 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-level Cross-view Geo-localization with Location Enhancement and Multi-Head Cross Attention
May 23, 2025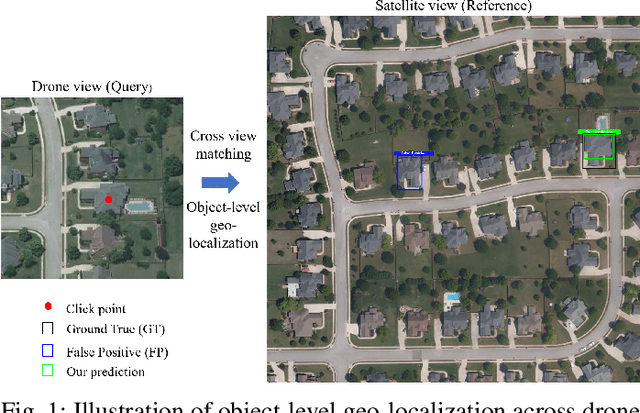
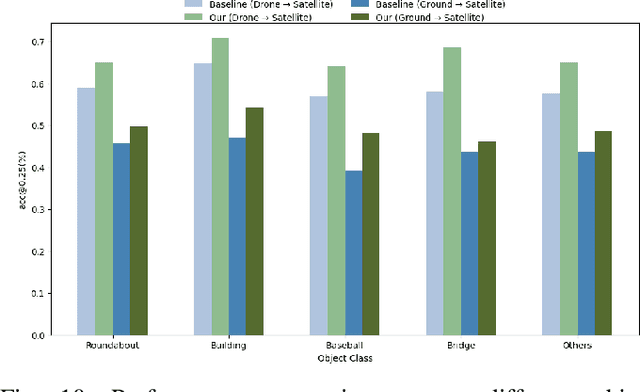
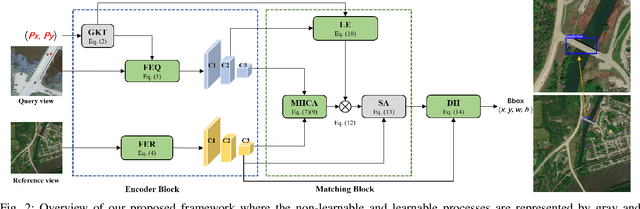
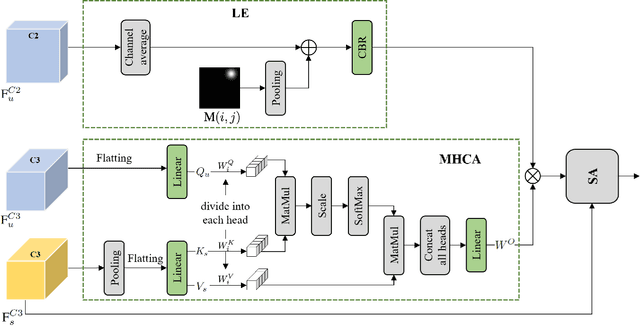
Cross-view geo-localization determines the location of a query image, captured by a drone or ground-based camera, by matching it to a geo-referenced satellite image. While traditional approaches focus on image-level localization, many applications, such as search-and-rescue, infrastructure inspection, and precision delivery, demand object-level accuracy. This enables users to prompt a specific object with a single click on a drone image to retrieve precise geo-tagged information of the object. However, variations in viewpoints, timing, and imaging conditions pose significant challenges, especially when identifying visually similar objects in extensive satellite imagery. To address these challenges, we propose an Object-level Cross-view Geo-localization Network (OCGNet). It integrates user-specified click locations using Gaussian Kernel Transfer (GKT) to preserve location information throughout the network. This cue is dually embedded into the feature encoder and feature matching blocks, ensuring robust object-specific localization. Additionally, OCGNet incorporates a Location Enhancement (LE) module and a Multi-Head Cross Attention (MHCA) module to adaptively emphasize object-specific features or expand focus to relevant contextual regions when necessary. OCGNet achieves state-of-the-art performance on a public dataset, CVOGL. It also demonstrates few-shot learning capabilities, effectively generalizing from limited examples, making it suitable for diverse applications (https://github.com/ZheyangH/OCGNet).
