 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Age Estimation to Age-Invariant Face Recognition: Generalized Age Feature Extraction Using Order-Enhanced Contrastive Learning
Jan 03, 2025



Generalized age feature extraction is crucial for age-related facial analysis tasks, such as age estimation and age-invariant face recognition (AIFR). Despite the recent successes of models in homogeneous-dataset experiments, their performance drops significantly in cross-dataset evaluations. Most of these models fail to extract generalized age features as they only attempt to map extracted features with training age labels directly without explicitly modeling the natural progression of aging. In this paper, we propose Order-Enhanced Contrastive Learning (OrdCon), which aims to extract generalized age features to minimize the domain gap across different datasets and scenarios. OrdCon aligns the direction vector of two features with either the natural aging direction or its reverse to effectively model the aging process. The method also leverages metric learning which is incorporated with a novel soft proxy matching loss to ensure that features are positioned around the center of each age cluster with minimum intra-class variance. We demonstrate that our proposed method achieves comparable results to state-of-the-art methods on various benchmark datasets in homogeneous-dataset evaluations for both age estimation and AIFR. In cross-dataset experiments, our method reduces the mean absolute error by about 1.38 in average for age estimation task and boosts the average accuracy for AIFR by 1.87%.
HSViT: Horizontally Scalable Vision Transformer
Apr 08, 2024



While the Vision Transformer (ViT) architecture gains prominence in computer vision and attracts significant attention from multimedia communities, its deficiency in prior knowledge (inductive bias) regarding shift, scale, and rotational invariance necessitates pre-training on large-scale datasets. Furthermore, the growing layers and parameters in both ViT and convolutional neural networks (CNNs) impede their applicability to mobile multimedia services, primarily owing to the constrained computational resources on edge devices. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT). Specifically, a novel image-level feature embedding allows ViT to better leverage the inductive bias inherent in the convolutional layers. Based on this, an innovative horizontally scalable architecture is designed, which reduces the number of layers and parameters of the models while facilitating collaborative training and inference of ViT models across multiple nodes. The experimental results depict that, without pre-training on large-scale datasets, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes, ascertaining its superior preservation of inductive bias. The code is available at https://github.com/xuchenhao001/HSViT.
Cross-Age Contrastive Learning for Age-Invariant Face Recognition
Jan 02, 2024



Cross-age facial images are typically challenging and expensive to collect, making noise-free age-oriented datasets relatively small compared to widely-used large-scale facial datasets. Additionally, in real scenarios, images of the same subject at different ages are usually hard or even impossible to obtain. Both of these factors lead to a lack of supervised data, which limits the versatility of supervised methods for age-invariant face recognition, a critical task in applications such as security and biometrics. To address this issue, we propose a novel semi-supervised learning approach named Cross-Age Contrastive Learning (CACon). Thanks to the identity-preserving power of recent face synthesis models, CACon introduces a new contrastive learning method that leverages an additional synthesized sample from the input image. We also propose a new loss function in association with CACon to perform contrastive learning on a triplet of samples. We demonstrate that our method not only achieves state-of-the-art performance in homogeneous-dataset experiments on several age-invariant face recognition benchmarks but also outperforms other methods by a large margin in cross-dataset experiments.
Deep Learning Techniques for Video Instance Segmentation: A Survey
Oct 19, 2023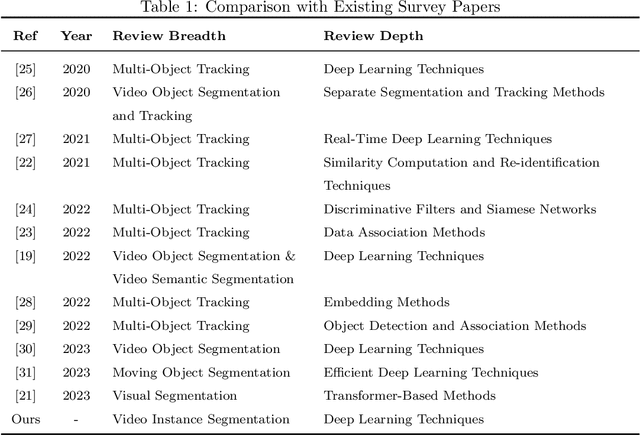


