 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of gait phase detection using traditional machine learning and deep learning techniques
Mar 07, 2024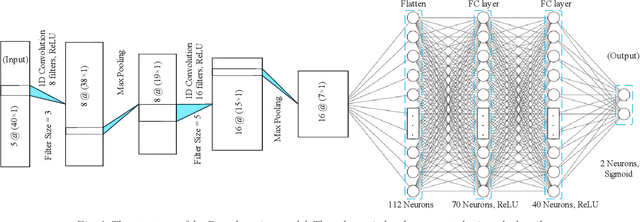
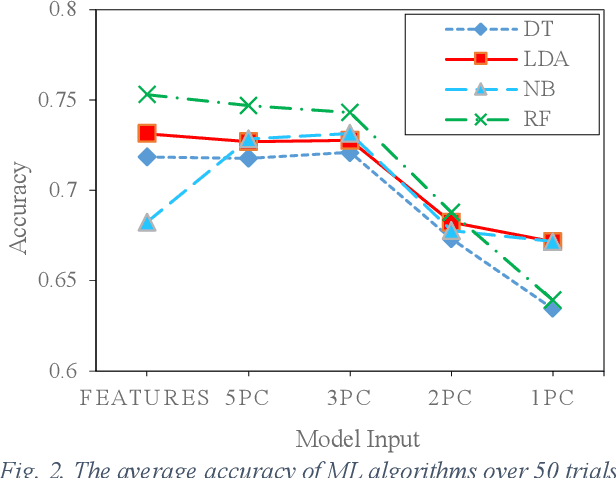


Human walking is a complex activity with a high level of cooperation and interaction between different systems in the body. Accurate detection of the phases of the gait in real-time is crucial to control lower-limb assistive devices like exoskeletons and prostheses. There are several ways to detect the walking gait phase, ranging from cameras and depth sensors to the sensors attached to the device itself or the human body. Electromyography (EMG) is one of the input methods that has captured lots of attention due to its precision and time delay between neuromuscular activity and muscle movement. This study proposes a few Machine Learning (ML) based models on lower-limb EMG data for human walking. The proposed models are based on Gaussian Naive Bayes (NB), Decision Tree (DT), Random Forest (RF), Linear Discriminant Analysis (LDA) and Deep Convolutional Neural Networks (DCNN). The traditional ML models are trained on hand-crafted features or their reduced components using Principal Component Analysis (PCA). On the contrary, the DCNN model utilises convolutional layers to extract features from raw data. The results show up to 75% average accuracy for traditional ML models and 79% for Deep Learning (DL) model. The highest achieved accuracy in 50 trials of the training DL model is 89.5%.
* Copyright \c{opyright} This is the accepted version of an article published in the proceedings of the 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC)
Machine Learning Meets Advanced Robotic Manipulation
Sep 22, 2023
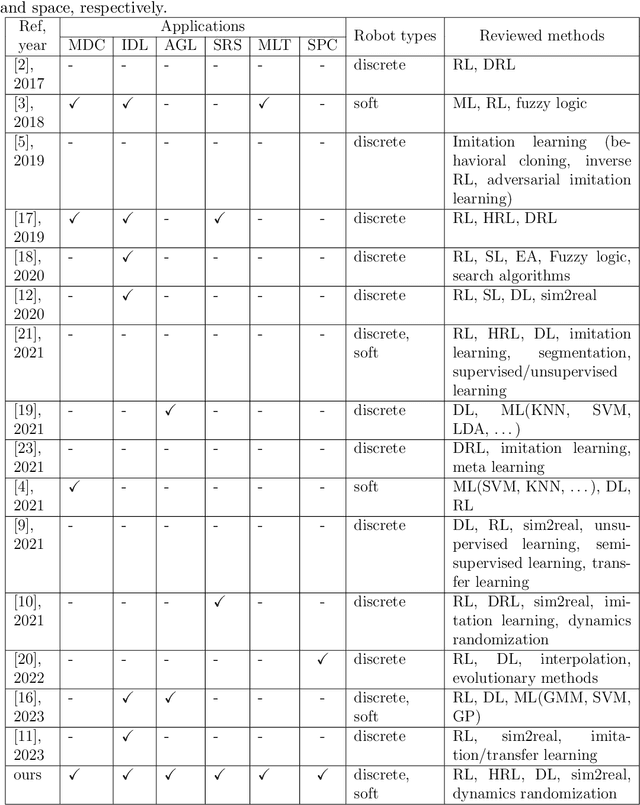
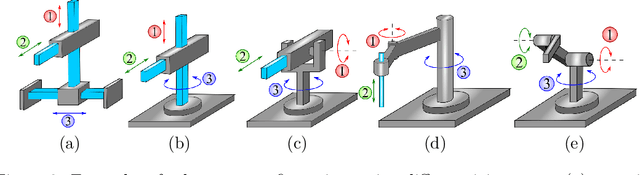