Learning-Based Approximate Nonlinear Model Predictive Control Motion Cueing
Apr 01, 2025Motion Cueing Algorithms (MCAs) encode the movement of simulated vehicles into movement that can be reproduced with a motion simulator to provide a realistic driving experience within the capabilities of the machine. This paper introduces a novel learning-based MCA for serial robot-based motion simulators. Building on the differentiable predictive control framework, the proposed method merges the advantages of Nonlinear Model Predictive Control (NMPC) - notably nonlinear constraint handling and accurate kinematic modeling - with the computational efficiency of machine learning. By shifting the computational burden to offline training, the new algorithm enables real-time operation at high control rates, thus overcoming the key challenge associated with NMPC-based motion cueing. The proposed MCA incorporates a nonlinear joint-space plant model and a policy network trained to mimic NMPC behavior while accounting for joint acceleration, velocity, and position limits. Simulation experiments across multiple motion cueing scenarios showed that the proposed algorithm performed on par with a state-of-the-art NMPC-based alternative in terms of motion cueing quality as quantified by the RMSE and correlation coefficient with respect to reference signals. However, the proposed algorithm was on average 400 times faster than the NMPC baseline. In addition, the algorithm successfully generalized to unseen operating conditions, including motion cueing scenarios on a different vehicle and real-time physics-based simulations.
Enhancing Cognitive Workload Classification Using Integrated LSTM Layers and CNNs for fNIRS Data Analysis
Jul 22, 2024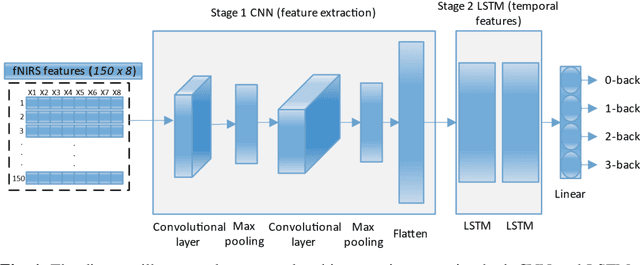

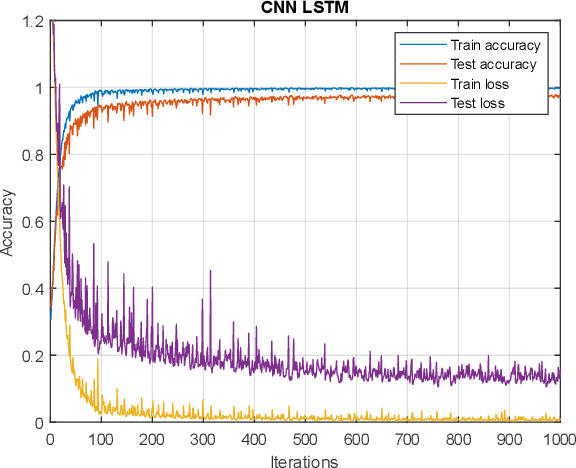

Functional near-infrared spectroscopy (fNIRS) is employed as a non-invasive method to monitor functional brain activation by capturing changes in the concentrations of oxygenated haemoglobin (HbO) and deoxygenated haemo-globin (HbR). Various machine learning classification techniques have been utilized to distinguish cognitive states. However, conventional machine learning methods, although simpler to implement, undergo a complex pre-processing phase before network training and demonstrate reduced accuracy due to inadequate data preprocessing. Additionally, previous research in cog-nitive load assessment using fNIRS has predominantly focused on differ-sizeentiating between two levels of mental workload. These studies mainly aim to classify low and high levels of cognitive load or distinguish between easy and difficult tasks. To address these limitations associated with conven-tional methods, this paper conducts a comprehensive exploration of the im-pact of Long Short-Term Memory (LSTM) layers on the effectiveness of Convolutional Neural Networks (CNNs) within deep learning models. This is to address the issues related to spatial features overfitting and lack of tem-poral dependencies in CNN in the previous studies. By integrating LSTM layers, the model can capture temporal dependencies in the fNIRS data, al-lowing for a more comprehensive understanding of cognitive states. The primary objective is to assess how incorporating LSTM layers enhances the performance of CNNs. The experimental results presented in this paper demonstrate that the integration of LSTM layers with Convolutional layers results in an increase in the accuracy of deep learning models from 97.40% to 97.92%.
