 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReWE: Regressing Word Embeddings for Regularization of Neural Machine Translation Systems
Paper and Code
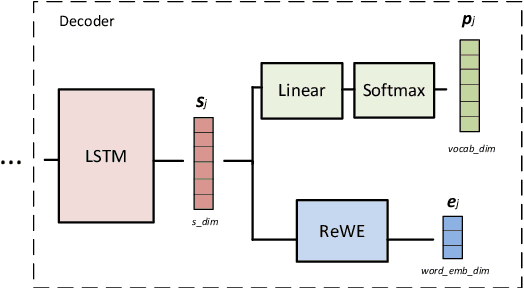
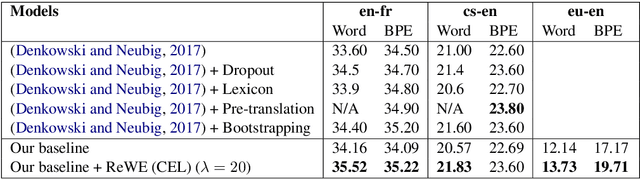
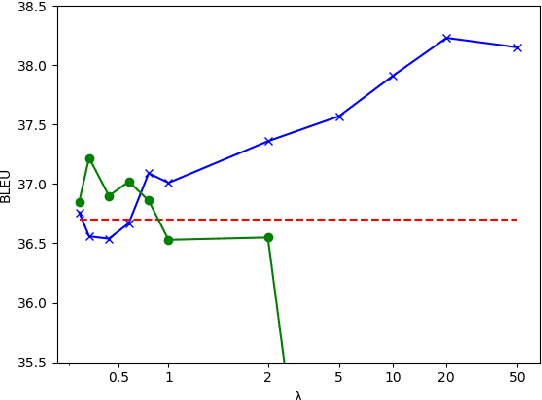
Regularization of neural machine translation is still a significant problem, especially in low-resource settings. To mollify this problem, we propose regressing word embeddings (ReWE) as a new regularization technique in a system that is jointly trained to predict the next word in the translation (categorical value) and its word embedding (continuous value). Such a joint training allows the proposed system to learn the distributional properties represented by the word embeddings, empirically improving the generalization to unseen sentences. Experiments over three translation datasets have showed a consistent improvement over a strong baseline, ranging between 0.91 and 2.54 BLEU points, and also a marked improvement over a state-of-the-art system.