Automated industries lead to high quality production, lower manufacturing cost and better utilization of human resources. Robotic manipulator arms have major role in the automation process. However, for complex manipulation tasks, hard coding efficient and safe trajectories is challenging and time consuming. Machine learning methods have the potential to learn such controllers based on expert demonstrations. Despite promising advances, better approaches must be developed to improve safety, reliability, and efficiency of ML methods in both training and deployment phases. This survey aims to review cutting edge technologies and recent trends on ML methods applied to real-world manipulation tasks. After reviewing the related background on ML, the rest of the paper is devoted to ML applications in different domains such as industry, healthcare, agriculture, space, military, and search and rescue. The paper is closed with important research directions for future works.
A Comprehensive Review on Autonomous Navigation
Dec 24, 2022



The field of autonomous mobile robots has undergone dramatic advancements over the past decades. Despite achieving important milestones, several challenges are yet to be addressed. Aggregating the achievements of the robotic community as survey papers is vital to keep the track of current state-of-the-art and the challenges that must be tackled in the future. This paper tries to provide a comprehensive review of autonomous mobile robots covering topics such as sensor types, mobile robot platforms, simulation tools, path planning and following, sensor fusion methods, obstacle avoidance, and SLAM. The urge to present a survey paper is twofold. First, autonomous navigation field evolves fast so writing survey papers regularly is crucial to keep the research community well-aware of the current status of this field. Second, deep learning methods have revolutionized many fields including autonomous navigation. Therefore, it is necessary to give an appropriate treatment of the role of deep learning in autonomous navigation as well which is covered in this paper. Future works and research gaps will also be discussed.
