 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCell Behavior Video Classification Challenge, a benchmark for computer vision methods in time-lapse microscopy
Jan 15, 2026The classification of microscopy videos capturing complex cellular behaviors is crucial for understanding and quantifying the dynamics of biological processes over time. However, it remains a frontier in computer vision, requiring approaches that effectively model the shape and motion of objects without rigid boundaries, extract hierarchical spatiotemporal features from entire image sequences rather than static frames, and account for multiple objects within the field of view. To this end, we organized the Cell Behavior Video Classification Challenge (CBVCC), benchmarking 35 methods based on three approaches: classification of tracking-derived features, end-to-end deep learning architectures to directly learn spatiotemporal features from the entire video sequence without explicit cell tracking, or ensembling tracking-derived with image-derived features. We discuss the results achieved by the participants and compare the potential and limitations of each approach, serving as a basis to foster the development of computer vision methods for studying cellular dynamics.
Self-Supervised Leaf Segmentation under Complex Lighting Conditions
Mar 29, 2022
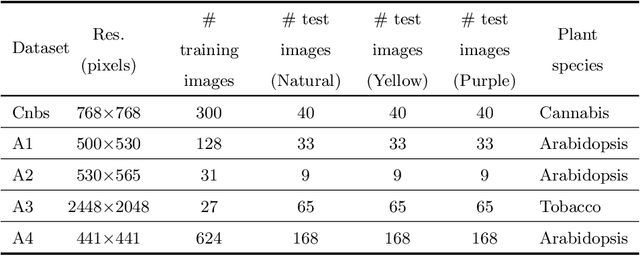
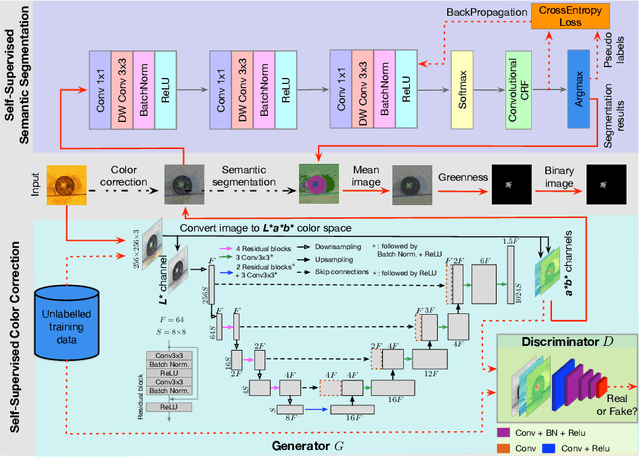

As an essential prerequisite task in image-based plant phenotyping, leaf segmentation has garnered increasing attention in recent years. While self-supervised learning is emerging as an effective alternative to various computer vision tasks, its adaptation for image-based plant phenotyping remains rather unexplored. In this work, we present a self-supervised leaf segmentation framework consisting of a self-supervised semantic segmentation model, a color-based leaf segmentation algorithm, and a self-supervised color correction model. The self-supervised semantic segmentation model groups the semantically similar pixels by iteratively referring to the self-contained information, allowing the pixels of the same semantic object to be jointly considered by the color-based leaf segmentation algorithm for identifying the leaf regions. Additionally, we propose to use a self-supervised color correction model for images taken under complex illumination conditions. Experimental results on datasets of different plant species demonstrate the potential of the proposed self-supervised framework in achieving effective and generalizable leaf segmentation.
