 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegressing Word and Sentence Embeddings for Regularization of Neural Machine Translation
Sep 30, 2019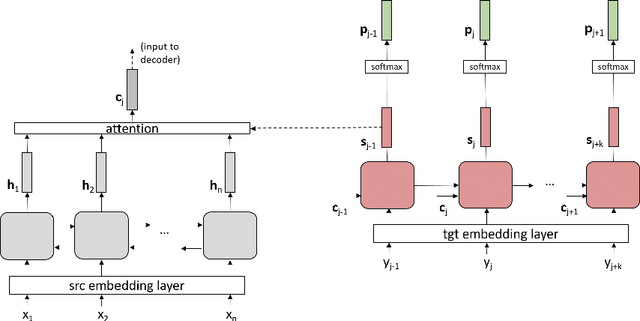
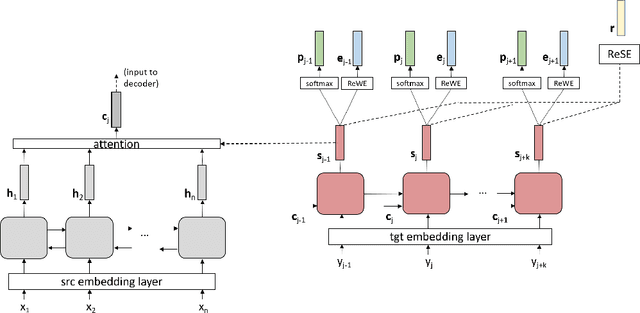
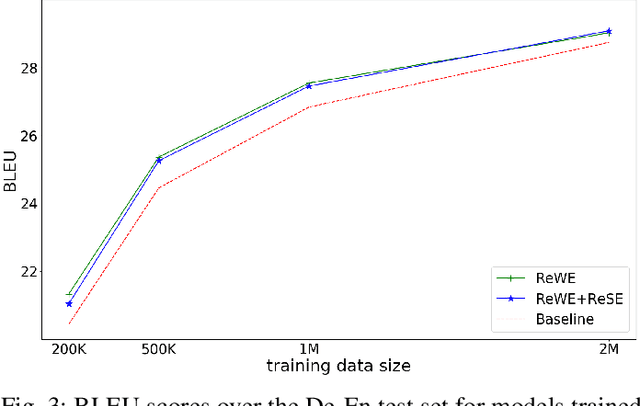
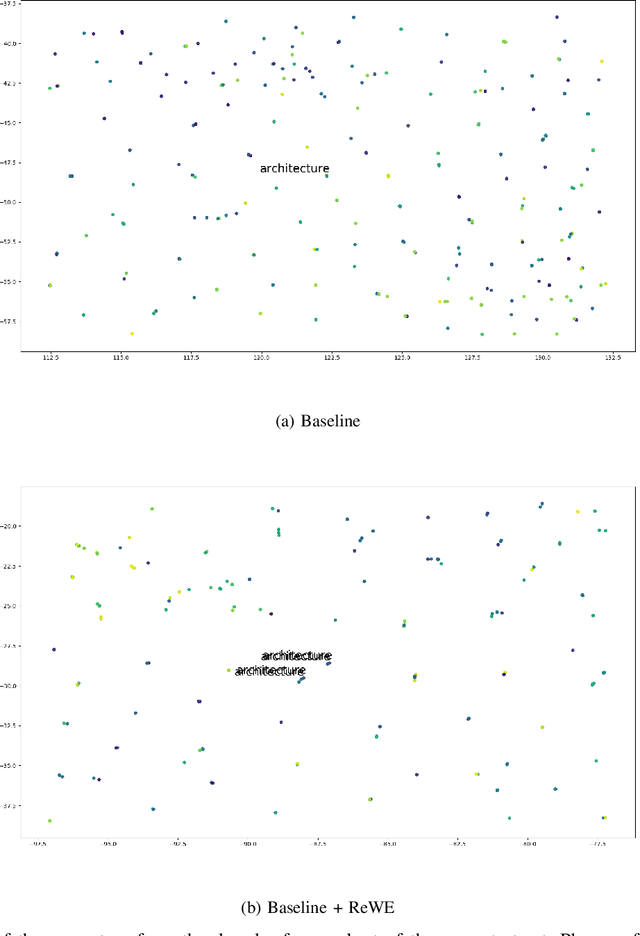
In recent years, neural machine translation (NMT) has become the dominant approach in automated translation. However, like many other deep learning approaches, NMT suffers from overfitting when the amount of training data is limited. This is a serious issue for low-resource language pairs and many specialized translation domains that are inherently limited in the amount of available supervised data. For this reason, in this paper we propose regressing word (ReWE) and sentence (ReSE) embeddings at training time as a way to regularize NMT models and improve their generalization. During training, our models are trained to jointly predict categorical (words in the vocabulary) and continuous (word and sentence embeddings) outputs. An extensive set of experiments over four language pairs of variable training set size has showed that ReWE and ReSE can outperform strong state-of-the-art baseline models, with an improvement that is larger for smaller training sets (e.g., up to +5:15 BLEU points in Basque-English translation). Visualizations of the decoder's output space show that the proposed regularizers improve the clustering of unique words, facilitating correct predictions. In a final experiment on unsupervised NMT, we show that ReWE and ReSE are also able to improve the quality of machine translation when no parallel data are available.