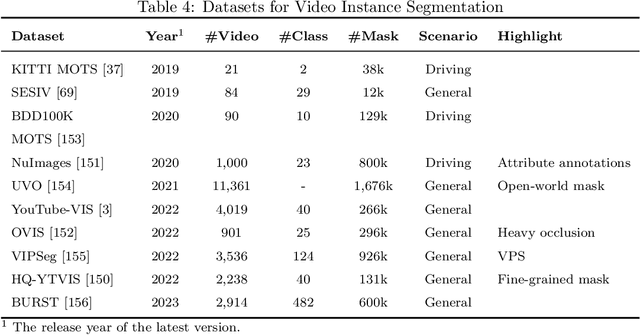
Video instance segmentation, also known as multi-object tracking and segmentation, is an emerging computer vision research area introduced in 2019, aiming at detecting, segmenting, and tracking instances in videos simultaneously. By tackling the video instance segmentation tasks through effective analysis and utilization of visual information in videos, a range of computer vision-enabled applications (e.g., human action recognition, medical image processing, autonomous vehicle navigation, surveillance, etc) can be implemented. As deep-learning techniques take a dominant role in various computer vision areas, a plethora of deep-learning-based video instance segmentation schemes have been proposed. This survey offers a multifaceted view of deep-learning schemes for video instance segmentation, covering various architectural paradigms, along with comparisons of functional performance, model complexity, and computational overheads. In addition to the common architectural designs, auxiliary techniques for improving the performance of deep-learning models for video instance segmentation are compiled and discussed. Finally, we discuss a range of major challenges and directions for further investigations to help advance this promising research field.
Deepfake Detection via Joint Unsupervised Reconstruction and Supervised Classification
Dec 11, 2022


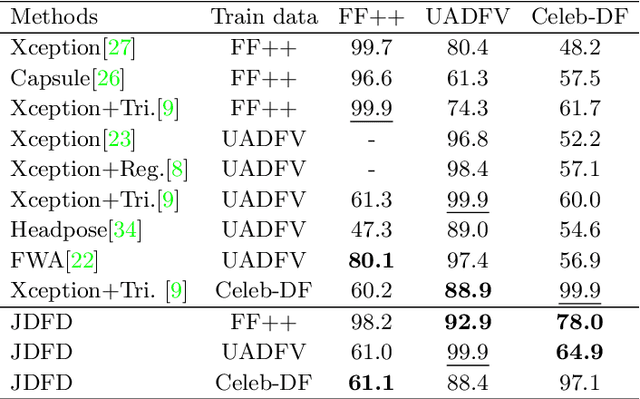
Deep learning has enabled realistic face manipulation (i.e., deepfake), which poses significant concerns over the integrity of the media in circulation. Most existing deep learning techniques for deepfake detection can achieve promising performance in the intra-dataset evaluation setting (i.e., training and testing on the same dataset), but are unable to perform satisfactorily in the inter-dataset evaluation setting (i.e., training on one dataset and testing on another). Most of the previous methods use the backbone network to extract global features for making predictions and only employ binary supervision (i.e., indicating whether the training instances are fake or authentic) to train the network. Classification merely based on the learning of global features leads often leads to weak generalizability to unseen manipulation methods. In addition, the reconstruction task can improve the learned representations. In this paper, we introduce a novel approach for deepfake detection, which considers the reconstruction and classification tasks simultaneously to address these problems. This method shares the information learned by one task with the other, which focuses on a different aspect other existing works rarely consider and hence boosts the overall performance. In particular, we design a two-branch Convolutional AutoEncoder (CAE), in which the Convolutional Encoder used to compress the feature map into the latent representation is shared by both branches. Then the latent representation of the input data is fed to a simple classifier and the unsupervised reconstruction component simultaneously. Our network is trained end-to-end. Experiments demonstrate that our method achieves state-of-the-art performance on three commonly-used datasets, particularly in the cross-dataset evaluation setting.
Self-Supervised Leaf Segmentation under Complex Lighting Conditions
Mar 29, 2022
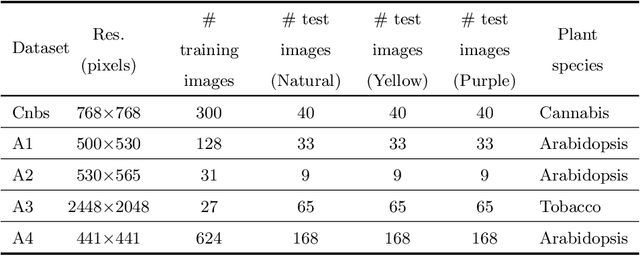
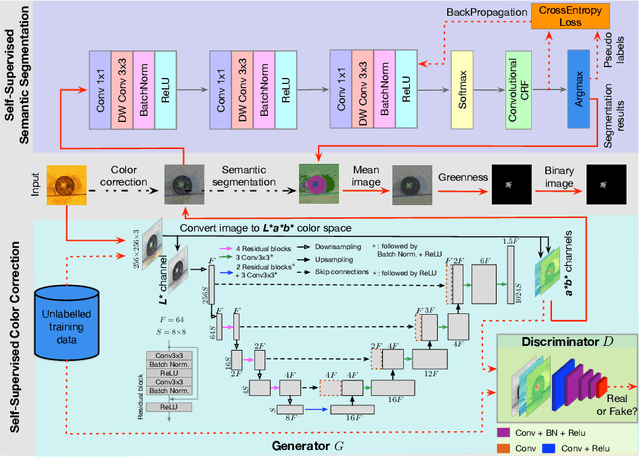