Methods for Class-Imbalanced Learning with Support Vector Machines: A Review and an Empirical Evaluation
Jun 05, 2024This paper presents a review on methods for class-imbalanced learning with the Support Vector Machine (SVM) and its variants. We first explain the structure of SVM and its variants and discuss their inefficiency in learning with class-imbalanced data sets. We introduce a hierarchical categorization of SVM-based models with respect to class-imbalanced learning. Specifically, we categorize SVM-based models into re-sampling, algorithmic, and fusion methods, and discuss the principles of the representative models in each category. In addition, we conduct a series of empirical evaluations to compare the performances of various representative SVM-based models in each category using benchmark imbalanced data sets, ranging from low to high imbalanced ratios. Our findings reveal that while algorithmic methods are less time-consuming owing to no data pre-processing requirements, fusion methods, which combine both re-sampling and algorithmic approaches, generally perform the best, but with a higher computational load. A discussion on research gaps and future research directions is provided.
Generalized Laplace Approximation
May 22, 2024
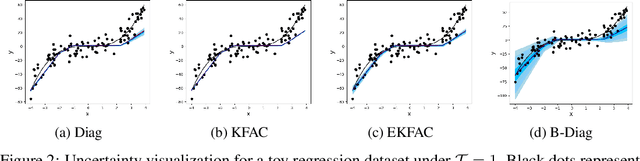


In recent years, the inconsistency in Bayesian deep learning has garnered increasing attention. Tempered or generalized posterior distributions often offer a direct and effective solution to this issue. However, understanding the underlying causes and evaluating the effectiveness of generalized posteriors remain active areas of research. In this study, we introduce a unified theoretical framework to attribute Bayesian inconsistency to model misspecification and inadequate priors. We interpret the generalization of the posterior with a temperature factor as a correction for misspecified models through adjustments to the joint probability model, and the recalibration of priors by redistributing probability mass on models within the hypothesis space using data samples. Additionally, we highlight a distinctive feature of Laplace approximation, which ensures that the generalized normalizing constant can be treated as invariant, unlike the typical scenario in general Bayesian learning where this constant varies with model parameters post-generalization. Building on this insight, we propose the generalized Laplace approximation, which involves a simple adjustment to the computation of the Hessian matrix of the regularized loss function. This method offers a flexible and scalable framework for obtaining high-quality posterior distributions. We assess the performance and properties of the generalized Laplace approximation on state-of-the-art neural networks and real-world datasets.
HSViT: Horizontally Scalable Vision Transformer
Apr 08, 2024



While the Vision Transformer (ViT) architecture gains prominence in computer vision and attracts significant attention from multimedia communities, its deficiency in prior knowledge (inductive bias) regarding shift, scale, and rotational invariance necessitates pre-training on large-scale datasets. Furthermore, the growing layers and parameters in both ViT and convolutional neural networks (CNNs) impede their applicability to mobile multimedia services, primarily owing to the constrained computational resources on edge devices. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT). Specifically, a novel image-level feature embedding allows ViT to better leverage the inductive bias inherent in the convolutional layers. Based on this, an innovative horizontally scalable architecture is designed, which reduces the number of layers and parameters of the models while facilitating collaborative training and inference of ViT models across multiple nodes. The experimental results depict that, without pre-training on large-scale datasets, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes, ascertaining its superior preservation of inductive bias. The code is available at https://github.com/xuchenhao001/HSViT.
