 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Synthetic LiDAR Rendering via Spherical UV Unwrapping of Equirectangular Z-Buffer Images
Jun 08, 2020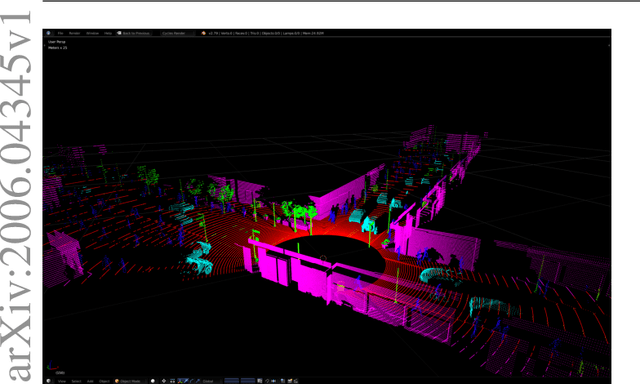


LiDAR data is becoming increasingly essential with the rise of autonomous vehicles. Its ability to provide 360deg horizontal field of view of point cloud, equips self-driving vehicles with enhanced situational awareness capabilities. While synthetic LiDAR data generation pipelines provide a good solution to advance the machine learning research on LiDAR, they do suffer from a major shortcoming, which is rendering time. Physically accurate LiDAR simulators (e.g. Blensor) are computationally expensive with an average rendering time of 14-60 seconds per frame for urban scenes. This is often compensated for via using 3D models with simplified polygon topology (low poly assets) as is the case of CARLA (Dosovitskiy et al., 2017). However, this comes at the price of having coarse grained unrealistic LiDAR point clouds. In this paper, we present a novel method to simulate LiDAR point cloud with faster rendering time of 1 sec per frame. The proposed method relies on spherical UV unwrapping of Equirectangular Z-Buffer images. We chose Blensor (Gschwandtner et al., 2011) as the baseline method to compare the point clouds generated using the proposed method. The reported error for complex urban landscapes is 4.28cm for a scanning range between 2-120 meters with Velodyne HDL64-E2 parameters. The proposed method reported a total time per frame to 3.2 +/- 0.31 seconds per frame. In contrast, the BlenSor baseline method reported 16.2 +/- 1.82 seconds.
Refined Continuous Control of DDPG Actors via Parametrised Activation
Jun 04, 2020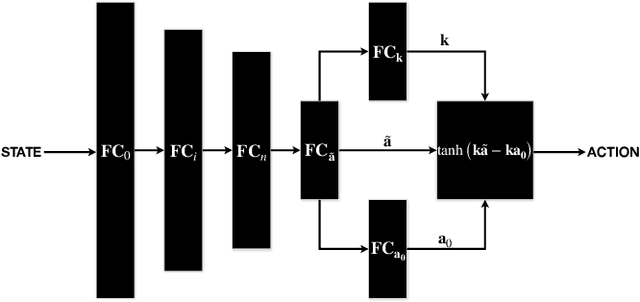
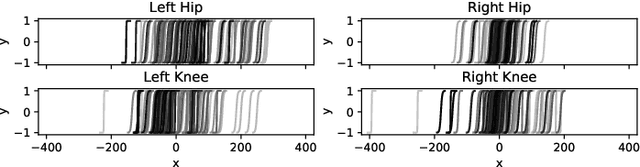
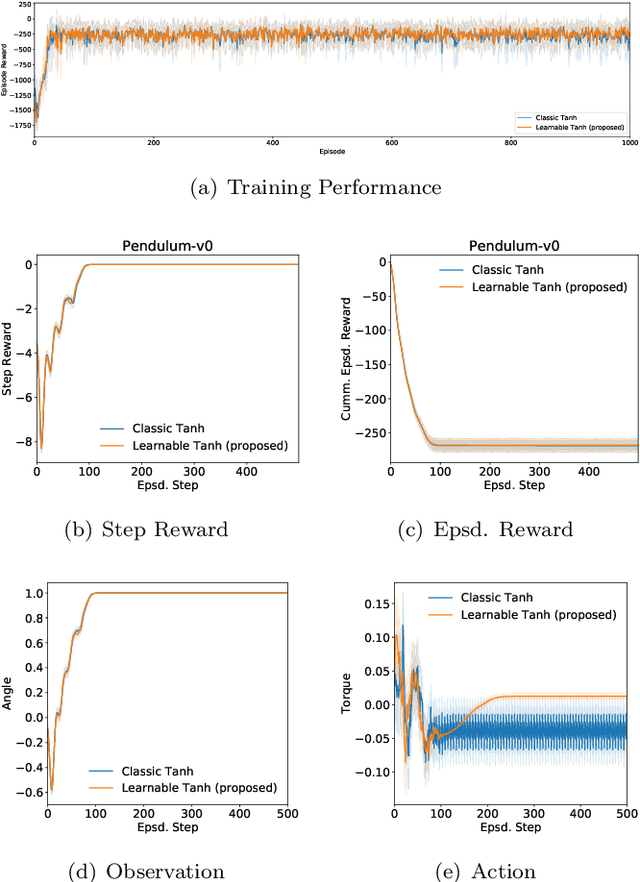
