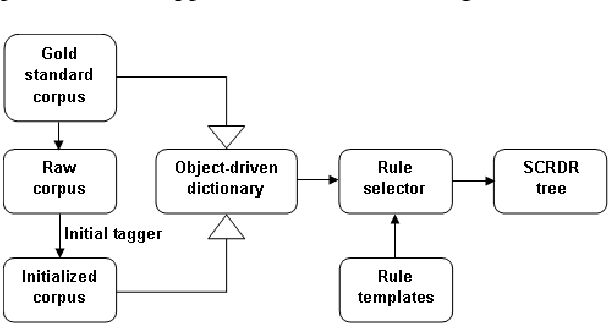
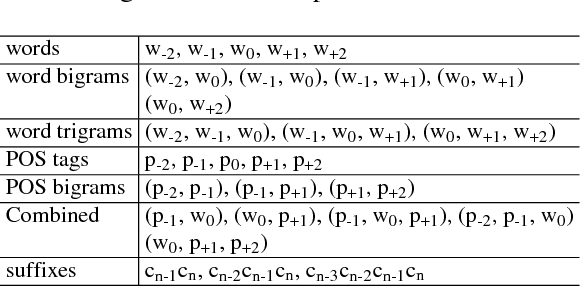
In this paper, we propose a new approach to construct a system of transformation rules for the Part-of-Speech (POS) tagging task. Our approach is based on an incremental knowledge acquisition method where rules are stored in an exception structure and new rules are only added to correct the errors of existing rules; thus allowing systematic control of the interaction between the rules. Experimental results on 13 languages show that our approach is fast in terms of training time and tagging speed. Furthermore, our approach obtains very competitive accuracy in comparison to state-of-the-art POS and morphological taggers.
Ripple Down Rules for Question Answering
Nov 04, 2015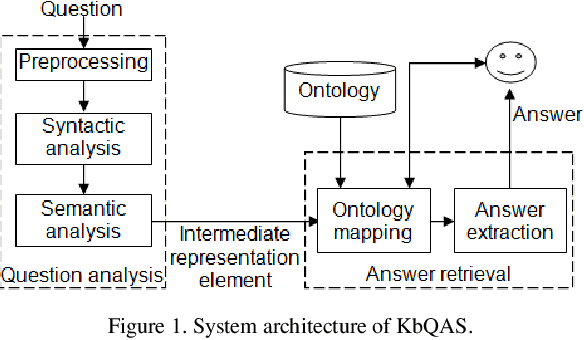

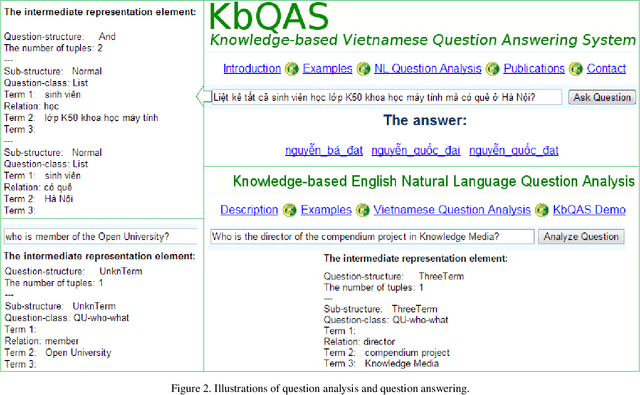
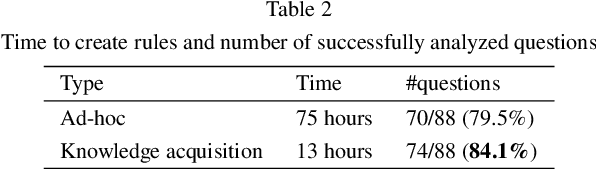
Recent years have witnessed a new trend of building ontology-based question answering systems. These systems use semantic web information to produce more precise answers to users' queries. However, these systems are mostly designed for English. In this paper, we introduce an ontology-based question answering system named KbQAS which, to the best of our knowledge, is the first one made for Vietnamese. KbQAS employs our question analysis approach that systematically constructs a knowledge base of grammar rules to convert each input question into an intermediate representation element. KbQAS then takes the intermediate representation element with respect to a target ontology and applies concept-matching techniques to return an answer. On a wide range of Vietnamese questions, experimental results show that the performance of KbQAS is promising with accuracies of 84.1% and 82.4% for analyzing input questions and retrieving output answers, respectively. Furthermore, our question analysis approach can easily be applied to new domains and new languages, thus saving time and human effort.