As an essential prerequisite task in image-based plant phenotyping, leaf segmentation has garnered increasing attention in recent years. While self-supervised learning is emerging as an effective alternative to various computer vision tasks, its adaptation for image-based plant phenotyping remains rather unexplored. In this work, we present a self-supervised leaf segmentation framework consisting of a self-supervised semantic segmentation model, a color-based leaf segmentation algorithm, and a self-supervised color correction model. The self-supervised semantic segmentation model groups the semantically similar pixels by iteratively referring to the self-contained information, allowing the pixels of the same semantic object to be jointly considered by the color-based leaf segmentation algorithm for identifying the leaf regions. Additionally, we propose to use a self-supervised color correction model for images taken under complex illumination conditions. Experimental results on datasets of different plant species demonstrate the potential of the proposed self-supervised framework in achieving effective and generalizable leaf segmentation.
Improving Face-Based Age Estimation with Attention-Based Dynamic Patch Fusion
Dec 19, 2021


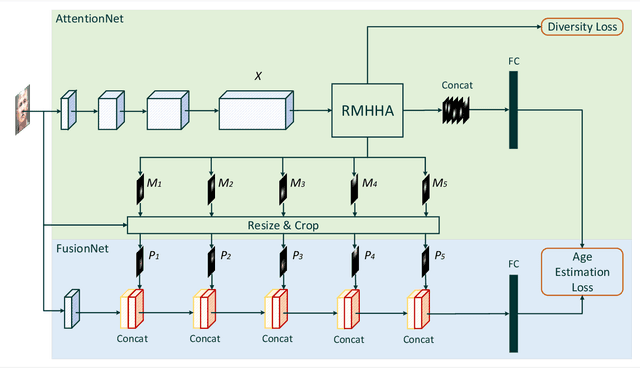
With the increasing popularity of convolutional neural networks (CNNs), recent works on face-based age estimation employ these networks as the backbone. However, state-of-the-art CNN-based methods treat each facial region equally, thus entirely ignoring the importance of some facial patches that may contain rich age-specific information. In this paper, we propose a face-based age estimation framework, called Attention-based Dynamic Patch Fusion (ADPF). In ADPF, two separate CNNs are implemented, namely the AttentionNet and the FusionNet. The AttentionNet dynamically locates and ranks age-specific patches by employing a novel Ranking-guided Multi-Head Hybrid Attention (RMHHA) mechanism. The FusionNet uses the discovered patches along with the facial image to predict the age of the subject. Since the proposed RMHHA mechanism ranks the discovered patches based on their importance, the length of the learning path of each patch in the FusionNet is proportional to the amount of information it carries (the longer, the more important). ADPF also introduces a novel diversity loss to guide the training of the AttentionNet and reduce the overlap among patches so that the diverse and important patches are discovered. Through extensive experiments, we show that our proposed framework outperforms state-of-the-art methods on several age estimation benchmark datasets.
