 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Anomaly Detection: A Survey
Jan 23, 2019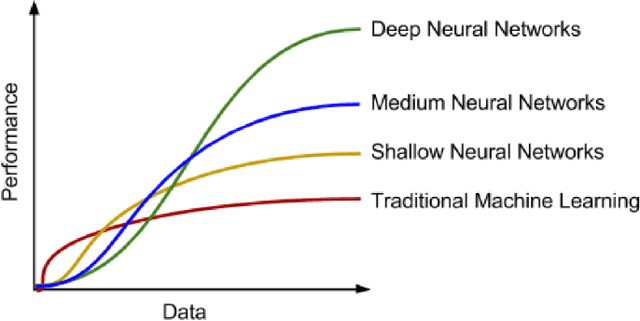
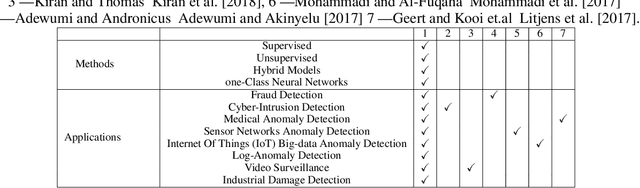
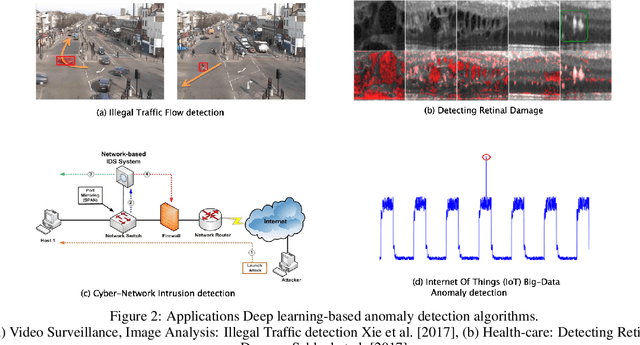
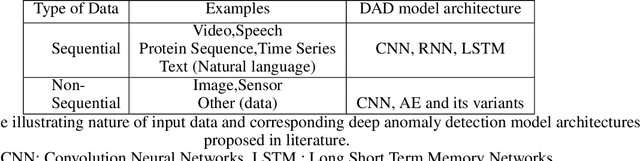
Anomaly detection is an important problem that has been well-studied within diverse research areas and application domains. The aim of this survey is two-fold, firstly we present a structured and comprehensive overview of research methods in deep learning-based anomaly detection. Furthermore, we review the adoption of these methods for anomaly across various application domains and assess their effectiveness. We have grouped state-of-the-art research techniques into different categories based on the underlying assumptions and approach adopted. Within each category we outline the basic anomaly detection technique, along with its variants and present key assumptions, to differentiate between normal and anomalous behavior. For each category, we present we also present the advantages and limitations and discuss the computational complexity of the techniques in real application domains. Finally, we outline open issues in research and challenges faced while adopting these techniques.
Group Anomaly Detection using Deep Generative Models
Apr 13, 2018
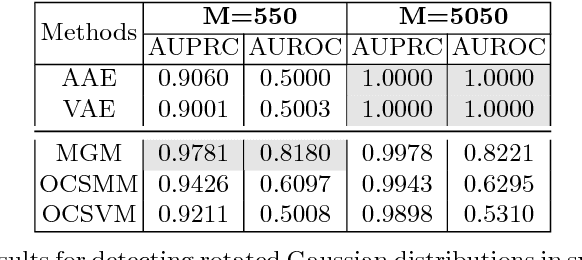

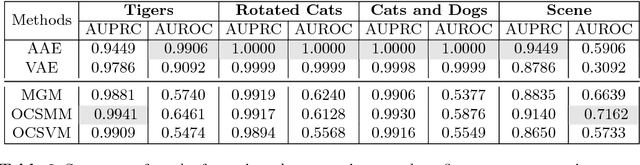
Unlike conventional anomaly detection research that focuses on point anomalies, our goal is to detect anomalous collections of individual data points. In particular, we perform group anomaly detection (GAD) with an emphasis on irregular group distributions (e.g. irregular mixtures of image pixels). GAD is an important task in detecting unusual and anomalous phenomena in real-world applications such as high energy particle physics, social media, and medical imaging. In this paper, we take a generative approach by proposing deep generative models: Adversarial autoencoder (AAE) and variational autoencoder (VAE) for group anomaly detection. Both AAE and VAE detect group anomalies using point-wise input data where group memberships are known a priori. We conduct extensive experiments to evaluate our models on real-world datasets. The empirical results demonstrate that our approach is effective and robust in detecting group anomalies.
