 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedErrBench: A Fine-Grained Multilingual Benchmark for Medical Error Detection and Correction with Clinical Expert Annotations
Feb 05, 2026Inaccuracies in existing or generated clinical text may lead to serious adverse consequences, especially if it is a misdiagnosis or incorrect treatment suggestion. With Large Language Models (LLMs) increasingly being used across diverse healthcare applications, comprehensive evaluation through dedicated benchmarks is crucial. However, such datasets remain scarce, especially across diverse languages and contexts. In this paper, we introduce MedErrBench, the first multilingual benchmark for error detection, localization, and correction, developed under the guidance of experienced clinicians. Based on an expanded taxonomy of ten common error types, MedErrBench covers English, Arabic and Chinese, with natural clinical cases annotated and reviewed by domain experts. We assessed the performance of a range of general-purpose, language-specific, and medical-domain language models across all three tasks. Our results reveal notable performance gaps, particularly in non-English settings, highlighting the need for clinically grounded, language-aware systems. By making MedErrBench and our evaluation protocols publicly-available, we aim to advance multilingual clinical NLP to promote safer and more equitable AI-based healthcare globally. The dataset is available in the supplementary material. An anonymized version of the dataset is available at: https://github.com/congboma/MedErrBench.
MedAraBench: Large-Scale Arabic Medical Question Answering Dataset and Benchmark
Feb 02, 2026Arabic remains one of the most underrepresented languages in natural language processing research, particularly in medical applications, due to the limited availability of open-source data and benchmarks. The lack of resources hinders efforts to evaluate and advance the multilingual capabilities of Large Language Models (LLMs). In this paper, we introduce MedAraBench, a large-scale dataset consisting of Arabic multiple-choice question-answer pairs across various medical specialties. We constructed the dataset by manually digitizing a large repository of academic materials created by medical professionals in the Arabic-speaking region. We then conducted extensive preprocessing and split the dataset into training and test sets to support future research efforts in the area. To assess the quality of the data, we adopted two frameworks, namely expert human evaluation and LLM-as-a-judge. Our dataset is diverse and of high quality, spanning 19 specialties and five difficulty levels. For benchmarking purposes, we assessed the performance of eight state-of-the-art open-source and proprietary models, such as GPT-5, Gemini 2.0 Flash, and Claude 4-Sonnet. Our findings highlight the need for further domain-specific enhancements. We release the dataset and evaluation scripts to broaden the diversity of medical data benchmarks, expand the scope of evaluation suites for LLMs, and enhance the multilingual capabilities of models for deployment in clinical settings.
IncidentResponseGPT: Generating Traffic Incident Response Plans with Generative Artificial Intelligence
Apr 29, 2024



Traffic congestion due to road incidents poses a significant challenge in urban environments, leading to increased pollution, economic losses, and traffic congestion. Efficiently managing these incidents is imperative for mitigating their adverse effects; however, the complexity of urban traffic systems and the variety of potential incidents represent a considerable obstacle. This paper introduces IncidentResponseGPT, an innovative solution designed to assist traffic management authorities by providing rapid, informed, and adaptable traffic incident response plans. By integrating a Generative AI platform with real-time traffic incident reports and operational guidelines, our system aims to streamline the decision-making process in responding to traffic incidents. The research addresses the critical challenges involved in deploying AI in traffic management, including overcoming the complexity of urban traffic networks, ensuring real-time decision-making capabilities, aligning with local laws and regulations, and securing public acceptance for AI-driven systems. Through a combination of text analysis of accident reports, validation of AI recommendations through traffic simulation, and implementation of transparent and validated AI systems, IncidentResponseGPT offers a promising approach to optimizing traffic flow and reducing congestion in the face of traffic incidents. The relevance of this work extends to traffic management authorities, emergency response teams, and municipal bodies, all integral stakeholders in urban traffic control and incident management. By proposing a novel solution to the identified challenges, this research aims to develop a framework that not only facilitates faster resolution of traffic incidents but also minimizes their overall impact on urban traffic systems.