Beyond PRNU: Learning Robust Device-Specific Fingerprint for Source Camera Identification
Nov 03, 2021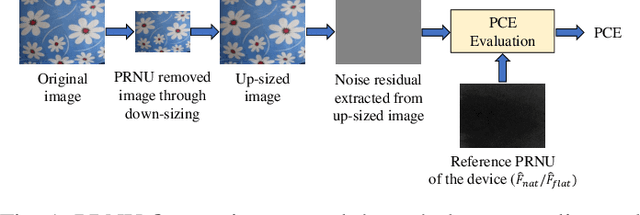
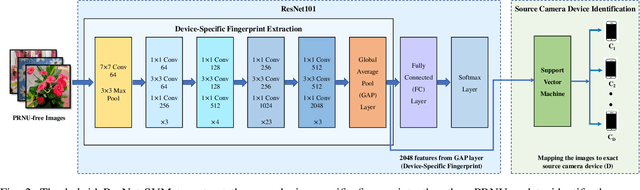
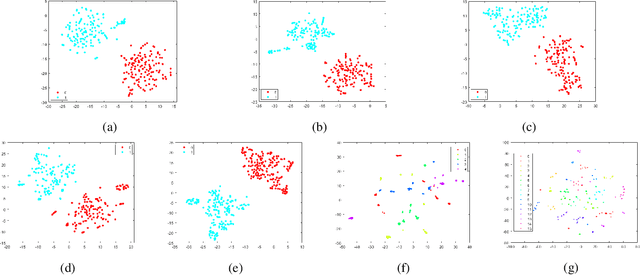
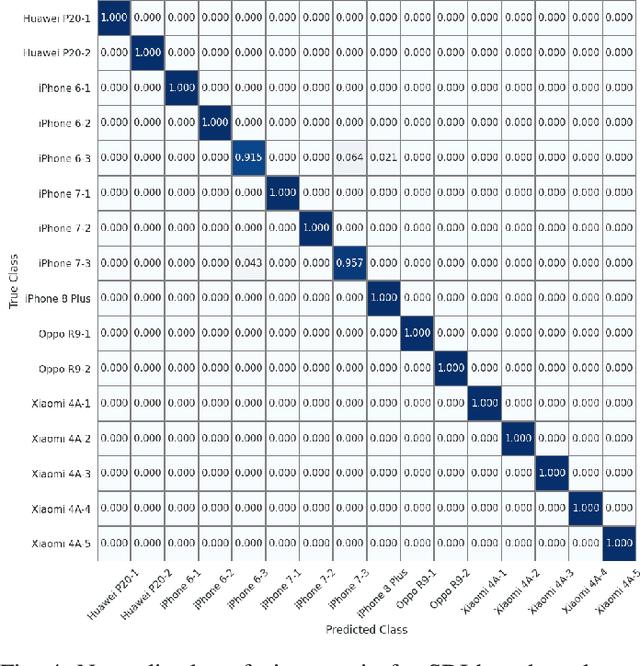
Source camera identification tools assist image forensic investigators to associate an image in question with a suspect camera. Various techniques have been developed based on the analysis of the subtle traces left in the images during the acquisition. The Photo Response Non Uniformity (PRNU) noise pattern caused by sensor imperfections has been proven to be an effective way to identify the source camera. The existing literature suggests that the PRNU is the only fingerprint that is device-specific and capable of identifying the exact source device. However, the PRNU is susceptible to camera settings, image content, image processing operations, and counter-forensic attacks. A forensic investigator unaware of counter-forensic attacks or incidental image manipulations is at the risk of getting misled. The spatial synchronization requirement during the matching of two PRNUs also represents a major limitation of the PRNU. In recent years, deep learning based approaches have been successful in identifying source camera models. However, the identification of individual cameras of the same model through these data-driven approaches remains unsatisfactory. In this paper, we bring to light the existence of a new robust data-driven device-specific fingerprint in digital images which is capable of identifying the individual cameras of the same model. It is discovered that the new device fingerprint is location-independent, stochastic, and globally available, which resolve the spatial synchronization issue. Unlike the PRNU, which resides in the high-frequency band, the new device fingerprint is extracted from the low and mid-frequency bands, which resolves the fragility issue that the PRNU is unable to contend with. Our experiments on various datasets demonstrate that the new fingerprint is highly resilient to image manipulations such as rotation, gamma correction, and aggressive JPEG compression.
On the detection-to-track association for online multi-object tracking
Jul 01, 2021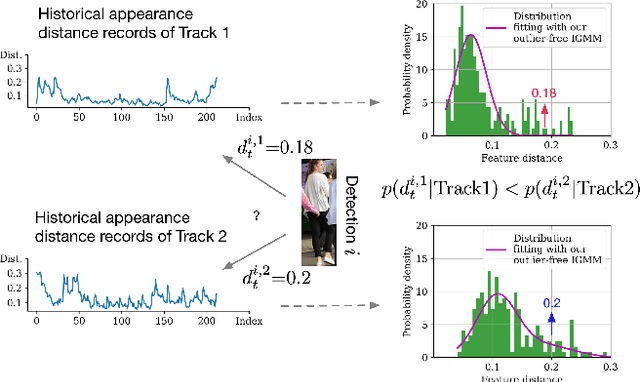