Current and future roles of artificial intelligence in retinopathy of prematurity
Feb 15, 2024


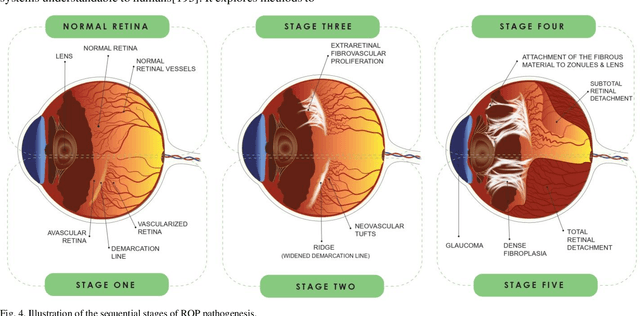
Retinopathy of prematurity (ROP) is a severe condition affecting premature infants, leading to abnormal retinal blood vessel growth, retinal detachment, and potential blindness. While semi-automated systems have been used in the past to diagnose ROP-related plus disease by quantifying retinal vessel features, traditional machine learning (ML) models face challenges like accuracy and overfitting. Recent advancements in deep learning (DL), especially convolutional neural networks (CNNs), have significantly improved ROP detection and classification. The i-ROP deep learning (i-ROP-DL) system also shows promise in detecting plus disease, offering reliable ROP diagnosis potential. This research comprehensively examines the contemporary progress and challenges associated with using retinal imaging and artificial intelligence (AI) to detect ROP, offering valuable insights that can guide further investigation in this domain. Based on 89 original studies in this field (out of 1487 studies that were comprehensively reviewed), we concluded that traditional methods for ROP diagnosis suffer from subjectivity and manual analysis, leading to inconsistent clinical decisions. AI holds great promise for improving ROP management. This review explores AI's potential in ROP detection, classification, diagnosis, and prognosis.
Deep Learning Techniques for Video Instance Segmentation: A Survey
Oct 19, 2023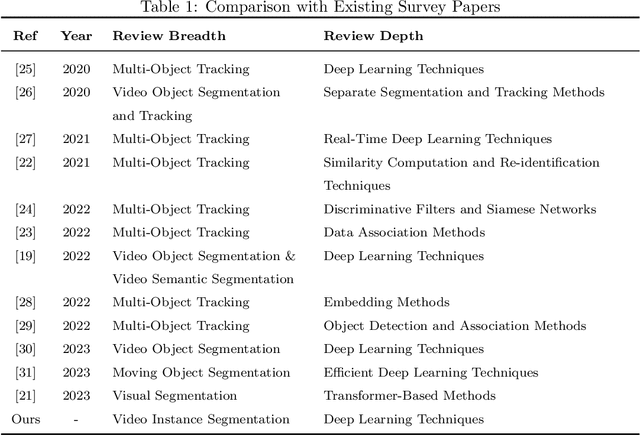


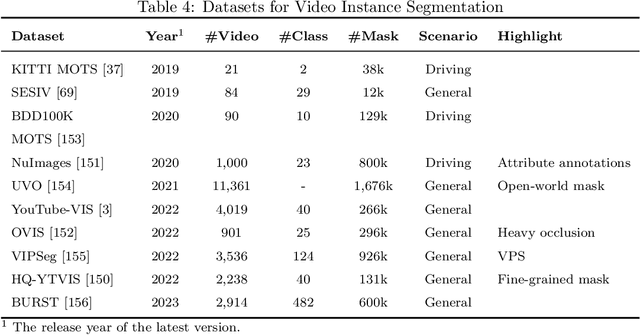
Video instance segmentation, also known as multi-object tracking and segmentation, is an emerging computer vision research area introduced in 2019, aiming at detecting, segmenting, and tracking instances in videos simultaneously. By tackling the video instance segmentation tasks through effective analysis and utilization of visual information in videos, a range of computer vision-enabled applications (e.g., human action recognition, medical image processing, autonomous vehicle navigation, surveillance, etc) can be implemented. As deep-learning techniques take a dominant role in various computer vision areas, a plethora of deep-learning-based video instance segmentation schemes have been proposed. This survey offers a multifaceted view of deep-learning schemes for video instance segmentation, covering various architectural paradigms, along with comparisons of functional performance, model complexity, and computational overheads. In addition to the common architectural designs, auxiliary techniques for improving the performance of deep-learning models for video instance segmentation are compiled and discussed. Finally, we discuss a range of major challenges and directions for further investigations to help advance this promising research field.
