 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTO: a Differentiable Training Objective for Effective Counterfactual Story Rewriting
May 24, 2026Counterfactual story rewriting is a natural language processing task that requires updating an existing story to reflect a chosen alternative event, yet preserving all the unaffected storyline elements and overall coherence. While large language models have recently made remarkable progress on this task, it still remains challenging since the required modifications are typically very small in size and highly localized. As a consequence, models trained in a conventional manner with the maximum-likelihood training objective tend to overlook these nuances. At the same time, more sophisticated training approaches based on reinforcement learning are notoriously slow and difficult to set up. For these reasons, our paper proposes a novel, differentiable training objective (DTO) that directly optimizes for the requisite counterfactual improvements. In our approach, a transformer model is fine-tuned via end-to-end backpropagation against a fully differentiable loss function that jointly rewards (i) fidelity to the reference rewrite and (ii) semantic consistency with the source narrative. The empirical evaluation on the TimeTravel and ART datasets shows that the proposed DTO approach has been able to surpass a maximum-likelihood baseline and a preference-based approach, and perform competitively against two contemporary large language models in all evaluation metrics. These findings substantiate the effectiveness of task-specific differentiable objectives for nuanced, controlled text-generation tasks.
Pref-CTRL: Preference Driven LLM Alignment using Representation Editing
Apr 26, 2026Test-time alignment methods offer a promising alternative to fine-tuning by steering the outputs of large language models (LLMs) at inference time with lightweight interventions on their internal representations. Recently, a prominent and effective approach, RE-Control (Kong et al., 2024), has proposed leveraging an external value function trained over the LLM's hidden states to guide generation via gradient-based editing. While effective, this method overlooks a key characteristic of alignment tasks, i.e. that they are typically formulated as learning from human preferences between candidate responses. To address this, in this paper we propose a novel preference-based training framework, Pref-CTRL, that uses a multi-objective value function to better reflect the structure of preference data. Our approach has outperformed RE-Control on two benchmark datasets and showed greater generalization on out-of-domain datasets. Our source code is available at https://github.com/UTS-nlPUG/pref-ctrl.
ViMedCSS: A Vietnamese Medical Code-Switching Speech Dataset & Benchmark
Feb 13, 2026Code-switching (CS), which is when Vietnamese speech uses English words like drug names or procedures, is a common phenomenon in Vietnamese medical communication. This creates challenges for Automatic Speech Recognition (ASR) systems, especially in low-resource languages like Vietnamese. Current most ASR systems struggle to recognize correctly English medical terms within Vietnamese sentences, and no benchmark addresses this challenge. In this paper, we construct a 34-hour \textbf{Vi}etnamese \textbf{Med}ical \textbf{C}ode-\textbf{S}witching \textbf{S}peech dataset (ViMedCSS) containing 16,576 utterances. Each utterance includes at least one English medical term drawn from a curated bilingual lexicon covering five medical topics. Using this dataset, we evaluate several state-of-the-art ASR models and examine different specific fine-tuning strategies for improving medical term recognition to investigate the best approach to solve in the dataset. Experimental results show that Vietnamese-optimized models perform better on general segments, while multilingual pretraining helps capture English insertions. The combination of both approaches yields the best balance between overall and code-switched accuracy. This work provides the first benchmark for Vietnamese medical code-switching and offers insights into effective domain adaptation for low-resource, multilingual ASR systems.
Multilingual LLM Prompting Strategies for Medical English-Vietnamese Machine Translation
Sep 19, 2025Medical English-Vietnamese machine translation (En-Vi MT) is essential for healthcare access and communication in Vietnam, yet Vietnamese remains a low-resource and under-studied language. We systematically evaluate prompting strategies for six multilingual LLMs (0.5B-9B parameters) on the MedEV dataset, comparing zero-shot, few-shot, and dictionary-augmented prompting with Meddict, an English-Vietnamese medical lexicon. Results show that model scale is the primary driver of performance: larger LLMs achieve strong zero-shot results, while few-shot prompting yields only marginal improvements. In contrast, terminology-aware cues and embedding-based example retrieval consistently improve domain-specific translation. These findings underscore both the promise and the current limitations of multilingual LLMs for medical En-Vi MT.