Integrating Large Language Models for Severity Classification in Traffic Incident Management: A Machine Learning Approach
Mar 20, 2024This study evaluates the impact of large language models on enhancing machine learning processes for managing traffic incidents. It examines the extent to which features generated by modern language models improve or match the accuracy of predictions when classifying the severity of incidents using accident reports. Multiple comparisons performed between combinations of language models and machine learning algorithms, including Gradient Boosted Decision Trees, Random Forests, and Extreme Gradient Boosting. Our research uses both conventional and language model-derived features from texts and incident reports, and their combinations to perform severity classification. Incorporating features from language models with those directly obtained from incident reports has shown to improve, or at least match, the performance of machine learning techniques in assigning severity levels to incidents, particularly when employing Random Forests and Extreme Gradient Boosting methods. This comparison was quantified using the F1-score over uniformly sampled data sets to obtain balanced severity classes. The primary contribution of this research is in the demonstration of how Large Language Models can be integrated into machine learning workflows for incident management, thereby simplifying feature extraction from unstructured text and enhancing or matching the precision of severity predictions using conventional machine learning pipeline. The engineering application of this research is illustrated through the effective use of these language processing models to refine the modelling process for incident severity classification. This work provides significant insights into the application of language processing capabilities in combination with traditional data for improving machine learning pipelines in the context of classifying incident severity.
