 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Synthetic LiDAR Rendering via Spherical UV Unwrapping of Equirectangular Z-Buffer Images
Jun 08, 2020
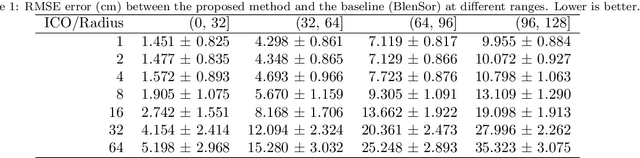


LiDAR data is becoming increasingly essential with the rise of autonomous vehicles. Its ability to provide 360deg horizontal field of view of point cloud, equips self-driving vehicles with enhanced situational awareness capabilities. While synthetic LiDAR data generation pipelines provide a good solution to advance the machine learning research on LiDAR, they do suffer from a major shortcoming, which is rendering time. Physically accurate LiDAR simulators (e.g. Blensor) are computationally expensive with an average rendering time of 14-60 seconds per frame for urban scenes. This is often compensated for via using 3D models with simplified polygon topology (low poly assets) as is the case of CARLA (Dosovitskiy et al., 2017). However, this comes at the price of having coarse grained unrealistic LiDAR point clouds. In this paper, we present a novel method to simulate LiDAR point cloud with faster rendering time of 1 sec per frame. The proposed method relies on spherical UV unwrapping of Equirectangular Z-Buffer images. We chose Blensor (Gschwandtner et al., 2011) as the baseline method to compare the point clouds generated using the proposed method. The reported error for complex urban landscapes is 4.28cm for a scanning range between 2-120 meters with Velodyne HDL64-E2 parameters. The proposed method reported a total time per frame to 3.2 +/- 0.31 seconds per frame. In contrast, the BlenSor baseline method reported 16.2 +/- 1.82 seconds.
Domain Adaptation for Vehicle Detection from Bird's Eye View LiDAR Point Cloud Data
May 22, 2019
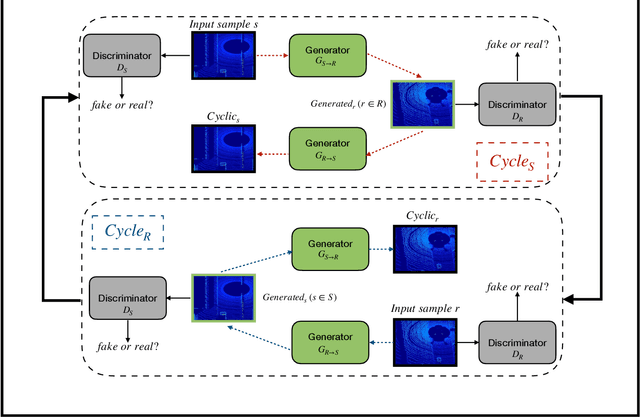

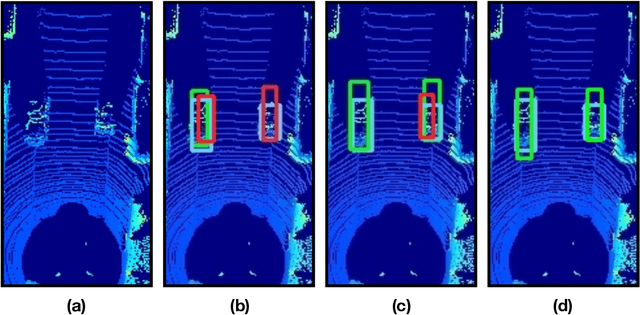
Point cloud data from 3D LiDAR sensors are one of the most crucial sensor modalities for versatile safety-critical applications such as self-driving vehicles. Since the annotations of point cloud data is an expensive and time-consuming process, therefore recently the utilisation of simulated environments and 3D LiDAR sensors for this task started to get some popularity. With simulated sensors and environments, the process for obtaining an annotated synthetic point cloud data became much easier. However, the generated synthetic point cloud data are still missing the artefacts usually exist in point cloud data from real 3D LiDAR sensors. As a result, the performance of the trained models on this data for perception tasks when tested on real point cloud data is degraded due to the domain shift between simulated and real environments. Thus, in this work, we are proposing a domain adaptation framework for bridging this gap between synthetic and real point cloud data. Our proposed framework is based on the deep cycle-consistent generative adversarial networks (CycleGAN) architecture. We have evaluated the performance of our proposed framework on the task of vehicle detection from a bird's eye view (BEV) point cloud images coming from real 3D LiDAR sensors. The framework has shown competitive results with an improvement of more than 7% in average precision score over other baseline approaches when tested on real BEV point cloud images.
SSIMLayer: Towards Robust Deep Representation Learning via Nonlinear Structural Similarity
Jul 28, 2018



Deeper convolutional neural networks provide more capacity to approximate complex mapping functions. However, increasing network depth imposes difficulties on training and increases model complexity. This paper presents a new nonlinear computational layer of considerably high capacity to the deep convolutional neural network architectures. This layer performs a set of comprehensive convolution operations that mimics the overall function of the human visual system (HVS) via focusing on learning structural information in its input. The core of its computations is evaluating the components of the structural similarity metric (SSIM) in a setting that allows the kernels to learn to match structural information. The proposed SSIMLayer is inherently nonlinear and hence, it does not require subsequent nonlinear transformations. Experiments conducted on CIFAR-10 benchmark demonstrates that the SSIMLayer provides better convergence than the traditional convolutional layer, bypasses the need for nonlinear transformations and shows more robustness against noise perturbations and adversarial attacks.