ReWE: Regressing Word Embeddings for Regularization of Neural Machine Translation Systems
Apr 04, 2019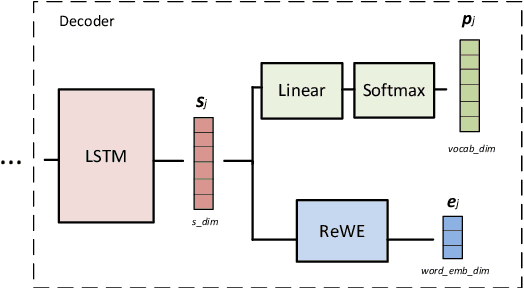
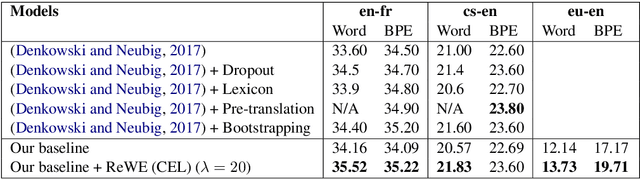
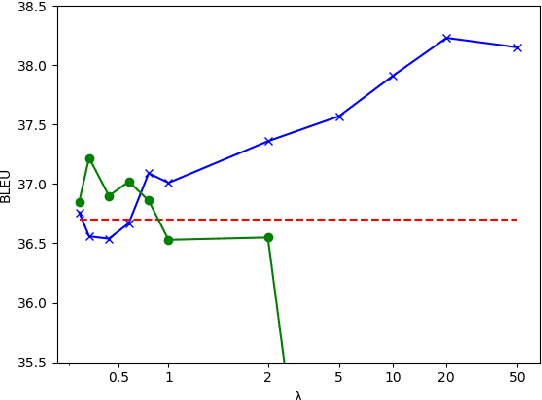
Regularization of neural machine translation is still a significant problem, especially in low-resource settings. To mollify this problem, we propose regressing word embeddings (ReWE) as a new regularization technique in a system that is jointly trained to predict the next word in the translation (categorical value) and its word embedding (continuous value). Such a joint training allows the proposed system to learn the distributional properties represented by the word embeddings, empirically improving the generalization to unseen sentences. Experiments over three translation datasets have showed a consistent improvement over a strong baseline, ranging between 0.91 and 2.54 BLEU points, and also a marked improvement over a state-of-the-art system.
A Shared Attention Mechanism for Interpretation of Neural Automatic Post-Editing Systems
Jul 01, 2018


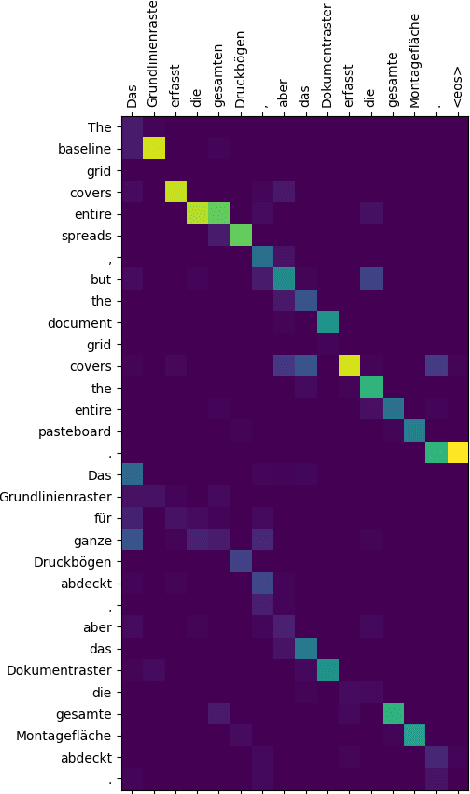
Automatic post-editing (APE) systems aim to correct the systematic errors made by machine translators. In this paper, we propose a neural APE system that encodes the source (src) and machine translated (mt) sentences with two separate encoders, but leverages a shared attention mechanism to better understand how the two inputs contribute to the generation of the post-edited (pe) sentences. Our empirical observations have showed that when the mt is incorrect, the attention shifts weight toward tokens in the src sentence to properly edit the incorrect translation. The model has been trained and evaluated on the official data from the WMT16 and WMT17 APE IT domain English-German shared tasks. Additionally, we have used the extra 500K artificial data provided by the shared task. Our system has been able to reproduce the accuracies of systems trained with the same data, while at the same time providing better interpretability.