Traffic Accident Risk Forecasting using Contextual Vision Transformers
Sep 20, 2022
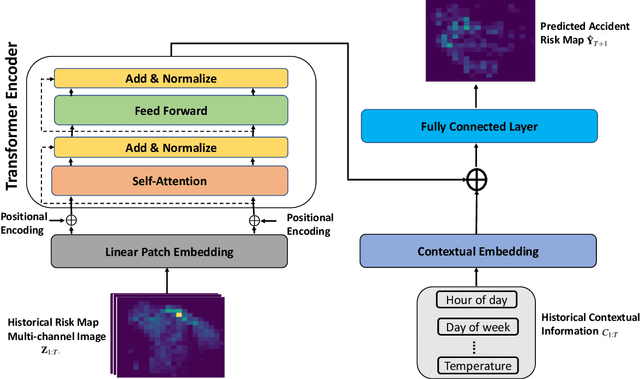
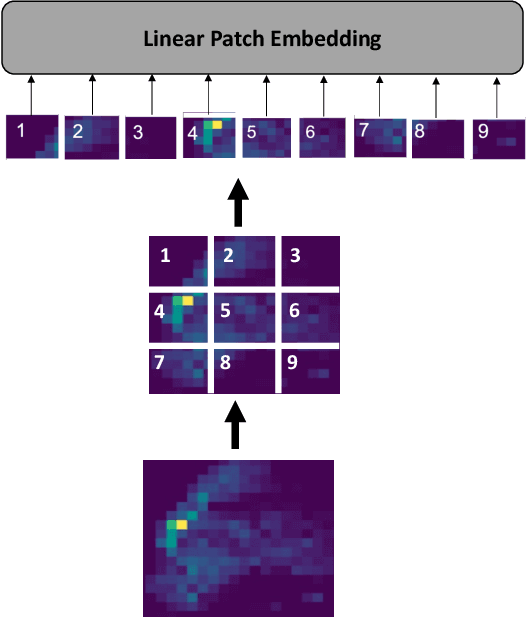
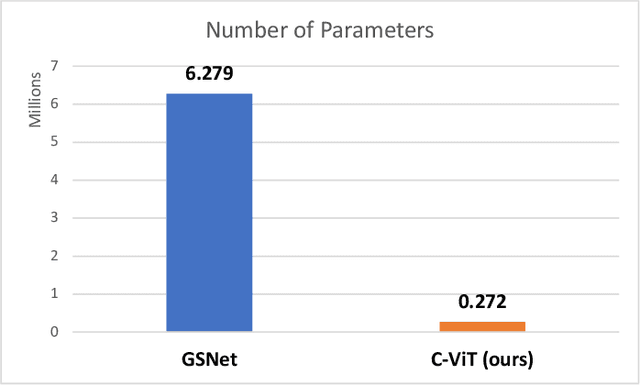
Recently, the problem of traffic accident risk forecasting has been getting the attention of the intelligent transportation systems community due to its significant impact on traffic clearance. This problem is commonly tackled in the literature by using data-driven approaches that model the spatial and temporal incident impact, since they were shown to be crucial for the traffic accident risk forecasting problem. To achieve this, most approaches build different architectures to capture the spatio-temporal correlations features, making them inefficient for large traffic accident datasets. Thus, in this work, we are proposing a novel unified framework, namely a contextual vision transformer, that can be trained in an end-to-end approach which can effectively reason about the spatial and temporal aspects of the problem while providing accurate traffic accident risk predictions. We evaluate and compare the performance of our proposed methodology against baseline approaches from the literature across two large-scale traffic accident datasets from two different geographical locations. The results have shown a significant improvement with roughly 2\% in RMSE score in comparison to previous state-of-art works (SoTA) in the literature. Moreover, our proposed approach has outperformed the SoTA technique over the two datasets while only requiring 23x fewer computational requirements.
