 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Discourse Rewards for Document-Level Neural Machine Translation
Oct 19, 2020


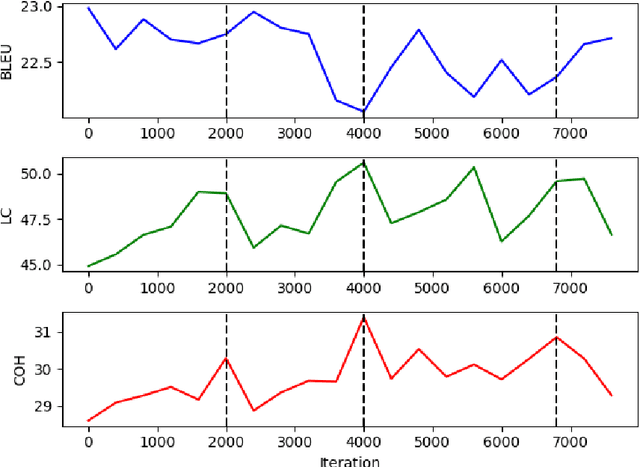
Document-level machine translation focuses on the translation of entire documents from a source to a target language. It is widely regarded as a challenging task since the translation of the individual sentences in the document needs to retain aspects of the discourse at document level. However, document-level translation models are usually not trained to explicitly ensure discourse quality. Therefore, in this paper we propose a training approach that explicitly optimizes two established discourse metrics, lexical cohesion (LC) and coherence (COH), by using a reinforcement learning objective. Experiments over four different language pairs and three translation domains have shown that our training approach has been able to achieve more cohesive and coherent document translations than other competitive approaches, yet without compromising the faithfulness to the reference translation. In the case of the Zh-En language pair, our method has achieved an improvement of 2.46 percentage points (pp) in LC and 1.17 pp in COH over the runner-up, while at the same time improving 0.63 pp in BLEU score and 0.47 pp in F_BERT.
ReWE: Regressing Word Embeddings for Regularization of Neural Machine Translation Systems
Apr 04, 2019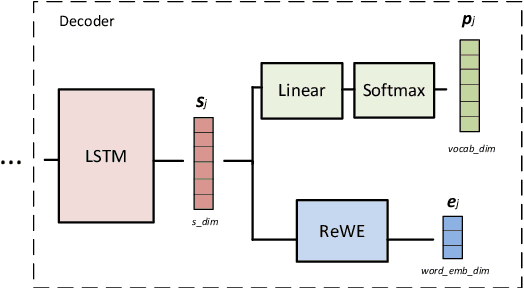
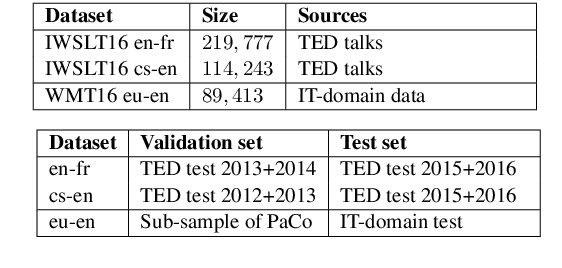
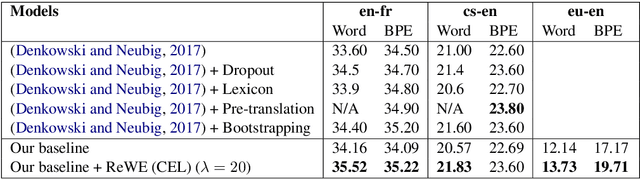
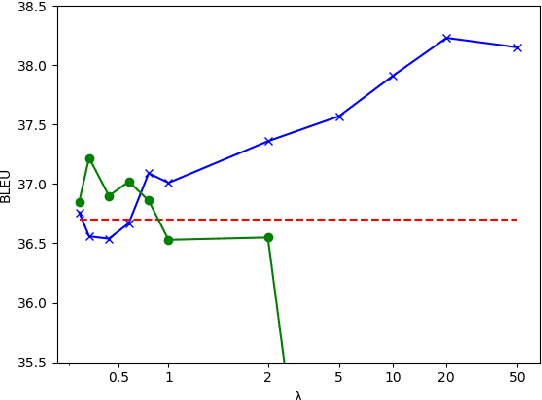
Regularization of neural machine translation is still a significant problem, especially in low-resource settings. To mollify this problem, we propose regressing word embeddings (ReWE) as a new regularization technique in a system that is jointly trained to predict the next word in the translation (categorical value) and its word embedding (continuous value). Such a joint training allows the proposed system to learn the distributional properties represented by the word embeddings, empirically improving the generalization to unseen sentences. Experiments over three translation datasets have showed a consistent improvement over a strong baseline, ranging between 0.91 and 2.54 BLEU points, and also a marked improvement over a state-of-the-art system.