 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiDA: Phonetically-Informed Data Augmentation for Robust Vietnamese Speech Translation
Jun 11, 2026Cascaded speech translation (ST) systems suffer from error propagation when Automatic Speech Recognition (ASR) outputs incorrect transcripts. We present the first systematic categorization of ASR errors for Vietnamese ST, classifying substitution errors by phonetic cause and quantifying their impact on downstream Neural Machine Translation (NMT) performance using Linear Mixed-Effects Modelling. We confirm that most ASR substitution errors arise from phonetic confusions rather than random noise, and that these phonetic errors significantly degrade ST quality. Motivated by this finding, we propose Phonetically-Informed Data Augmentation (PiDA), which generates ASR-like corruptions by substituting words with phonetically similar alternatives using phonetic word embeddings. Fine-tuning on a PiDA-augmented version of FLEURS Vietnamese-English improves translation of erroneous ASR outputs (up to +2.04 BLEU over standard fine-tuning) while also slightly improving clean-text performance.
Contrastive Training with LLM-generated Near-Misses for Robust Code-Switching Speech Recognition
Jun 05, 2026Code-switching (CS), the alternation between multiple languages within a single utterance, remains challenging for Automatic Speech Recognition (ASR). To address this issue, we propose a Point-of-Interest (POI)-aware contrastive training framework that improves recognition at CS-critical regions. We first identify CS spans by adopting POI detection method from literature, then construct acoustically plausible near-miss hypotheses by perturbing POIs in ASR N-best outputs and expanding candidates with a large language model. Hard but plausible negatives are retained through filtering with acoustic, phonemic, and textual constraints. Finally, we fine-tune Whisper-small with LoRA using a POI-weighted cross-entropy anchor objective together with a multi-negative contrastive ranking loss. Experiments on CS-FLEURS (cmn-eng) and ViMedCSS (vie-eng) show consistent reductions of over 2% in both general and CS-aware error rates compared to standard LoRA fine-tuning.
ViMedCSS: A Vietnamese Medical Code-Switching Speech Dataset & Benchmark
Feb 13, 2026Code-switching (CS), which is when Vietnamese speech uses English words like drug names or procedures, is a common phenomenon in Vietnamese medical communication. This creates challenges for Automatic Speech Recognition (ASR) systems, especially in low-resource languages like Vietnamese. Current most ASR systems struggle to recognize correctly English medical terms within Vietnamese sentences, and no benchmark addresses this challenge. In this paper, we construct a 34-hour \textbf{Vi}etnamese \textbf{Med}ical \textbf{C}ode-\textbf{S}witching \textbf{S}peech dataset (ViMedCSS) containing 16,576 utterances. Each utterance includes at least one English medical term drawn from a curated bilingual lexicon covering five medical topics. Using this dataset, we evaluate several state-of-the-art ASR models and examine different specific fine-tuning strategies for improving medical term recognition to investigate the best approach to solve in the dataset. Experimental results show that Vietnamese-optimized models perform better on general segments, while multilingual pretraining helps capture English insertions. The combination of both approaches yields the best balance between overall and code-switched accuracy. This work provides the first benchmark for Vietnamese medical code-switching and offers insights into effective domain adaptation for low-resource, multilingual ASR systems.
Multilingual LLM Prompting Strategies for Medical English-Vietnamese Machine Translation
Sep 19, 2025Medical English-Vietnamese machine translation (En-Vi MT) is essential for healthcare access and communication in Vietnam, yet Vietnamese remains a low-resource and under-studied language. We systematically evaluate prompting strategies for six multilingual LLMs (0.5B-9B parameters) on the MedEV dataset, comparing zero-shot, few-shot, and dictionary-augmented prompting with Meddict, an English-Vietnamese medical lexicon. Results show that model scale is the primary driver of performance: larger LLMs achieve strong zero-shot results, while few-shot prompting yields only marginal improvements. In contrast, terminology-aware cues and embedding-based example retrieval consistently improve domain-specific translation. These findings underscore both the promise and the current limitations of multilingual LLMs for medical En-Vi MT.
Improving Vietnamese-English Medical Machine Translation
Mar 28, 2024
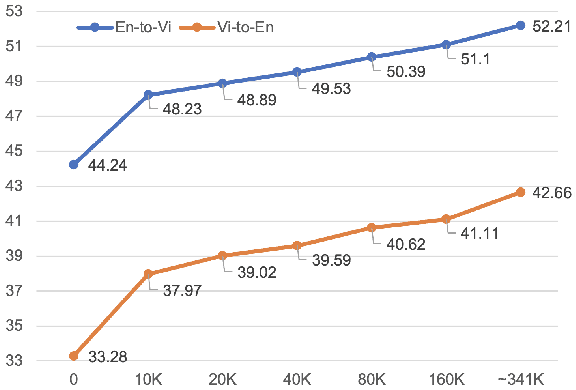


Machine translation for Vietnamese-English in the medical domain is still an under-explored research area. In this paper, we introduce MedEV -- a high-quality Vietnamese-English parallel dataset constructed specifically for the medical domain, comprising approximately 360K sentence pairs. We conduct extensive experiments comparing Google Translate, ChatGPT (gpt-3.5-turbo), state-of-the-art Vietnamese-English neural machine translation models and pre-trained bilingual/multilingual sequence-to-sequence models on our new MedEV dataset. Experimental results show that the best performance is achieved by fine-tuning "vinai-translate" for each translation direction. We publicly release our dataset to promote further research.