Beyond PRNU: Learning Robust Device-Specific Fingerprint for Source Camera Identification
Nov 03, 2021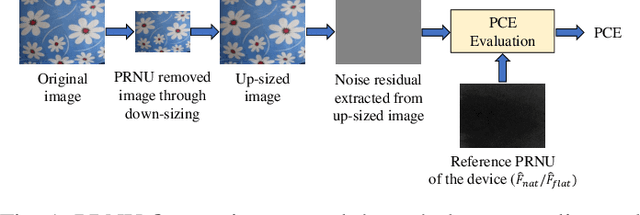
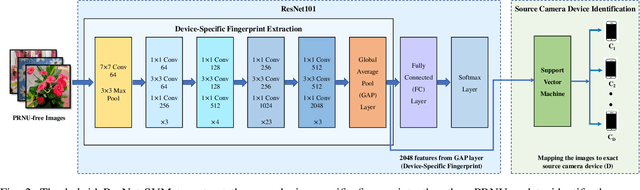
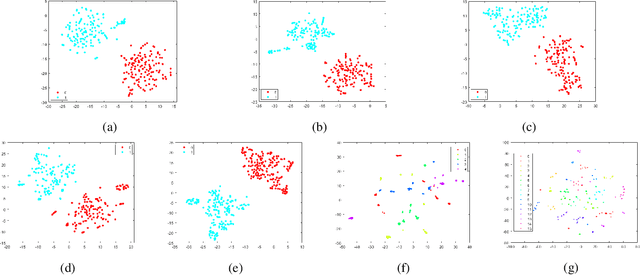
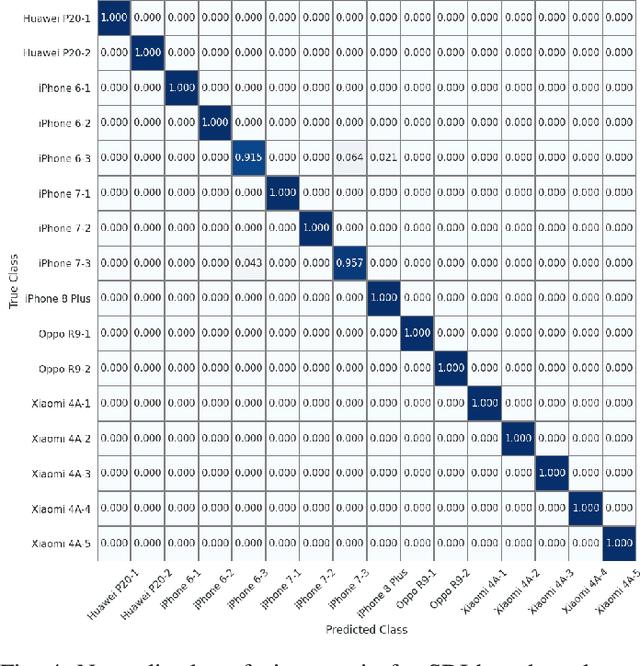
Source camera identification tools assist image forensic investigators to associate an image in question with a suspect camera. Various techniques have been developed based on the analysis of the subtle traces left in the images during the acquisition. The Photo Response Non Uniformity (PRNU) noise pattern caused by sensor imperfections has been proven to be an effective way to identify the source camera. The existing literature suggests that the PRNU is the only fingerprint that is device-specific and capable of identifying the exact source device. However, the PRNU is susceptible to camera settings, image content, image processing operations, and counter-forensic attacks. A forensic investigator unaware of counter-forensic attacks or incidental image manipulations is at the risk of getting misled. The spatial synchronization requirement during the matching of two PRNUs also represents a major limitation of the PRNU. In recent years, deep learning based approaches have been successful in identifying source camera models. However, the identification of individual cameras of the same model through these data-driven approaches remains unsatisfactory. In this paper, we bring to light the existence of a new robust data-driven device-specific fingerprint in digital images which is capable of identifying the individual cameras of the same model. It is discovered that the new device fingerprint is location-independent, stochastic, and globally available, which resolve the spatial synchronization issue. Unlike the PRNU, which resides in the high-frequency band, the new device fingerprint is extracted from the low and mid-frequency bands, which resolves the fragility issue that the PRNU is unable to contend with. Our experiments on various datasets demonstrate that the new fingerprint is highly resilient to image manipulations such as rotation, gamma correction, and aggressive JPEG compression.