Anomaly Detection using One-Class Neural Networks
Feb 18, 2018
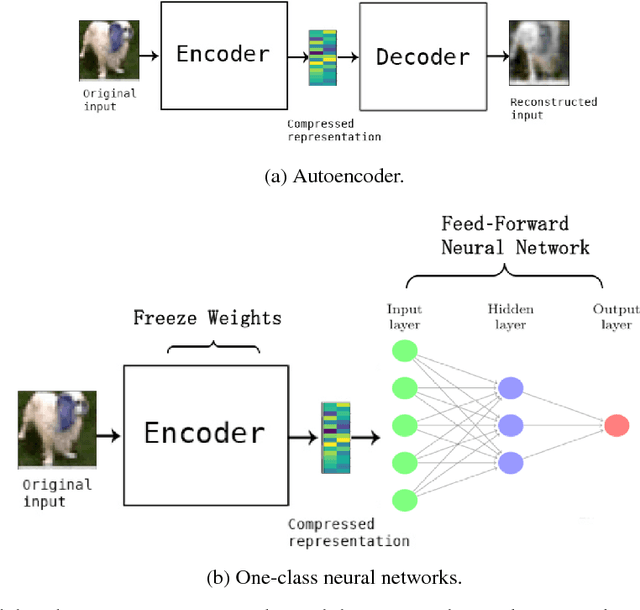
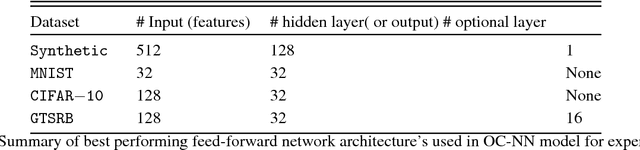
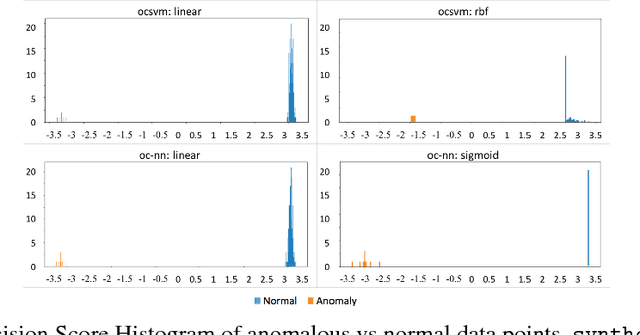
We propose a one-class neural network (OC-NN) model to detect anomalies in complex data sets. OC-NN combines the ability of deep networks to extract progressively rich representation of data with the one-class objective of creating a tight envelope around normal data. The OC-NN approach breaks new ground for the following crucial reason: data representation in the hidden layer is driven by the OC-NN objective and is thus customized for anomaly detection. This is a departure from other approaches which use a hybrid approach of learning deep features using an autoencoder and then feeding the features into a separate anomaly detection method like one-class SVM (OC-SVM). The hybrid OC-SVM approach is suboptimal because it is unable to influence representational learning in the hidden layers. A comprehensive set of experiments demonstrate that on complex data sets (like CIFAR and PFAM), OC-NN significantly outperforms existing state-of-the-art anomaly detection methods.
