 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Constraint-Enforcing Reward for Adversarial Attacks on Text Classifiers
May 20, 2024Text classifiers are vulnerable to adversarial examples -- correctly-classified examples that are deliberately transformed to be misclassified while satisfying acceptability constraints. The conventional approach to finding adversarial examples is to define and solve a combinatorial optimisation problem over a space of allowable transformations. While effective, this approach is slow and limited by the choice of transformations. An alternate approach is to directly generate adversarial examples by fine-tuning a pre-trained language model, as is commonly done for other text-to-text tasks. This approach promises to be much quicker and more expressive, but is relatively unexplored. For this reason, in this work we train an encoder-decoder paraphrase model to generate a diverse range of adversarial examples. For training, we adopt a reinforcement learning algorithm and propose a constraint-enforcing reward that promotes the generation of valid adversarial examples. Experimental results over two text classification datasets show that our model has achieved a higher success rate than the original paraphrase model, and overall has proved more effective than other competitive attacks. Finally, we show how key design choices impact the generated examples and discuss the strengths and weaknesses of the proposed approach.
SumTra: A Differentiable Pipeline for Few-Shot Cross-Lingual Summarization
Mar 20, 2024



Cross-lingual summarization (XLS) generates summaries in a language different from that of the input documents (e.g., English to Spanish), allowing speakers of the target language to gain a concise view of their content. In the present day, the predominant approach to this task is to take a performing, pretrained multilingual language model (LM) and fine-tune it for XLS on the language pairs of interest. However, the scarcity of fine-tuning samples makes this approach challenging in some cases. For this reason, in this paper we propose revisiting the summarize-and-translate pipeline, where the summarization and translation tasks are performed in a sequence. This approach allows reusing the many, publicly-available resources for monolingual summarization and translation, obtaining a very competitive zero-shot performance. In addition, the proposed pipeline is completely differentiable end-to-end, allowing it to take advantage of few-shot fine-tuning, where available. Experiments over two contemporary and widely adopted XLS datasets (CrossSum and WikiLingua) have shown the remarkable zero-shot performance of the proposed approach, and also its strong few-shot performance compared to an equivalent multilingual LM baseline, that the proposed approach has been able to outperform in many languages with only 10% of the fine-tuning samples.
A Generative Adversarial Attack for Multilingual Text Classifiers
Jan 16, 2024Current adversarial attack algorithms, where an adversary changes a text to fool a victim model, have been repeatedly shown to be effective against text classifiers. These attacks, however, generally assume that the victim model is monolingual and cannot be used to target multilingual victim models, a significant limitation given the increased use of these models. For this reason, in this work we propose an approach to fine-tune a multilingual paraphrase model with an adversarial objective so that it becomes able to generate effective adversarial examples against multilingual classifiers. The training objective incorporates a set of pre-trained models to ensure text quality and language consistency of the generated text. In addition, all the models are suitably connected to the generator by vocabulary-mapping matrices, allowing for full end-to-end differentiability of the overall training pipeline. The experimental validation over two multilingual datasets and five languages has shown the effectiveness of the proposed approach compared to existing baselines, particularly in terms of query efficiency. We also provide a detailed analysis of the generated attacks and discuss limitations and opportunities for future research.
T3L: Translate-and-Test Transfer Learning for Cross-Lingual Text Classification
Jun 08, 2023Cross-lingual text classification leverages text classifiers trained in a high-resource language to perform text classification in other languages with no or minimal fine-tuning (zero/few-shots cross-lingual transfer). Nowadays, cross-lingual text classifiers are typically built on large-scale, multilingual language models (LMs) pretrained on a variety of languages of interest. However, the performance of these models vary significantly across languages and classification tasks, suggesting that the superposition of the language modelling and classification tasks is not always effective. For this reason, in this paper we propose revisiting the classic "translate-and-test" pipeline to neatly separate the translation and classification stages. The proposed approach couples 1) a neural machine translator translating from the targeted language to a high-resource language, with 2) a text classifier trained in the high-resource language, but the neural machine translator generates "soft" translations to permit end-to-end backpropagation during fine-tuning of the pipeline. Extensive experiments have been carried out over three cross-lingual text classification datasets (XNLI, MLDoc and MultiEURLEX), with the results showing that the proposed approach has significantly improved performance over a competitive baseline.