In this paper, we propose enhancing actor-critic reinforcement learning agents by parameterising the final actor layer which produces the actions in order to accommodate the behaviour discrepancy of different actuators, under different load conditions during interaction with the environment. We propose branching the action producing layer in the actor to learn the tuning parameter controlling the activation layer (e.g. Tanh and Sigmoid). The learned parameters are then used to create tailored activation functions for each actuator. We ran experiments on three OpenAI Gym environments, i.e. Pendulum-v0, LunarLanderContinuous-v2 and BipedalWalker-v2. Results have shown an average of 23.15% and 33.80% increase in total episode reward of the LunarLanderContinuous-v2 and BipedalWalker-v2 environments, respectively. There was no significant improvement in Pendulum-v0 environment but the proposed method produces a more stable actuation signal compared to the state-of-the-art method. The proposed method allows the reinforcement learning actor to produce more robust actions that accommodate the discrepancy in the actuators' response functions. This is particularly useful for real life scenarios where actuators exhibit different response functions depending on the load and the interaction with the environment. This also simplifies the transfer learning problem by fine tuning the parameterised activation layers instead of retraining the entire policy every time an actuator is replaced. Finally, the proposed method would allow better accommodation to biological actuators (e.g. muscles) in biomechanical systems.
Domain Adaptation for Vehicle Detection from Bird's Eye View LiDAR Point Cloud Data
May 22, 2019
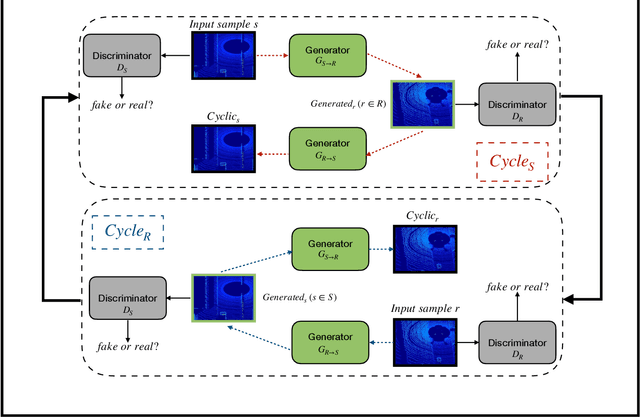

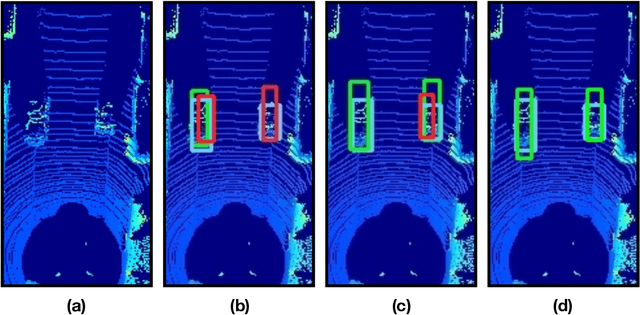
Point cloud data from 3D LiDAR sensors are one of the most crucial sensor modalities for versatile safety-critical applications such as self-driving vehicles. Since the annotations of point cloud data is an expensive and time-consuming process, therefore recently the utilisation of simulated environments and 3D LiDAR sensors for this task started to get some popularity. With