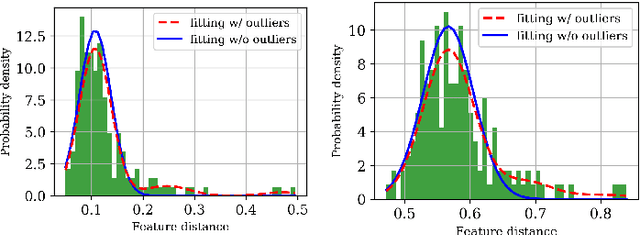
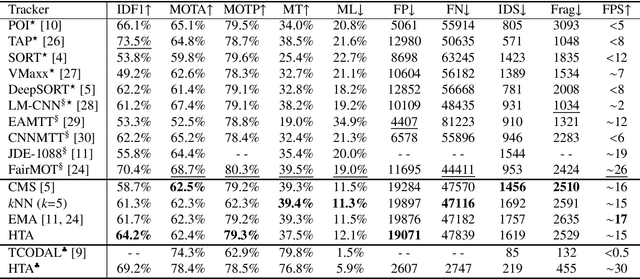
Driven by recent advances in object detection with deep neural networks, the tracking-by-detection paradigm has gained increasing prevalence in the research community of multi-object tracking (MOT). It has long been known that appearance information plays an essential role in the detection-to-track association, which lies at the core of the tracking-by-detection paradigm. While most existing works consider the appearance distances between the detections and the tracks, they ignore the statistical information implied by the historical appearance distance records in the tracks, which can be particularly useful when a detection has similar distances with two or more tracks. In this work, we propose a hybrid track association (HTA) algorithm that models the historical appearance distances of a track with an incremental Gaussian mixture model (IGMM) and incorporates the derived statistical information into the calculation of the detection-to-track association cost. Experimental results on three MOT benchmarks confirm that HTA effectively improves the target identification performance with a small compromise to the tracking speed. Additionally, compared to many state-of-the-art trackers, the DeepSORT tracker equipped with HTA achieves better or comparable performance in terms of the balance of tracking quality and speed.
Deep Learning for Reversible Steganography: Principles and Insights
Jun 13, 2021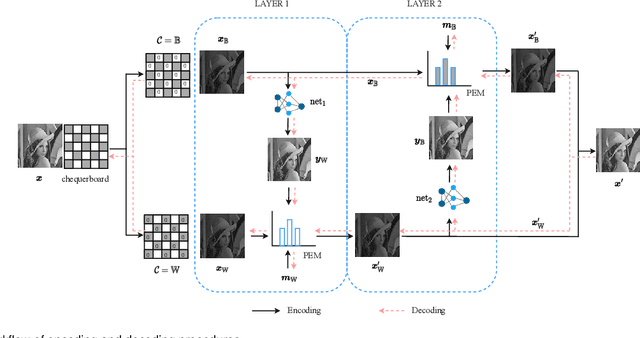


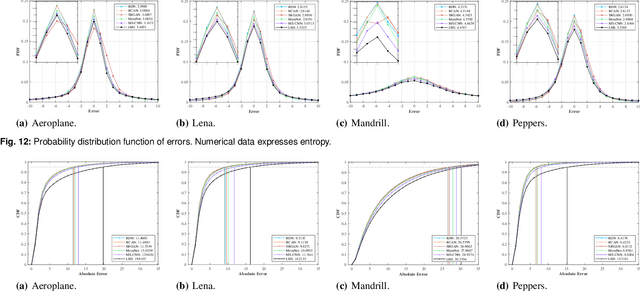
Deep-learning\textendash{centric} reversible steganography has emerged as a promising research paradigm. A direct way of applying deep learning to reversible steganography is to construct a pair of encoder and decoder, whose parameters are trained jointly, thereby learning the steganographic system as a whole. This end-to-end framework, however, falls short of the reversibility requirement because it is difficult for this kind of monolithic system, as a black box, to create or duplicate intricate reversible mechanisms. In response to this issue, a recent approach is to carve up the steganographic system and work on modules independently. In particular, neural networks are deployed in an analytics module to learn the data distribution, while an established mechanism is called upon to handle the remaining tasks. In this paper, we investigate the modular framework and deploy deep neural networks in a reversible steganographic scheme referred to as prediction-error modulation, in which an analytics module serves the purpose of pixel intensity prediction. The primary focus of this study is on deep-learning\textendash{based} context-aware pixel intensity prediction. We address the unsolved issues reported in related literature, including the impact of pixel initialisation on prediction accuracy and the influence of uncertainty propagation in dual-layer embedding. Furthermore, we establish a connection between context-aware pixel intensity prediction and low-level computer vision and analyse the performance of several advanced neural networks.