A Multi-Document Coverage Reward for RELAXed Multi-Document Summarization
Mar 06, 2022
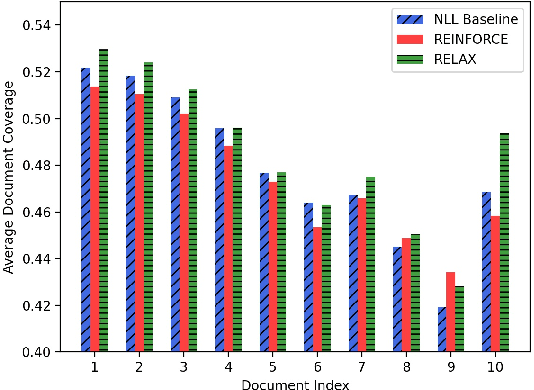


Multi-document summarization (MDS) has made significant progress in recent years, in part facilitated by the availability of new, dedicated datasets and capacious language models. However, a standing limitation of these models is that they are trained against limited references and with plain maximum-likelihood objectives. As for many other generative tasks, reinforcement learning (RL) offers the potential to improve the training of MDS models; yet, it requires a carefully-designed reward that can ensure appropriate leverage of both the reference summaries and the input documents. For this reason, in this paper we propose fine-tuning an MDS baseline with a reward that balances a reference-based metric such as ROUGE with coverage of the input documents. To implement the approach, we utilize RELAX (Grathwohl et al., 2018), a contemporary gradient estimator which is both low-variance and unbiased, and we fine-tune the baseline in a few-shot style for both stability and computational efficiency. Experimental results over the Multi-News and WCEP MDS datasets show significant improvements of up to +0.95 pp average ROUGE score and +3.17 pp METEOR score over the baseline, and competitive results with the literature. In addition, they show that the coverage of the input documents is increased, and evenly across all documents.
RewardsOfSum: Exploring Reinforcement Learning Rewards for Summarisation
Jun 08, 2021
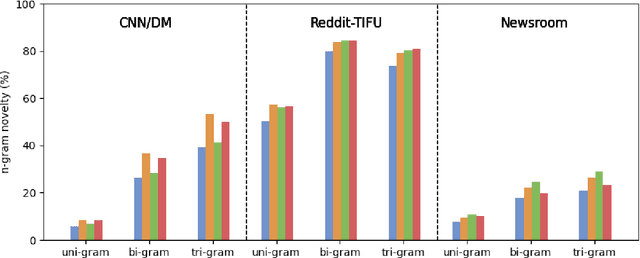
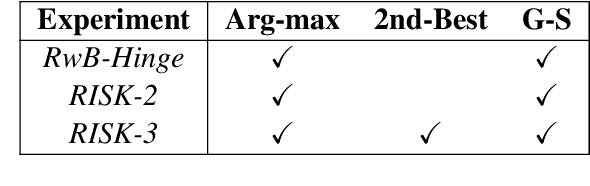
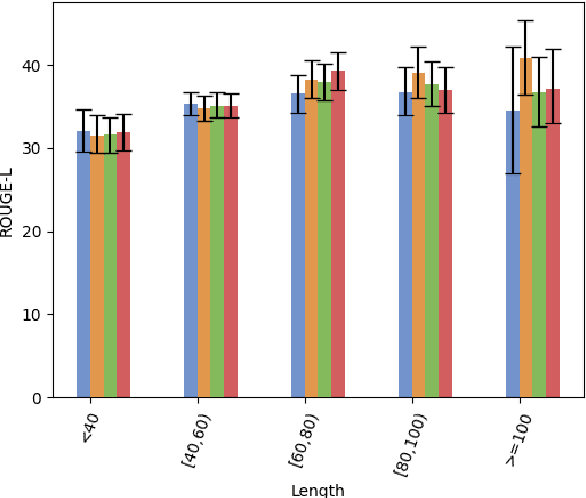
To date, most abstractive summarisation models have relied on variants of the negative log-likelihood (NLL) as their training objective. In some cases, reinforcement learning has been added to train the models with an objective that is closer to their evaluation measures (e.g. ROUGE). However, the reward function to be used within the reinforcement learning approach can play a key role for performance and is still partially unexplored. For this reason, in this paper, we propose two reward functions for the task of abstractive summarisation: the first function, referred to as RwB-Hinge, dynamically selects the samples for the gradient update. The second function, nicknamed RISK, leverages a small pool of strong candidates to inform the reward. In the experiments, we probe the proposed approach by fine-tuning an NLL pre trained model over nine summarisation datasets of diverse size and nature. The experimental results show a consistent improvement over the negative log-likelihood baselines.