simulated sensors and environments, the process for obtaining an annotated synthetic point cloud data became much easier. However, the generated synthetic point cloud data are still missing the artefacts usually exist in point cloud data from real 3D LiDAR sensors. As a result, the performance of the trained models on this data for perception tasks when tested on real point cloud data is degraded due to the domain shift between simulated and real environments. Thus, in this work, we are proposing a domain adaptation framework for bridging this gap between synthetic and real point cloud data. Our proposed framework is based on the deep cycle-consistent generative adversarial networks (CycleGAN) architecture. We have evaluated the performance of our proposed framework on the task of vehicle detection from a bird's eye view (BEV) point cloud images coming from real 3D LiDAR sensors. The framework has shown competitive results with an improvement of more than 7% in average precision score over other baseline approaches when tested on real BEV point cloud images.
Diacritization of Maghrebi Arabic Sub-Dialects
Oct 29, 2018
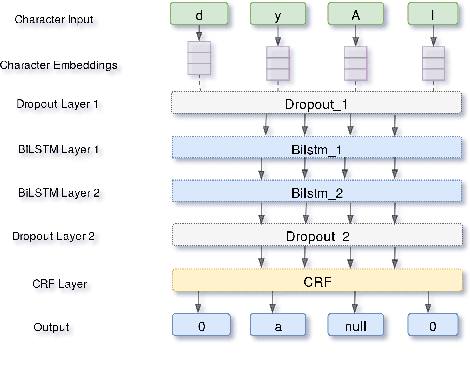
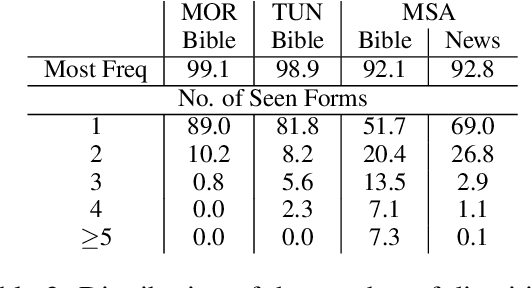
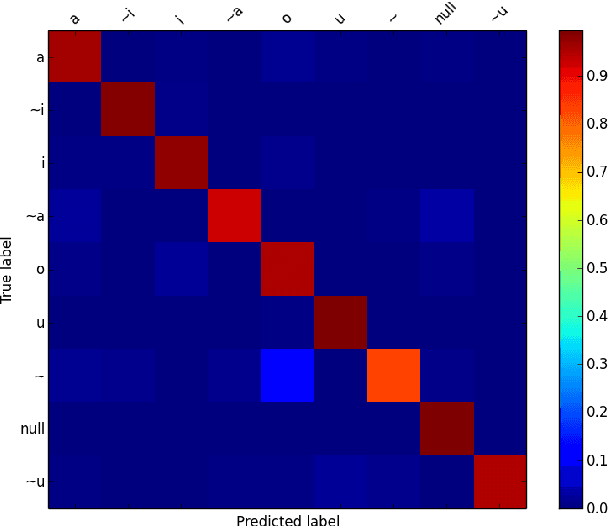
Diacritization process attempt to restore the short vowels in Arabic written text; which typically are omitted. This process is essential for applications such as Text-to-Speech (TTS). While diacritization of Modern Standard Arabic (MSA) still holds the lion share, research on dialectal Arabic (DA) diacritization is very limited. In this paper, we present our contribution and results on the automatic diacritization of two sub-dialects of Maghrebi Arabic, namely Tunisian and Moroccan, using a character-level deep neural network architecture that stacks two bi-LSTM layers over a CRF output layer. The model achieves word error rate of 2.7% and 3.6% for Moroccan and Tunisian respectively and is capable of implicitly identifying the sub-dialect of the input.
