 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRM: Learning the Language of Rotating Machinery for Self-Supervised Condition Monitoring
Apr 07, 2026We present LoRM (Language of Rotating Machinery), a self-supervised framework for multi-modal rotating-machinery signal understanding and real-time condition monitoring. LoRM is built on the idea that rotating-machinery signals can be viewed as a machine language: local signals can be tokenised into discrete symbolic units, and their future evolution can be predicted from observed multi-sensor context. Unlike conventional signal-processing methods that rely on hand-crafted transforms and features, LoRM reformulates multi-modal sensor data as a token-based sequence-prediction problem. For each data window, the observed context segment is retained in continuous form, while the future target segment of each sensing channel is quantised into a discrete token. Then, efficient knowledge transfer is achieved by partially fine-tuning a general-purpose pre-trained language model on industrial signals, avoiding the need to train a large model from scratch. Finally, condition monitoring is performed by tracking token-prediction errors as a health indicator, where increasing errors indicate degradation. In-situ tool condition monitoring (TCM) experiments demonstrate stable real-time tracking and strong cross-tool generalisation, showing that LoRM provides a practical bridge between language modelling and industrial signal analysis. The source code is publicly available at https://github.com/Q159753258/LormPHM.
Lethe:Adapter-Augmented Dual-Stream Update for Persistent Knowledge Erasure in Federated Unlearning
Jan 30, 2026Federated unlearning (FU) aims to erase designated client-level, class-level, or sample-level knowledge from a global model. Existing studies commonly assume that the collaboration ends up with the unlearning operation, overlooking the follow-up situation where the federated training continues over the remaining data.We identify a critical failure mode, termed Knowledge resurfacing, by revealing that continued training can re-activate unlearned knowledge and cause the removed influence to resurface in the global model. To address this, we propose Lethe, a novel federated unlearning method that de-correlates knowledge to be unlearned from knowledge to be retained, ensuring persistent erasure during continued training.Lethe follows a Reshape--Rectify--Restore pipeline: a temporary adapter is first trained with gradient ascent on the unlearning data to obtain magnified updates, which is then used as corrective signals to diverge layer-wise rectification on the remaining updates in two streams. Finally, the adapter is removed and a short recovery stage is performed on the retained data. Our experiments show that Lethe supports unlearning in the federated system at all levels in a unified manner and maintains superior persistence (Resurfacing Rate <1% in most cases) even after numerous rounds of follow-up training.
PSNet: Fast Data Structuring for Hierarchical Deep Learning on Point Cloud
May 31, 2022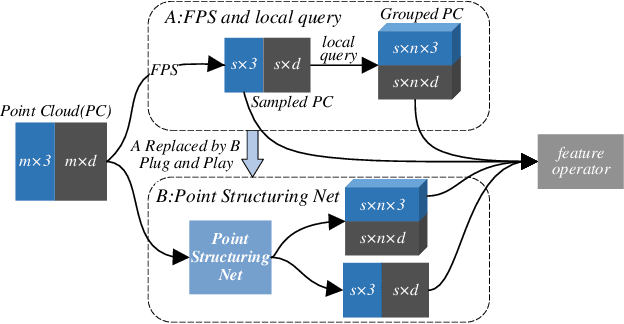
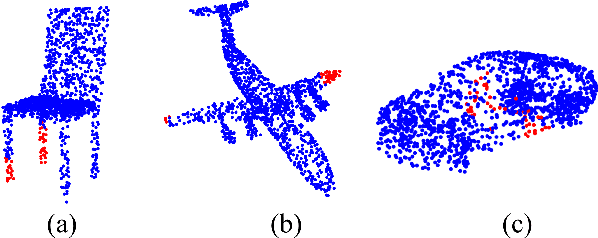
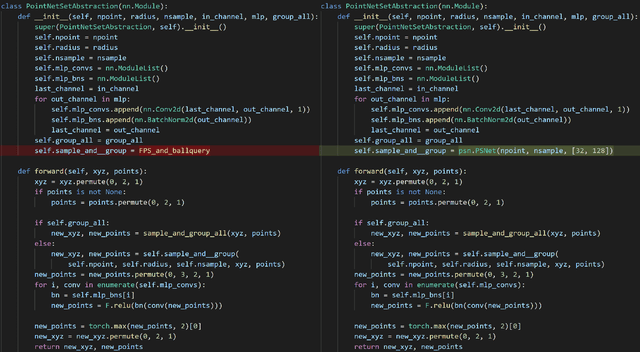
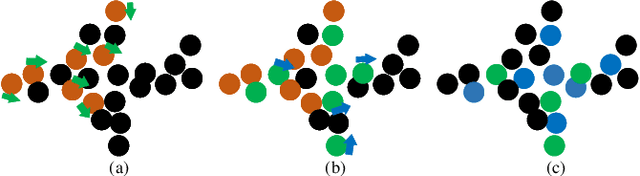
In order to retain more feature information of local areas on a point cloud, local grouping and subsampling are the necessary data structuring steps in most hierarchical deep learning models. Due to the disorder nature of the points in a point cloud, the significant time cost may be consumed when grouping and subsampling the points, which consequently results in poor scalability. This paper proposes a fast data structuring method called PSNet (Point Structuring Net). PSNet transforms the spatial features of the points and matches them to the features of local areas in a point cloud. PSNet achieves grouping and sampling at the same time while the existing methods process sampling and grouping in two separate steps (such as using FPS plus kNN). PSNet performs feature transformation pointwise while the existing methods uses the spatial relationship among the points as the reference for grouping. Thanks to these features, PSNet has two important advantages: 1) the grouping and sampling results obtained by PSNet is stable and permutation invariant; and 2) PSNet can be easily parallelized. PSNet can replace the data structuring methods in the mainstream point cloud deep learning models in a plug-and-play manner. We have conducted extensive experiments. The results show that PSNet can improve the training and inference speed significantly while maintaining the model accuracy.