On the detection-to-track association for online multi-object tracking
Jul 01, 2021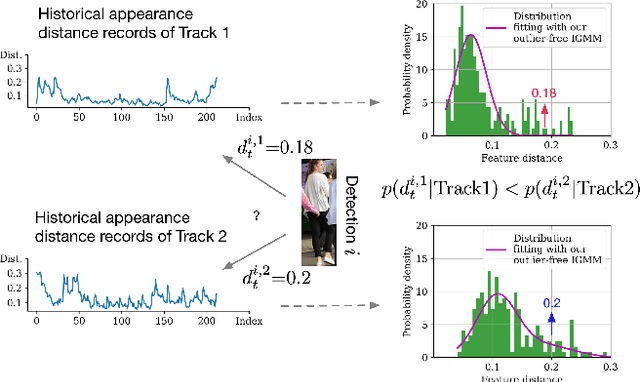

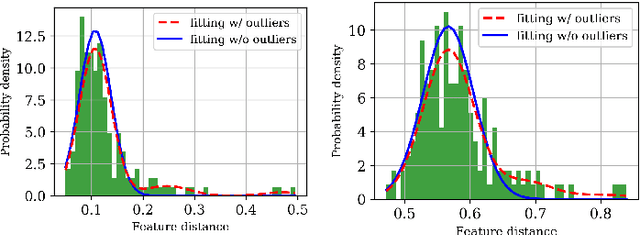
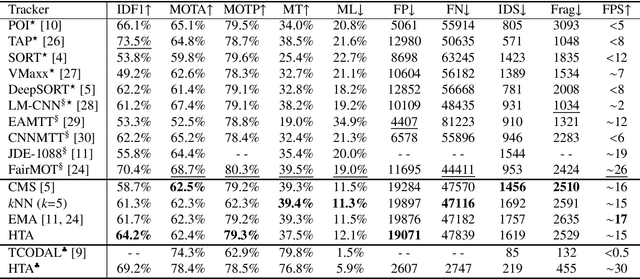
Driven by recent advances in object detection with deep neural networks, the tracking-by-detection paradigm has gained increasing prevalence in the research community of multi-object tracking (MOT). It has long been known that appearance information plays an essential role in the detection-to-track association, which lies at the core of the tracking-by-detection paradigm. While most existing works consider the appearance distances between the detections and the tracks, they ignore the statistical information implied by the historical appearance distance records in the tracks, which can be particularly useful when a detection has similar distances with two or more tracks. In this work, we propose a hybrid track association (HTA) algorithm that models the historical appearance distances of a track with an incremental Gaussian mixture model (IGMM) and incorporates the derived statistical information into the calculation of the detection-to-track association cost. Experimental results on three MOT benchmarks confirm that HTA effectively improves the target identification performance with a small compromise to the tracking speed. Additionally, compared to many state-of-the-art trackers, the DeepSORT tracker equipped with HTA achieves better or comparable performance in terms of the balance of tracking quality and speed.
Deep Detection for Face Manipulation
Sep 13, 2020
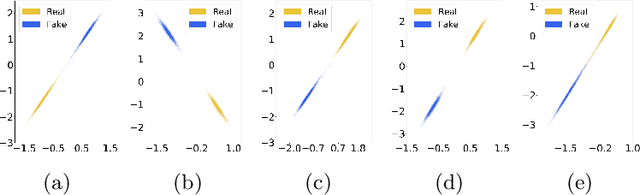


It has become increasingly challenging to distinguish real faces from their visually realistic fake counterparts, due to the great advances of deep learning based face manipulation techniques in recent years. In this paper, we introduce a deep learning method to detect face manipulation. It consists of two stages: feature extraction and binary classification. To better distinguish fake faces from real faces, we resort to the triplet loss function in the first stage. We then design a simple linear classification network to bridge the learned contrastive features with the real/fake faces. Experimental results on public benchmark datasets demonstrate the effectiveness of this method, and show that it generates better performance than state-of-the-art techniques in most cases.