Traffic incident duration prediction via a deep learning framework for text description encoding
Sep 19, 2022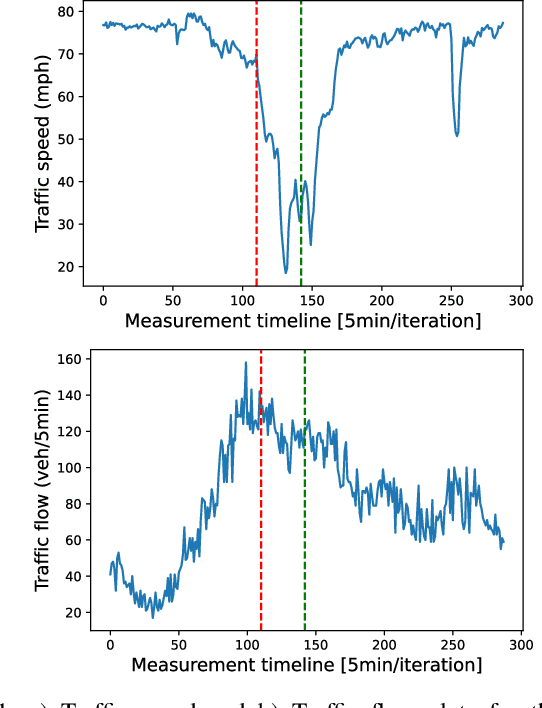
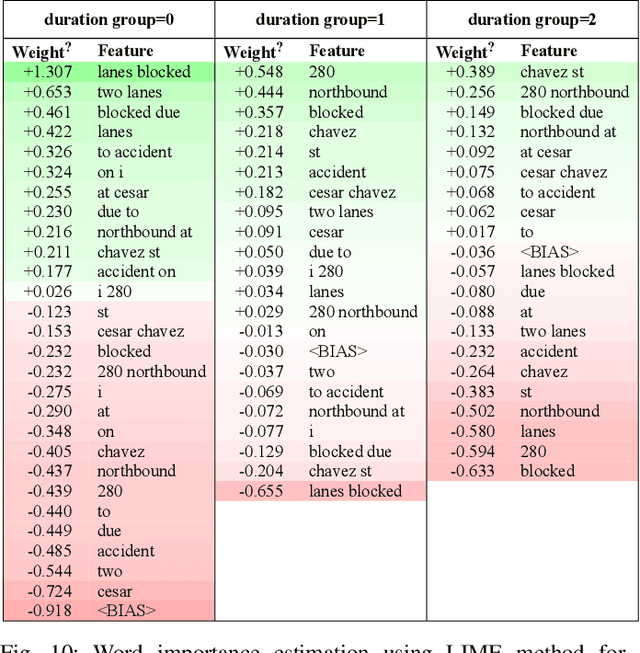
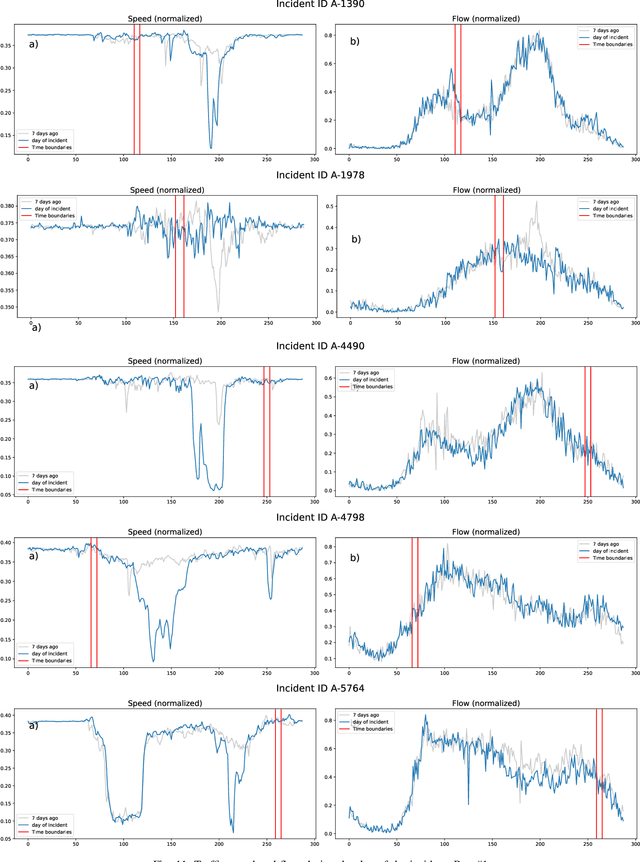
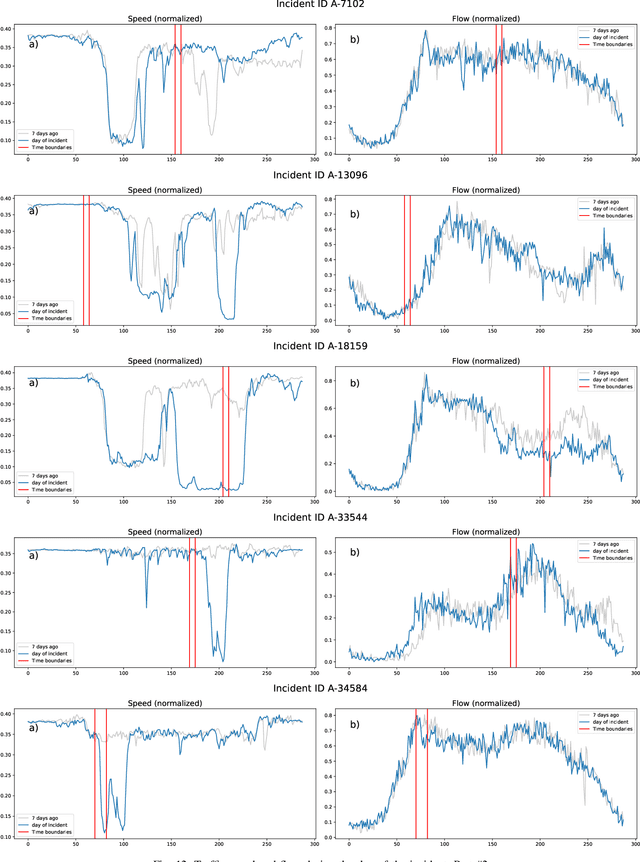
Predicting the traffic incident duration is a hard problem to solve due to the stochastic nature of incident occurrence in space and time, a lack of information at the beginning of a reported traffic disruption, and lack of advanced methods in transport engineering to derive insights from past accidents. This paper proposes a new fusion framework for predicting the incident duration from limited information by using an integration of machine learning with traffic flow/speed and incident description as features, encoded via several Deep Learning methods (ANN autoencoder and character-level LSTM-ANN sentiment classifier). The paper constructs a cross-disciplinary modelling approach in transport and data science. The approach improves the incident duration prediction accuracy over the top-performing ML models applied to baseline incident reports. Results show that our proposed method can improve the accuracy by $60\%$ when compared to standard linear or support vector regression models, and a further $7\%$ improvement with respect to the hybrid deep learning auto-encoded GBDT model which seems to outperform all other models. The application area is the city of San Francisco, rich in both traffic incident logs (Countrywide Traffic Accident Data set) and past historical traffic congestion information (5-minute precision measurements from Caltrans Performance Measurement System).