Robust, Deep and Inductive Anomaly Detection
Jul 30, 2017

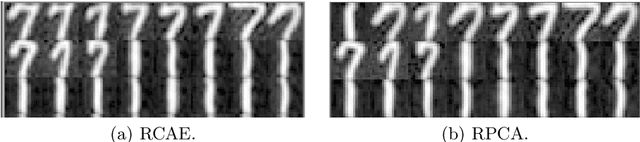
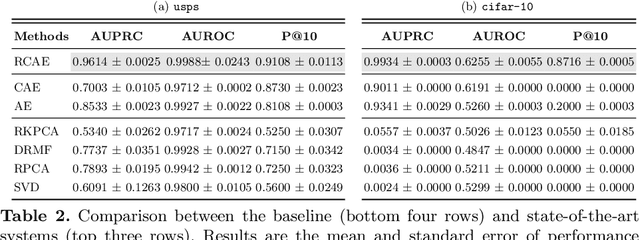
PCA is a classical statistical technique whose simplicity and maturity has seen it find widespread use as an anomaly detection technique. However, it is limited in this regard by being sensitive to gross perturbations of the input, and by seeking a linear subspace that captures normal behaviour. The first issue has been dealt with by robust PCA, a variant of PCA that explicitly allows for some data points to be arbitrarily corrupted, however, this does not resolve the second issue, and indeed introduces the new issue that one can no longer inductively find anomalies on a test set. This paper addresses both issues in a single model, the robust autoencoder. This method learns a nonlinear subspace that captures the majority of data points, while allowing for some data to have arbitrary corruption. The model is simple to train and leverages recent advances in the optimisation of deep neural networks. Experiments on a range of real-world datasets highlight the model's effectiveness.
Bidirectional LSTM-CRF for Clinical Concept Extraction
Nov 25, 2016

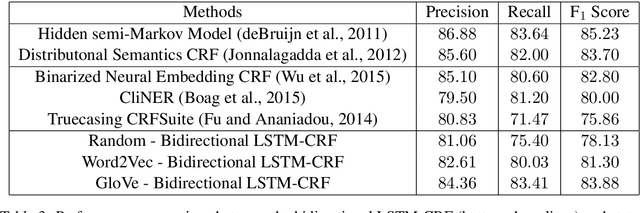
Automated extraction of concepts from patient clinical records is an essential facilitator of clinical research. For this reason, the 2010 i2b2/VA Natural Language Processing Challenges for Clinical Records introduced a concept extraction task aimed at identifying and classifying concepts into predefined categories (i.e., treatments, tests and problems). State-of-the-art concept extraction approaches heavily rely on handcrafted features and domain-specific resources which are hard to collect and define. For this reason, this paper proposes an alternative, streamlined approach: a recurrent neural network (the bidirectional LSTM with CRF decoding) initialized with general-purpose, off-the-shelf word embeddings. The experimental results achieved on the 2010 i2b2/VA reference corpora using the proposed framework outperform all recent methods and ranks closely to the best submission from the original 2010 i2b2/VA challenge.
An Investigation of Recurrent Neural Architectures for Drug Name Recognition
Sep 24, 2016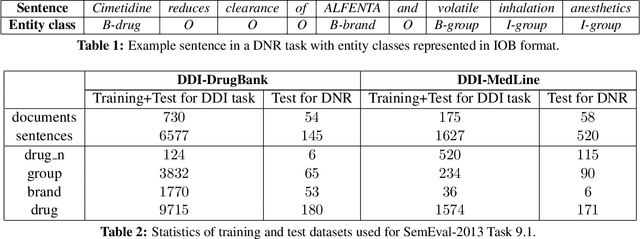
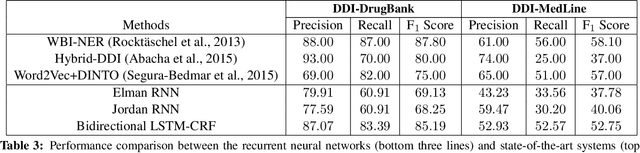
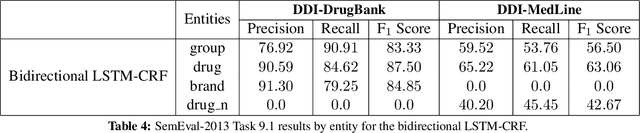
Drug name recognition (DNR) is an essential step in the Pharmacovigilance (PV) pipeline. DNR aims to find drug name mentions in unstructured biomedical texts and classify them into predefined categories. State-of-the-art DNR approaches heavily rely on hand crafted features and domain specific resources which are difficult to collect and tune. For this reason, this paper investigates the effectiveness of contemporary recurrent neural architectures - the Elman and Jordan networks and the bidirectional LSTM with CRF decoding - at performing DNR straight from the text. The experimental results achieved on the authoritative SemEval-2013 Task 9.1 benchmarks show that the bidirectional LSTM-CRF ranks closely to highly-dedicated, hand-crafted systems.