A Constraint-Enforcing Reward for Adversarial Attacks on Text Classifiers
May 20, 2024Text classifiers are vulnerable to adversarial examples -- correctly-classified examples that are deliberately transformed to be misclassified while satisfying acceptability constraints. The conventional approach to finding adversarial examples is to define and solve a combinatorial optimisation problem over a space of allowable transformations. While effective, this approach is slow and limited by the choice of transformations. An alternate approach is to directly generate adversarial examples by fine-tuning a pre-trained language model, as is commonly done for other text-to-text tasks. This approach promises to be much quicker and more expressive, but is relatively unexplored. For this reason, in this work we train an encoder-decoder paraphrase model to generate a diverse range of adversarial examples. For training, we adopt a reinforcement learning algorithm and propose a constraint-enforcing reward that promotes the generation of valid adversarial examples. Experimental results over two text classification datasets show that our model has achieved a higher success rate than the original paraphrase model, and overall has proved more effective than other competitive attacks. Finally, we show how key design choices impact the generated examples and discuss the strengths and weaknesses of the proposed approach.
Improving Vietnamese-English Medical Machine Translation
Mar 28, 2024
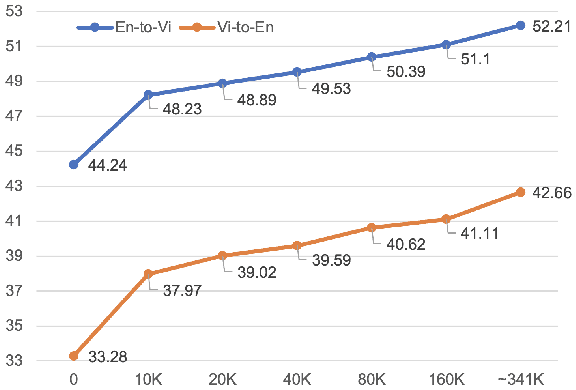


Machine translation for Vietnamese-English in the medical domain is still an under-explored research area. In this paper, we introduce MedEV -- a high-quality Vietnamese-English parallel dataset constructed specifically for the medical domain, comprising approximately 360K sentence pairs. We conduct extensive experiments comparing Google Translate, ChatGPT (gpt-3.5-turbo), state-of-the-art Vietnamese-English neural machine translation models and pre-trained bilingual/multilingual sequence-to-sequence models on our new MedEV dataset. Experimental results show that the best performance is achieved by fine-tuning "vinai-translate" for each translation direction. We publicly release our dataset to promote further research.
SumTra: A Differentiable Pipeline for Few-Shot Cross-Lingual Summarization
Mar 20, 2024



Cross-lingual summarization (XLS) generates summaries in a language different from that of the input documents (e.g., English to Spanish), allowing speakers of the target language to gain a concise view of their content. In the present day, the predominant approach to this task is to take a performing, pretrained multilingual language model (LM) and fine-tune it for XLS on the language pairs of interest. However, the scarcity of fine-tuning samples makes this approach challenging in some cases. For this reason, in this paper we propose revisiting the summarize-and-translate pipeline, where the summarization and translation tasks are performed in a sequence. This approach allows reusing the many, publicly-available resources for monolingual summarization and translation, obtaining a very competitive zero-shot performance. In addition, the proposed pipeline is completely differentiable end-to-end, allowing it to take advantage of few-shot fine-tuning, where available. Experiments over two contemporary and widely adopted XLS datasets (CrossSum and WikiLingua) have shown the remarkable zero-shot performance of the proposed approach, and also its strong few-shot performance compared to an equivalent multilingual LM baseline, that the proposed approach has been able to outperform in many languages with only 10% of the fine-tuning samples.
A Generative Adversarial Attack for Multilingual Text Classifiers
Jan 16, 2024Current adversarial attack algorithms, where an adversary changes a text to fool a victim model, have been repeatedly shown to be effective against text classifiers. These attacks, however, generally assume that the victim model is monolingual and cannot be used to target multilingual victim models, a significant limitation given the increased use of these models. For this reason, in this work we propose an approach to fine-tune a multilingual paraphrase model with an adversarial objective so that it becomes able to generate effective adversarial examples against multilingual classifiers. The training objective incorporates a set of pre-trained models to ensure text quality and language consistency of the generated text. In addition, all the models are suitably connected to the generator by vocabulary-mapping matrices, allowing for full end-to-end differentiability of the overall training pipeline. The experimental validation over two multilingual datasets and five languages has shown the effectiveness of the proposed approach compared to existing baselines, particularly in terms of query efficiency. We also provide a detailed analysis of the generated attacks and discuss limitations and opportunities for future research.