Arabic Multi-Dialect Segmentation: bi-LSTM-CRF vs. SVM
Aug 19, 2017
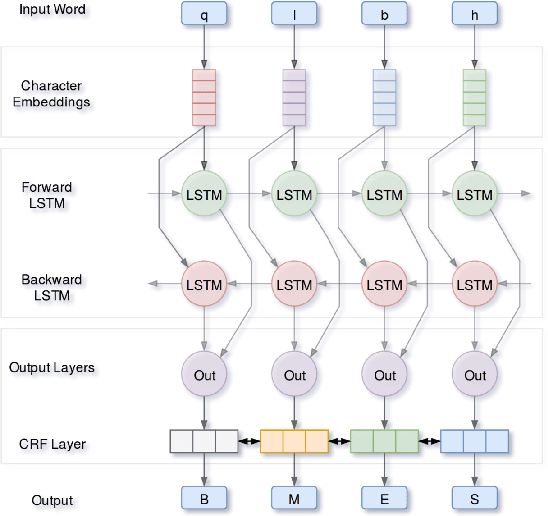
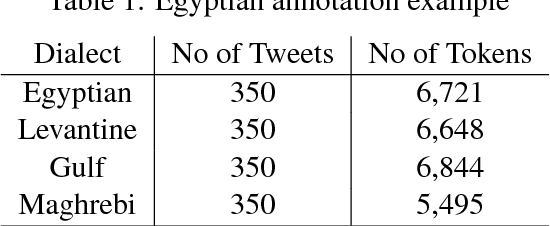
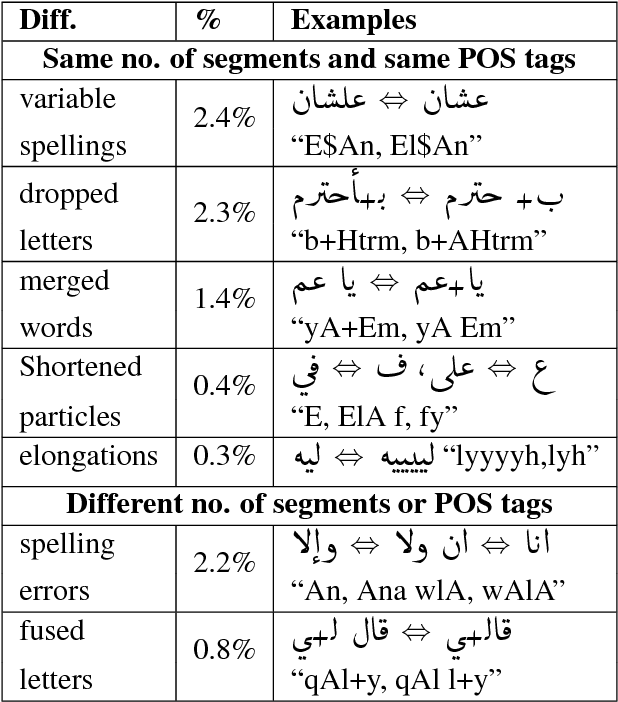
Arabic word segmentation is essential for a variety of NLP applications such as machine translation and information retrieval. Segmentation entails breaking words into their constituent stems, affixes and clitics. In this paper, we compare two approaches for segmenting four major Arabic dialects using only several thousand training examples for each dialect. The two approaches involve posing the problem as a ranking problem, where an SVM ranker picks the best segmentation, and as a sequence labeling problem, where a bi-LSTM RNN coupled with CRF determines where best to segment words. We are able to achieve solid segmentation results for all dialects using rather limited training data. We also show that employing Modern Standard Arabic data for domain adaptation and assuming context independence improve overall results.