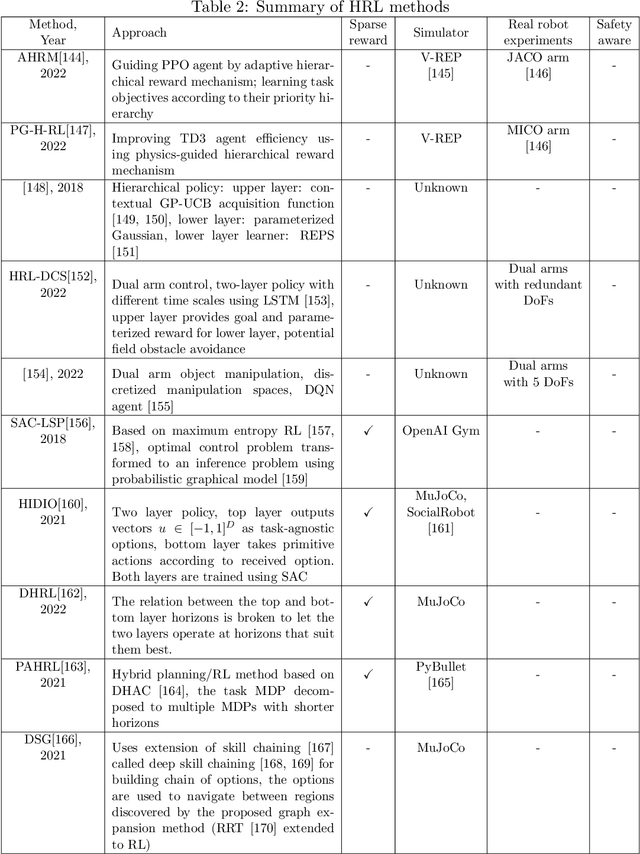
Critical Review of Exoskeleton Technology: State of the art and development of physical and cognitive human-robot interface
Dec 07, 2021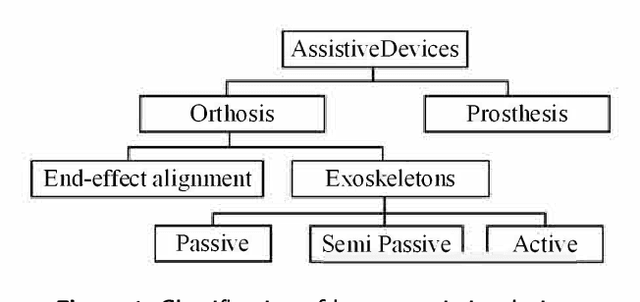
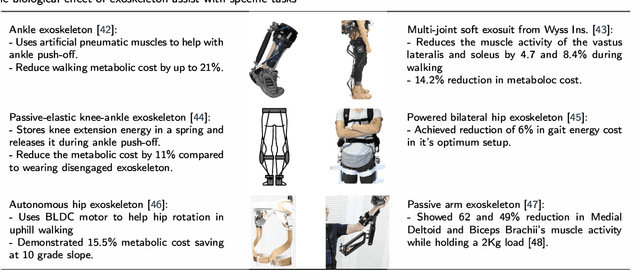
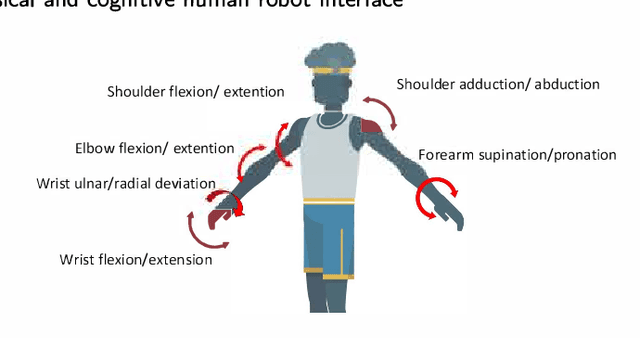
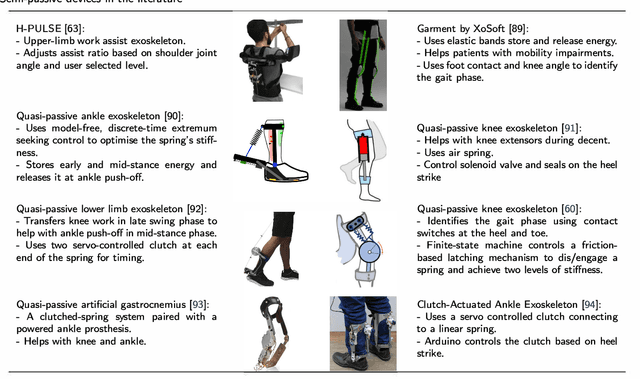
Exoskeletons and orthoses are wearable mobile systems providing mechanical benefits to the users. Despite significant improvements in the last decades, the technology is not fully mature to be adopted for strenuous and non-programmed tasks. To accommodate this insufficiency, different aspects of this technology need to be analysed and improved. Numerous studies have been trying to address some aspects of exoskeletons, e.g. mechanism design, intent prediction, and control scheme. However, most works have focused on a specific element of design or application without providing a comprehensive review framework. This study aims to analyse and survey the contributing aspects to the improvement and broad adoption of this technology. To address this, after introducing assistive devices and exoskeletons, the main design criteria will be investigated from a physical Human-Robot Interface (HRI) perspective. The study will be further developed by outlining several examples of known assistive devices in different categories. In order to establish an intelligent HRI strategy and enabling intuitive control for users, cognitive HRI will be investigated. Various approaches to this strategy will be reviewed, and a model for intent prediction will be proposed. This model is utilised to predict the gate phase from a single Electromyography (EMG) channel input. The outcomes of modelling show the potential use of single-channel input in low-power assistive devices. Furthermore, the proposed model can provide redundancy in devices with a complex control strategy.