BERTTune: Fine-Tuning Neural Machine Translation with BERTScore
Jun 04, 2021
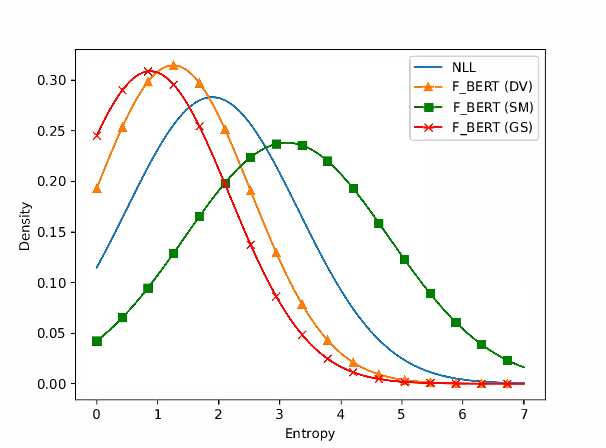


Neural machine translation models are often biased toward the limited translation references seen during training. To amend this form of overfitting, in this paper we propose fine-tuning the models with a novel training objective based on the recently-proposed BERTScore evaluation metric. BERTScore is a scoring function based on contextual embeddings that overcomes the typical limitations of n-gram-based metrics (e.g. synonyms, paraphrases), allowing translations that are different from the references, yet close in the contextual embedding space, to be treated as substantially correct. To be able to use BERTScore as a training objective, we propose three approaches for generating soft predictions, allowing the network to remain completely differentiable end-to-end. Experiments carried out over four, diverse language pairs have achieved improvements of up to 0.58 pp (3.28%) in BLEU score and up to 0.76 pp (0.98%) in BERTScore (F_BERT) when fine-tuning a strong baseline.
Leveraging Discourse Rewards for Document-Level Neural Machine Translation
Oct 19, 2020


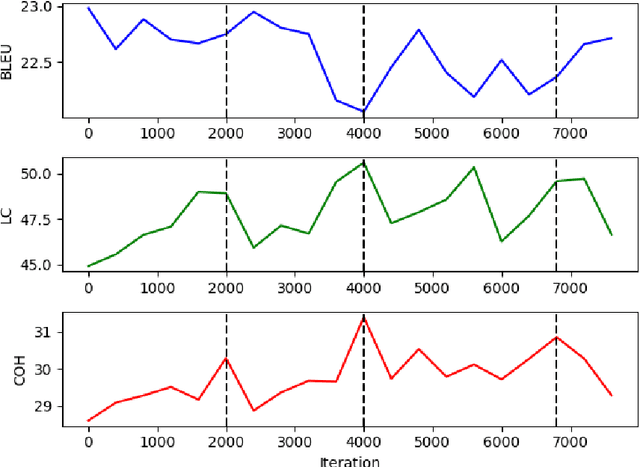
Document-level machine translation focuses on the translation of entire documents from a source to a target language. It is widely regarded as a challenging task since the translation of the individual sentences in the document needs to retain aspects of the discourse at document level. However, document-level translation models are usually not trained to explicitly ensure discourse quality. Therefore, in this paper we propose a training approach that explicitly optimizes two established discourse metrics, lexical cohesion (LC) and coherence (COH), by using a reinforcement learning objective. Experiments over four different language pairs and three translation domains have shown that our training approach has been able to achieve more cohesive and coherent document translations than other competitive approaches, yet without compromising the faithfulness to the reference translation. In the case of the Zh-En language pair, our method has achieved an improvement of 2.46 percentage points (pp) in LC and 1.17 pp in COH over the runner-up, while at the same time improving 0.63 pp in BLEU score and 0.47 pp in F_BERT.