Machine Learning Meets Advanced Robotic Manipulation
Sep 22, 2023
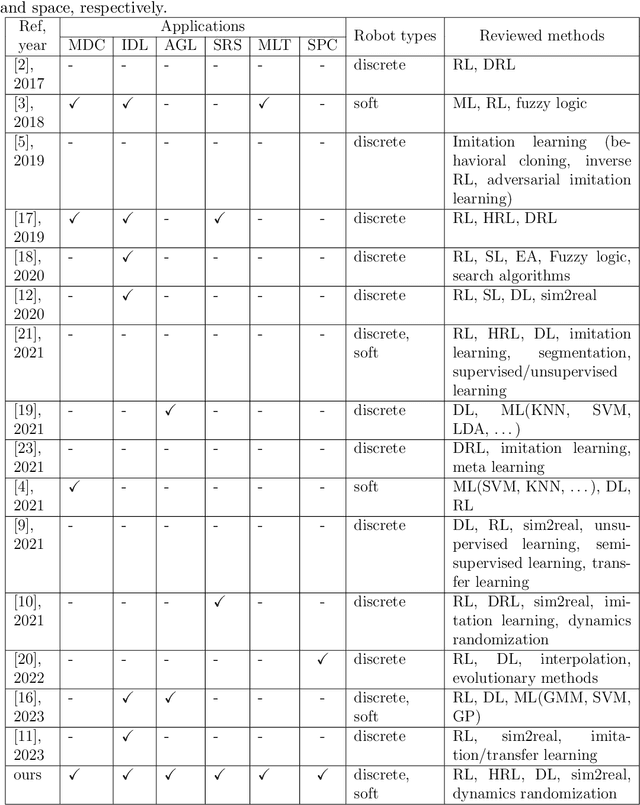
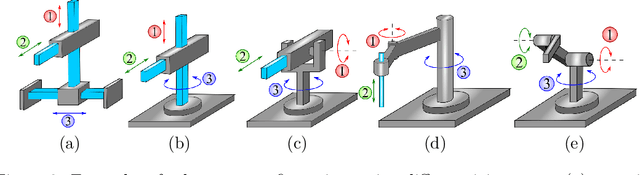
Automated industries lead to high quality production, lower manufacturing cost and better utilization of human resources. Robotic manipulator arms have major role in the automation process. However, for complex manipulation tasks, hard coding efficient and safe trajectories is challenging and time consuming. Machine learning methods have the potential to learn such controllers based on expert demonstrations. Despite promising advances, better approaches must be developed to improve safety, reliability, and efficiency of ML methods in both training and deployment phases. This survey aims to review cutting edge technologies and recent trends on ML methods applied to real-world manipulation tasks. After reviewing the related background on ML, the rest of the paper is devoted to ML applications in different domains such as industry, healthcare, agriculture, space, military, and search and rescue. The paper is closed with important research directions for future works.
An Ensemble Semi-Supervised Adaptive Resonance Theory Model with Explanation Capability for Pattern Classification
May 19, 2023Most semi-supervised learning (SSL) models entail complex structures and iterative training processes as well as face difficulties in interpreting their predictions to users. To address these issues, this paper proposes a new interpretable SSL model using the supervised and unsupervised Adaptive Resonance Theory (ART) family of networks, which is denoted as SSL-ART. Firstly, SSL-ART adopts an unsupervised fuzzy ART network to create a number of prototype nodes using unlabeled samples. Then, it leverages a supervised fuzzy ARTMAP structure to map the established prototype nodes to the target classes using labeled samples. Specifically, a one-to-many (OtM) mapping scheme is devised to associate a prototype node with more than one class label. The main advantages of SSL-ART include the capability of: (i) performing online learning, (ii) reducing the number of redundant prototype nodes through the OtM mapping scheme and minimizing the effects of noisy samples, and (iii) providing an explanation facility for users to interpret the predicted outcomes. In addition, a weighted voting strategy is introduced to form an ensemble SSL-ART model, which is denoted as WESSL-ART. Every ensemble member, i.e., SSL-ART, assigns {\color{black}a different weight} to each class based on its performance pertaining to the corresponding class. The aim is to mitigate the effects of training data sequences on all SSL-ART members and improve the overall performance of WESSL-ART. The experimental results on eighteen benchmark data sets, three artificially generated data sets, and a real-world case study indicate the benefits of the proposed SSL-ART and WESSL-ART models for tackling pattern classification problems.