T3L: Translate-and-Test Transfer Learning for Cross-Lingual Text Classification
Jun 08, 2023Cross-lingual text classification leverages text classifiers trained in a high-resource language to perform text classification in other languages with no or minimal fine-tuning (zero/few-shots cross-lingual transfer). Nowadays, cross-lingual text classifiers are typically built on large-scale, multilingual language models (LMs) pretrained on a variety of languages of interest. However, the performance of these models vary significantly across languages and classification tasks, suggesting that the superposition of the language modelling and classification tasks is not always effective. For this reason, in this paper we propose revisiting the classic "translate-and-test" pipeline to neatly separate the translation and classification stages. The proposed approach couples 1) a neural machine translator translating from the targeted language to a high-resource language, with 2) a text classifier trained in the high-resource language, but the neural machine translator generates "soft" translations to permit end-to-end backpropagation during fine-tuning of the pipeline. Extensive experiments have been carried out over three cross-lingual text classification datasets (XNLI, MLDoc and MultiEURLEX), with the results showing that the proposed approach has significantly improved performance over a competitive baseline.
Traffic incident duration prediction via a deep learning framework for text description encoding
Sep 19, 2022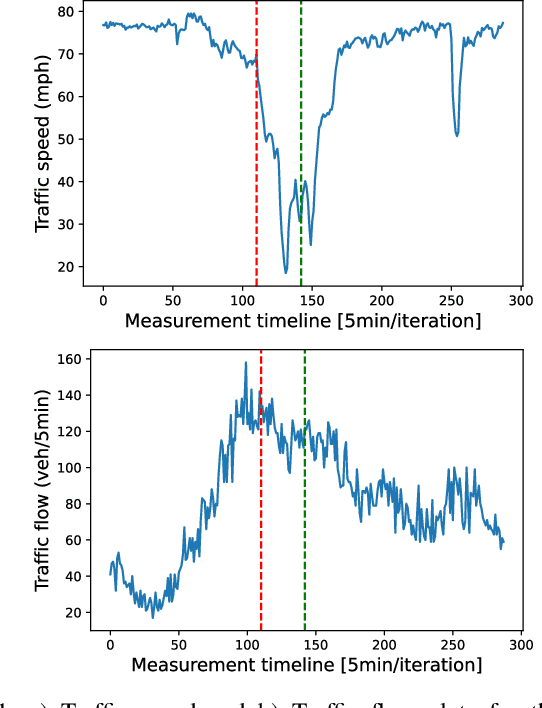
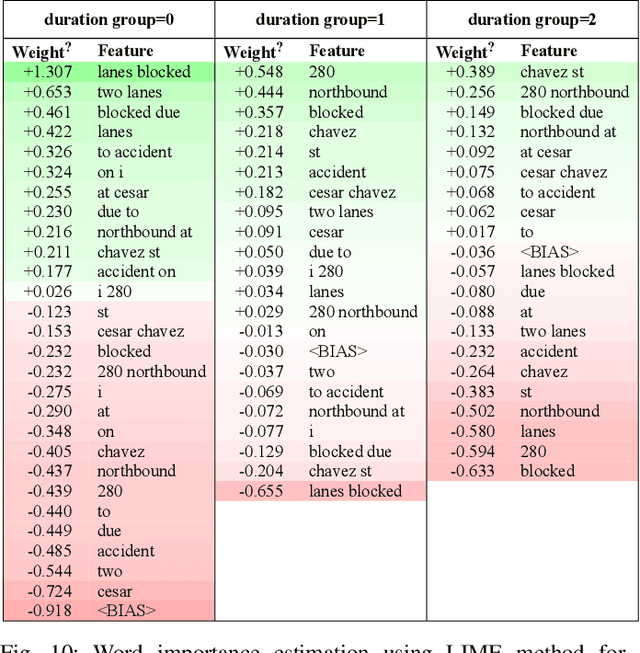
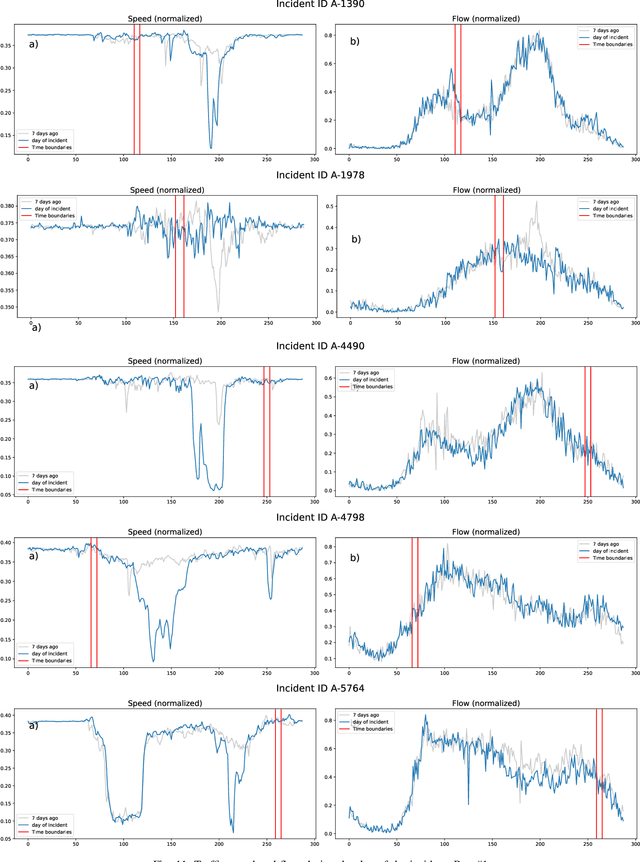
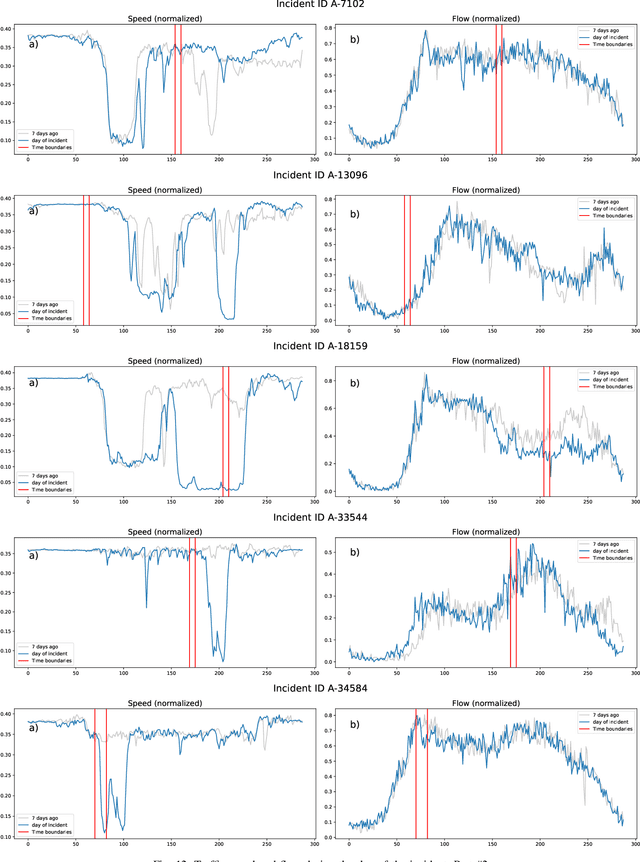
Predicting the traffic incident duration is a hard problem to solve due to the stochastic nature of incident occurrence in space and time, a lack of information at the beginning of a reported traffic disruption, and lack of advanced methods in transport engineering to derive insights from past accidents. This paper proposes a new fusion framework for predicting the incident duration from limited information by using an integration of machine learning with traffic flow/speed and incident description as features, encoded via several Deep Learning methods (ANN autoencoder and character-level LSTM-ANN sentiment classifier). The paper constructs a cross-disciplinary modelling approach in transport and data science. The approach improves the incident duration prediction accuracy over the top-performing ML models applied to baseline incident reports. Results show that our proposed method can improve the accuracy by $60\%$ when compared to standard linear or support vector regression models, and a further $7\%$ improvement with respect to the hybrid deep learning auto-encoded GBDT model which seems to outperform all other models. The application area is the city of San Francisco, rich in both traffic incident logs (Countrywide Traffic Accident Data set) and past historical traffic congestion information (5-minute precision measurements from Caltrans Performance Measurement System).