An Uncertainty-aware Transfer Learning-based Framework for Covid-19 Diagnosis
Jul 26, 2020


The early and reliable detection of COVID-19 infected patients is essential to prevent and limit its outbreak. The PCR tests for COVID-19 detection are not available in many countries and also there are genuine concerns about their reliability and performance. Motivated by these shortcomings, this paper proposes a deep uncertainty-aware transfer learning framework for COVID-19 detection using medical images. Four popular convolutional neural networks (CNNs) including VGG16, ResNet50, DenseNet121, and InceptionResNetV2 are first applied to extract deep features from chest X-ray and computed tomography (CT) images. Extracted features are then processed by different machine learning and statistical modelling techniques to identify COVID-19 cases. We also calculate and report the epistemic uncertainty of classification results to identify regions where the trained models are not confident about their decisions (out of distribution problem). Comprehensive simulation results for X-ray and CT image datasets indicate that linear support vector machine and neural network models achieve the best results as measured by accuracy, sensitivity, specificity, and AUC. Also it is found that predictive uncertainty estimates are much higher for CT images compared to X-ray images.
Material Recognition for Automated Progress Monitoring using Deep Learning Methods
Jun 29, 2020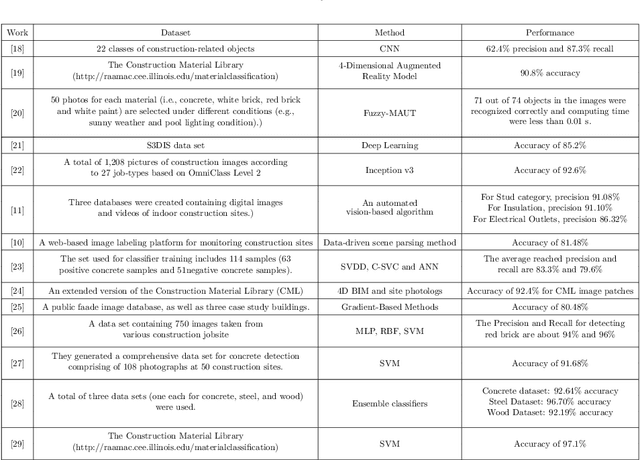

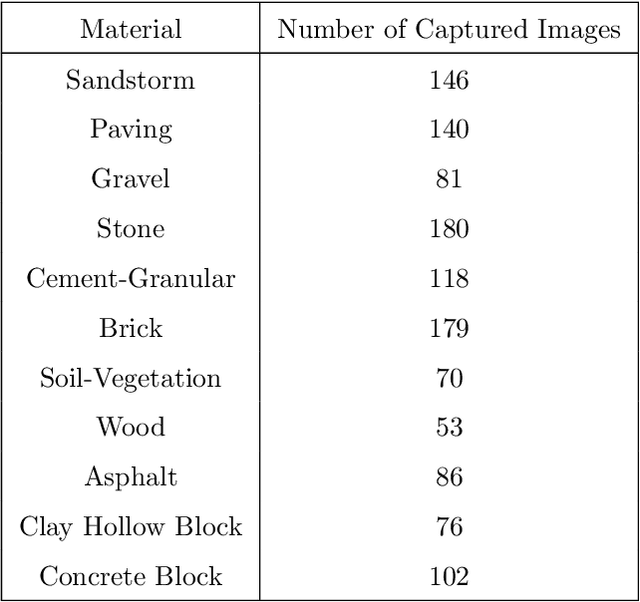
Recent advancements in Artificial intelligence, especially deep learning, has changed many fields irreversibly by introducing state of the art methods for automation. Construction monitoring has not been an exception; as a part of construction monitoring systems, material classification and recognition have drawn the attention of deep learning and machine vision researchers. However, to create production-ready systems, there is still a long path to cover. Real-world problems such as varying illuminations and reaching acceptable accuracies need to be addressed in order to create robust systems. In this paper, we have addressed these issues and reached a state of the art performance, i.e., 97.35% accuracy rate for this task. Also, a new dataset containing 1231 images of 11 classes taken from several construction sites is gathered and publicly published to help other researchers in this field.