Pedestrian Trajectory Prediction using Context-Augmented Transformer Networks
Dec 03, 2020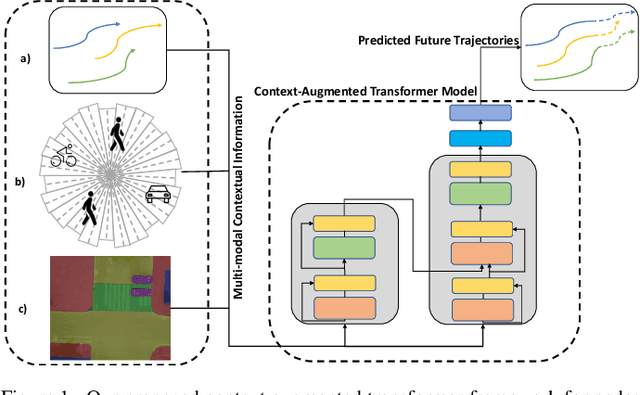

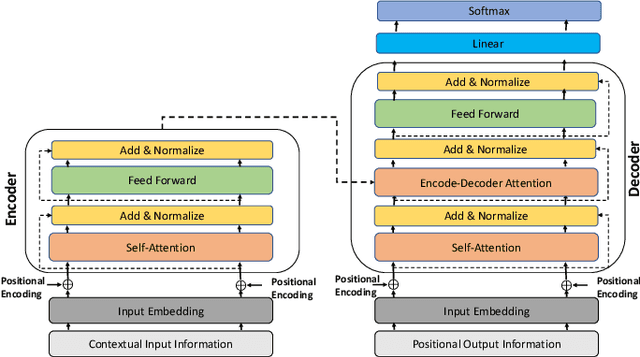

Forecasting the trajectory of pedestrians in shared urban traffic environments is still considered one of the challenging problems facing the development of autonomous vehicles (AVs). In the literature, this problem is often tackled using recurrent neural networks (RNNs). Despite the powerful capabilities of RNNs in capturing the temporal dependency in the pedestrians' motion trajectories, they were argued to be challenged when dealing with longer sequential data. Thus, in this work, we are introducing a framework based on the transformer networks that were shown recently to be more efficient and outperformed RNNs in many sequential-based tasks. We relied on a fusion of the past positional information, agent interactions information and scene physical semantics information as an input to our framework in order to provide a robust trajectory prediction of pedestrians. We have evaluated our framework on two real-life datasets of pedestrians in shared urban traffic environments and it has outperformed the compared baseline approaches in both short-term and long-term prediction horizons.