Learning Neural Textual Representations for Citation Recommendation
Jul 08, 2020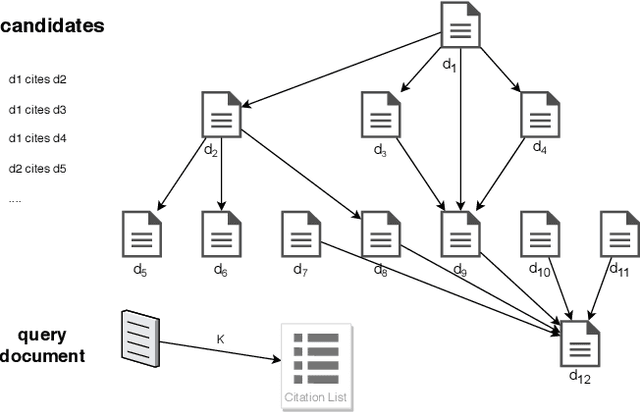
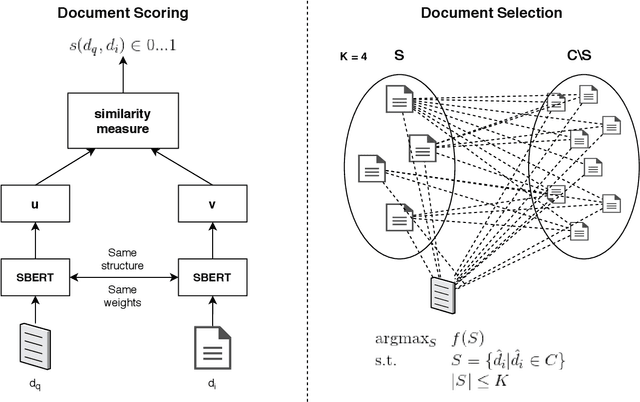
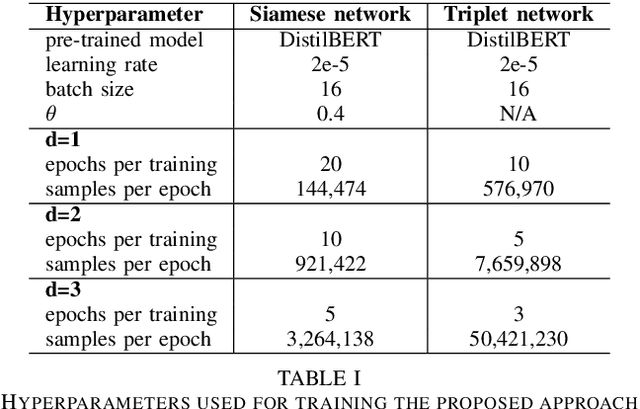
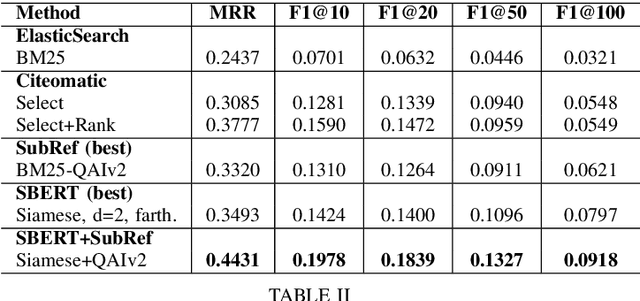
With the rapid growth of the scientific literature, manually selecting appropriate citations for a paper is becoming increasingly challenging and time-consuming. While several approaches for automated citation recommendation have been proposed in the recent years, effective document representations for citation recommendation are still elusive to a large extent. For this reason, in this paper we propose a novel approach to citation recommendation which leverages a deep sequential representation of the documents (Sentence-BERT) cascaded with Siamese and triplet networks in a submodular scoring function. To the best of our knowledge, this is the first approach to combine deep representations and submodular selection for a task of citation recommendation. Experiments have been carried out using a popular benchmark dataset - the ACL Anthology Network corpus - and evaluated against baselines and a state-of-the-art approach using metrics such as the MRR and F1-at-k score. The results show that the proposed approach has been able to outperform all the compared approaches in every measured metric.