Recurrent neural networks with specialized word embeddings for health-domain named-entity recognition
Jun 25, 2018


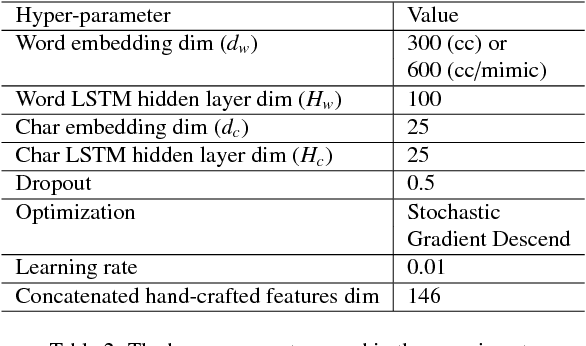
Background. Previous state-of-the-art systems on Drug Name Recognition (DNR) and Clinical Concept Extraction (CCE) have focused on a combination of text "feature engineering" and conventional machine learning algorithms such as conditional random fields and support vector machines. However, developing good features is inherently heavily time-consuming. Conversely, more modern machine learning approaches such as recurrent neural networks (RNNs) have proved capable of automatically learning effective features from either random assignments or automated word "embeddings". Objectives. (i) To create a highly accurate DNR and CCE system that avoids conventional, time-consuming feature engineering. (ii) To create richer, more specialized word embeddings by using health domain datasets such as MIMIC-III. (iii) To evaluate our systems over three contemporary datasets. Methods. Two deep learning methods, namely the Bidirectional LSTM and the Bidirectional LSTM-CRF, are evaluated. A CRF model is set as the baseline to compare the deep learning systems to a traditional machine learning approach. The same features are used for all the models. Results. We have obtained the best results with the Bidirectional LSTM-CRF model, which has outperformed all previously proposed systems. The specialized embeddings have helped to cover unusual words in DDI-DrugBank and DDI-MedLine, but not in the 2010 i2b2/VA IRB Revision dataset. Conclusion. We present a state-of-the-art system for DNR and CCE. Automated word embeddings has allowed us to avoid costly feature engineering and achieve higher accuracy. Nevertheless, the embeddings need to be retrained over datasets that are adequate for the domain, in order to adequately cover the domain-specific vocabulary.
Bidirectional LSTM-CRF for Clinical Concept Extraction
Nov 25, 2016

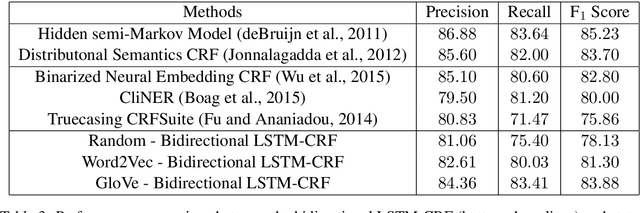
Automated extraction of concepts from patient clinical records is an essential facilitator of clinical research. For this reason, the 2010 i2b2/VA Natural Language Processing Challenges for Clinical Records introduced a concept extraction task aimed at identifying and classifying concepts into predefined categories (i.e., treatments, tests and problems). State-of-the-art concept extraction approaches heavily rely on handcrafted features and domain-specific resources which are hard to collect and define. For this reason, this paper proposes an alternative, streamlined approach: a recurrent neural network (the bidirectional LSTM with CRF decoding) initialized with general-purpose, off-the-shelf word embeddings. The experimental results achieved on the 2010 i2b2/VA reference corpora using the proposed framework outperform all recent methods and ranks closely to the best submission from the original 2010 i2b2/VA challenge.
An Investigation of Recurrent Neural Architectures for Drug Name Recognition
Sep 24, 2016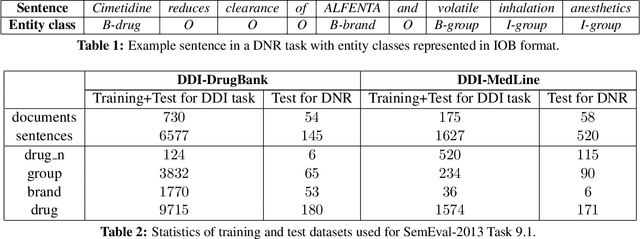
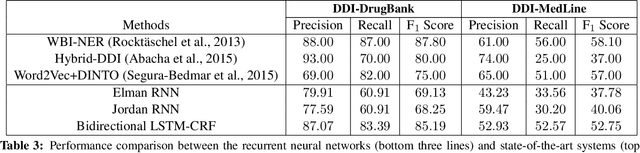
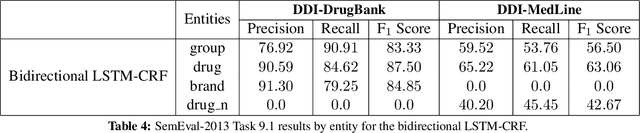
Drug name recognition (DNR) is an essential step in the Pharmacovigilance (PV) pipeline. DNR aims to find drug name mentions in unstructured biomedical texts and classify them into predefined categories. State-of-the-art DNR approaches heavily rely on hand crafted features and domain specific resources which are difficult to collect and tune. For this reason, this paper investigates the effectiveness of contemporary recurrent neural architectures - the Elman and Jordan networks and the bidirectional LSTM with CRF decoding - at performing DNR straight from the text. The experimental results achieved on the authoritative SemEval-2013 Task 9.1 benchmarks show that the bidirectional LSTM-CRF ranks closely to highly-dedicated, hand-crafted systems.