Fast Synthetic LiDAR Rendering via Spherical UV Unwrapping of Equirectangular Z-Buffer Images
Jun 08, 2020
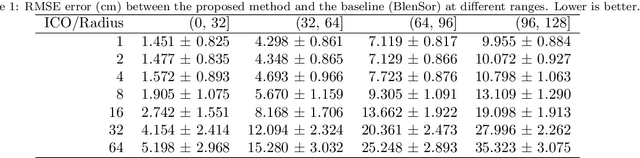


LiDAR data is becoming increasingly essential with the rise of autonomous vehicles. Its ability to provide 360deg horizontal field of view of point cloud, equips self-driving vehicles with enhanced situational awareness capabilities. While synthetic LiDAR data generation pipelines provide a good solution to advance the machine learning research on LiDAR, they do suffer from a major shortcoming, which is rendering time. Physically accurate LiDAR simulators (e.g. Blensor) are computationally expensive with an average rendering time of 14-60 seconds per frame for urban scenes. This is often compensated for via using 3D models with simplified polygon topology (low poly assets) as is the case of CARLA (Dosovitskiy et al., 2017). However, this comes at the price of having coarse grained unrealistic LiDAR point clouds. In this paper, we present a novel method to simulate LiDAR point cloud with faster rendering time of 1 sec per frame. The proposed method relies on spherical UV unwrapping of Equirectangular Z-Buffer images. We chose Blensor (Gschwandtner et al., 2011) as the baseline method to compare the point clouds generated using the proposed method. The reported error for complex urban landscapes is 4.28cm for a scanning range between 2-120 meters with Velodyne HDL64-E2 parameters. The proposed method reported a total time per frame to 3.2 +/- 0.31 seconds per frame. In contrast, the BlenSor baseline method reported 16.2 +/- 1.82 seconds.
Refined Continuous Control of DDPG Actors via Parametrised Activation
Jun 04, 2020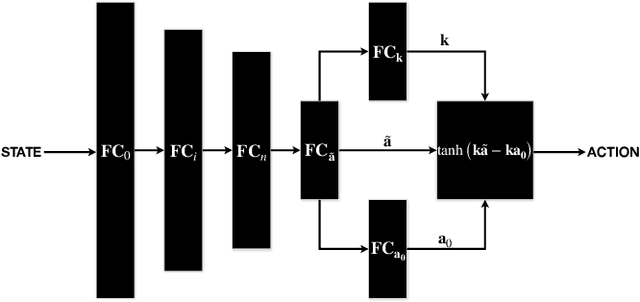
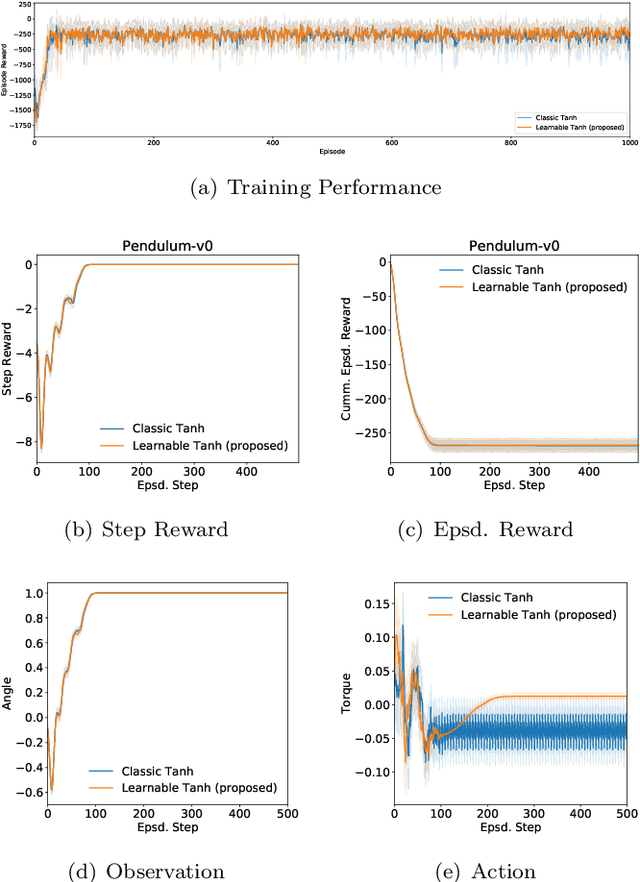
In this paper, we propose enhancing actor-critic reinforcement learning agents by parameterising the final actor layer which produces the actions in order to accommodate the behaviour discrepancy of different actuators, under different load conditions during interaction with the environment. We propose branching the action producing layer in the actor to learn the tuning parameter controlling the activation layer (e.g. Tanh and Sigmoid). The learned parameters are then used to create tailored activation functions for each actuator. We ran experiments on three OpenAI Gym environments, i.e. Pendulum-v0, LunarLanderContinuous-v2 and BipedalWalker-v2. Results have shown an average of 23.15% and 33.80% increase in total episode reward of the LunarLanderContinuous-v2 and BipedalWalker-v2 environments, respectively. There was no significant improvement in Pendulum-v0 environment but the proposed method produces a more stable actuation signal compared to the state-of-the-art method. The proposed method allows the reinforcement learning actor to produce more robust actions that accommodate the discrepancy in the actuators' response functions. This is particularly useful for real life scenarios where actuators exhibit different response functions depending on the load and the interaction with the environment. This also simplifies the transfer learning problem by fine tuning the parameterised activation layers instead of retraining the entire policy every time an actuator is replaced. Finally, the proposed method would allow better accommodation to biological actuators (e.g. muscles) in biomechanical systems.