Regressing Word and Sentence Embeddings for Regularization of Neural Machine Translation
Sep 30, 2019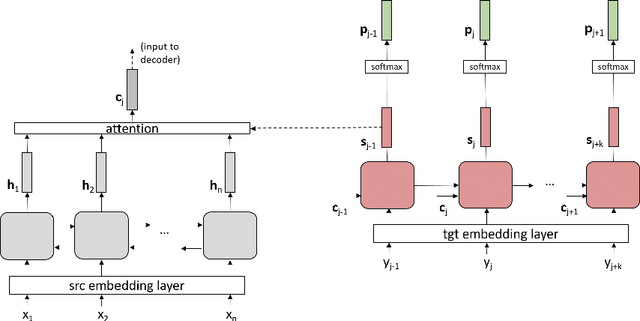
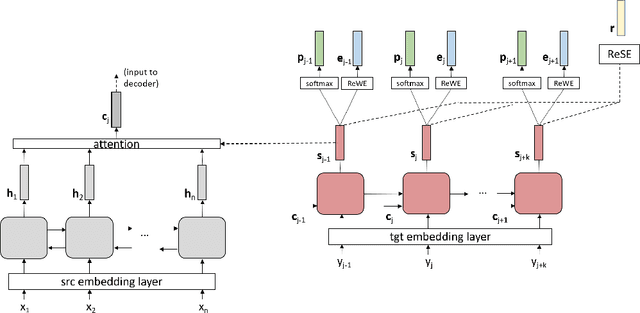
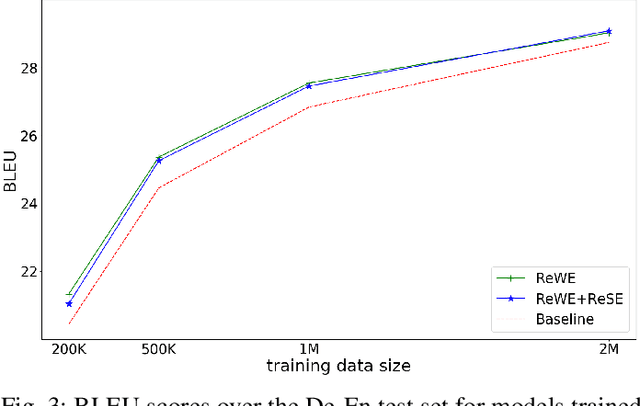
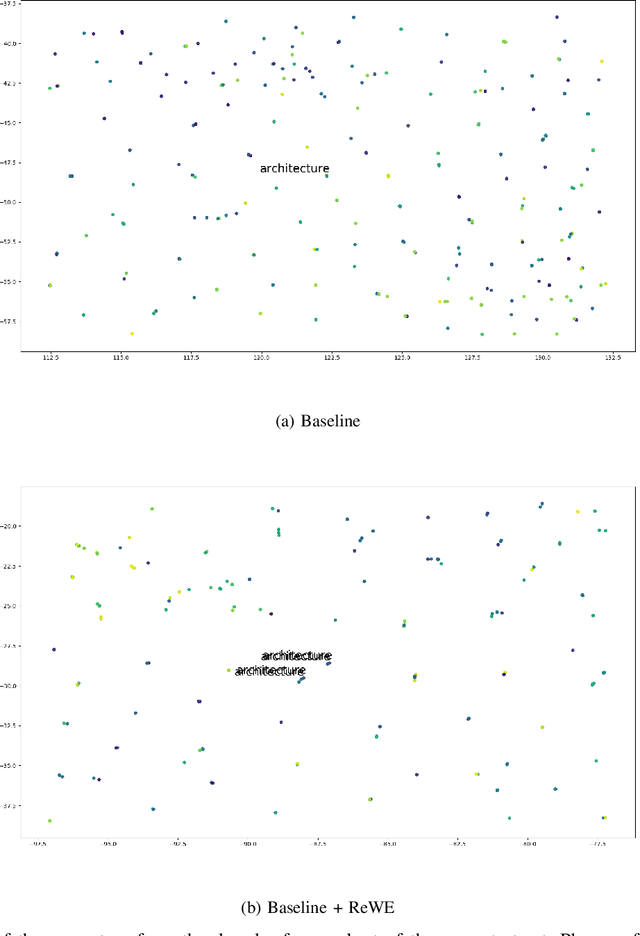
In recent years, neural machine translation (NMT) has become the dominant approach in automated translation. However, like many other deep learning approaches, NMT suffers from overfitting when the amount of training data is limited. This is a serious issue for low-resource language pairs and many specialized translation domains that are inherently limited in the amount of available supervised data. For this reason, in this paper we propose regressing word (ReWE) and sentence (ReSE) embeddings at training time as a way to regularize NMT models and improve their generalization. During training, our models are trained to jointly predict categorical (words in the vocabulary) and continuous (word and sentence embeddings) outputs. An extensive set of experiments over four language pairs of variable training set size has showed that ReWE and ReSE can outperform strong state-of-the-art baseline models, with an improvement that is larger for smaller training sets (e.g., up to +5:15 BLEU points in Basque-English translation). Visualizations of the decoder's output space show that the proposed regularizers improve the clustering of unique words, facilitating correct predictions. In a final experiment on unsupervised NMT, we show that ReWE and ReSE are also able to improve the quality of machine translation when no parallel data are available.