Domain Adaptation for Vehicle Detection from Bird's Eye View LiDAR Point Cloud Data
May 22, 2019
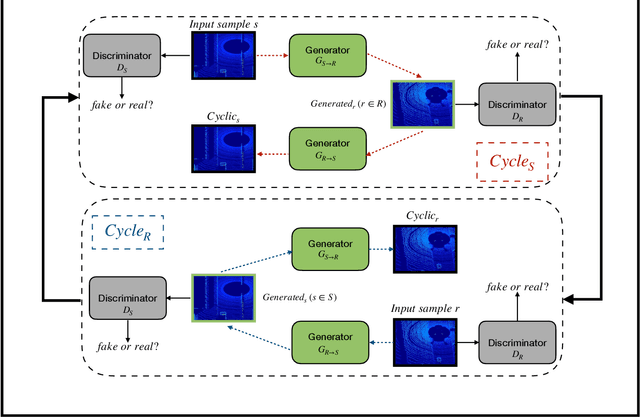

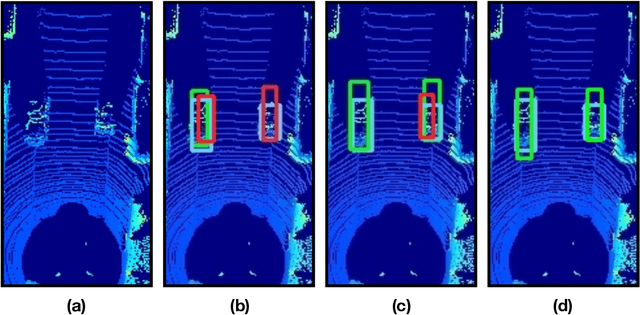
Point cloud data from 3D LiDAR sensors are one of the most crucial sensor modalities for versatile safety-critical applications such as self-driving vehicles. Since the annotations of point cloud data is an expensive and time-consuming process, therefore recently the utilisation of simulated environments and 3D LiDAR sensors for this task started to get some popularity. With simulated sensors and environments, the process for obtaining an annotated synthetic point cloud data became much easier. However, the generated synthetic point cloud data are still missing the artefacts usually exist in point cloud data from real 3D LiDAR sensors. As a result, the performance of the trained models on this data for perception tasks when tested on real point cloud data is degraded due to the domain shift between simulated and real environments. Thus, in this work, we are proposing a domain adaptation framework for bridging this gap between synthetic and real point cloud data. Our proposed framework is based on the deep cycle-consistent generative adversarial networks (CycleGAN) architecture. We have evaluated the performance of our proposed framework on the task of vehicle detection from a bird's eye view (BEV) point cloud images coming from real 3D LiDAR sensors. The framework has shown competitive results with an improvement of more than 7% in average precision score over other baseline approaches when tested on real BEV point cloud images.