Domain Adaptation for Vehicle Detection from Bird's Eye View LiDAR Point Cloud Data
May 22, 2019
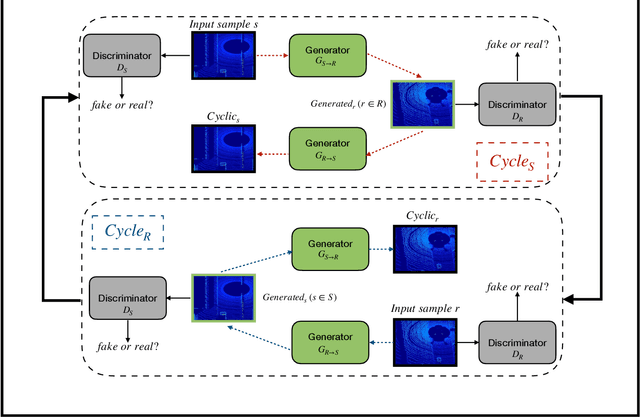

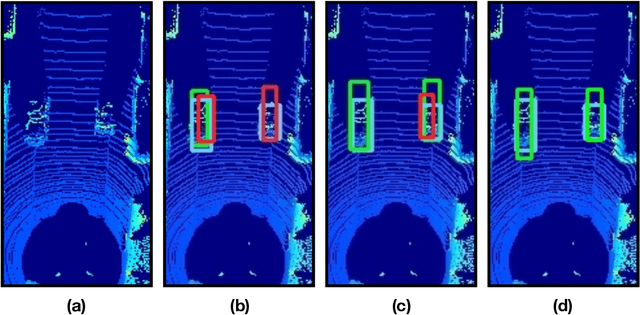
Point cloud data from 3D LiDAR sensors are one of the most crucial sensor modalities for versatile safety-critical applications such as self-driving vehicles. Since the annotations of point cloud data is an expensive and time-consuming process, therefore recently the utilisation of simulated environments and 3D LiDAR sensors for this task started to get some popularity. With simulated sensors and environments, the process for obtaining an annotated synthetic point cloud data became much easier. However, the generated synthetic point cloud data are still missing the artefacts usually exist in point cloud data from real 3D LiDAR sensors. As a result, the performance of the trained models on this data for perception tasks when tested on real point cloud data is degraded due to the domain shift between simulated and real environments. Thus, in this work, we are proposing a domain adaptation framework for bridging this gap between synthetic and real point cloud data. Our proposed framework is based on the deep cycle-consistent generative adversarial networks (CycleGAN) architecture. We have evaluated the performance of our proposed framework on the task of vehicle detection from a bird's eye view (BEV) point cloud images coming from real 3D LiDAR sensors. The framework has shown competitive results with an improvement of more than 7% in average precision score over other baseline approaches when tested on real BEV point cloud images.