Self-Supervised Leaf Segmentation under Complex Lighting Conditions
Mar 29, 2022
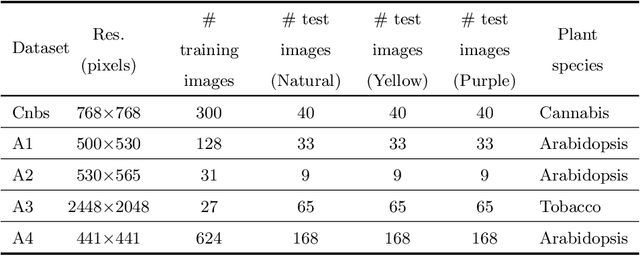
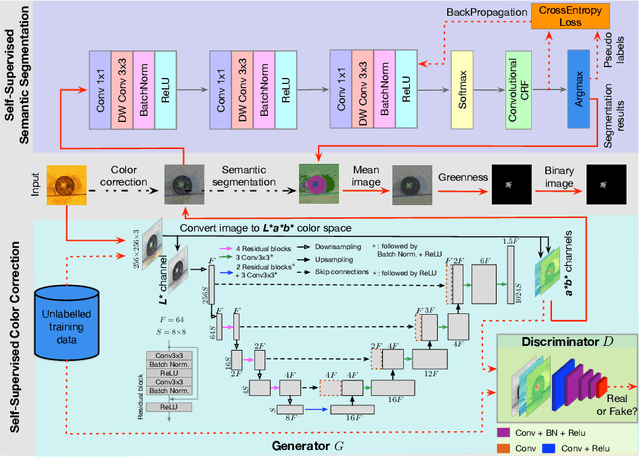

As an essential prerequisite task in image-based plant phenotyping, leaf segmentation has garnered increasing attention in recent years. While self-supervised learning is emerging as an effective alternative to various computer vision tasks, its adaptation for image-based plant phenotyping remains rather unexplored. In this work, we present a self-supervised leaf segmentation framework consisting of a self-supervised semantic segmentation model, a color-based leaf segmentation algorithm, and a self-supervised color correction model. The self-supervised semantic segmentation model groups the semantically similar pixels by iteratively referring to the self-contained information, allowing the pixels of the same semantic object to be jointly considered by the color-based leaf segmentation algorithm for identifying the leaf regions. Additionally, we propose to use a self-supervised color correction model for images taken under complex illumination conditions. Experimental results on datasets of different plant species demonstrate the potential of the proposed self-supervised framework in achieving effective and generalizable leaf segmentation.
Variation-Incentive Loss Re-weighting for Regression Analysis on Biased Data
Sep 14, 2021
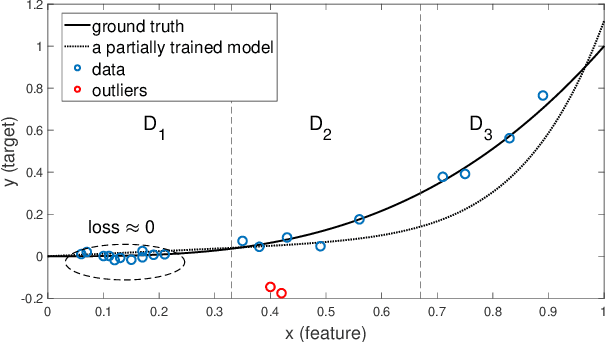
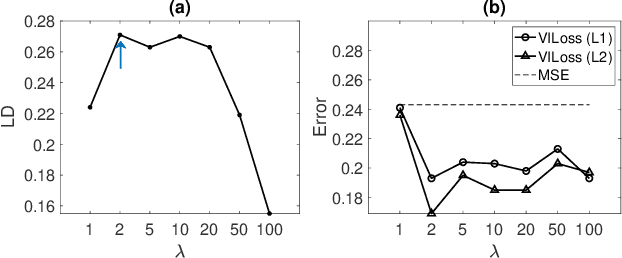
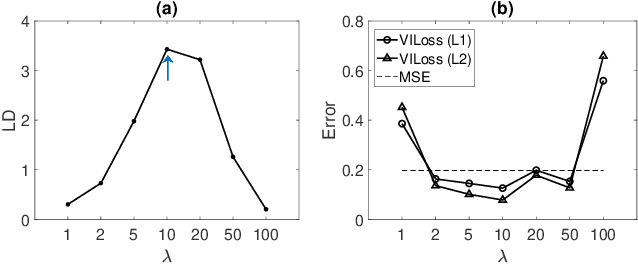
Both classification and regression tasks are susceptible to the biased distribution of training data. However, existing approaches are focused on the class-imbalanced learning and cannot be applied to the problems of numerical regression where the learning targets are continuous values rather than discrete labels. In this paper, we aim to improve the accuracy of the regression analysis by addressing the data skewness/bias during model training. We first introduce two metrics, uniqueness and abnormality, to reflect the localized data distribution from the perspectives of their feature (i.e., input) space and target (i.e., output) space. Combining these two metrics we propose a Variation-Incentive Loss re-weighting method (VILoss) to optimize the gradient descent-based model training for regression analysis. We have conducted comprehensive experiments on both synthetic and real-world data sets. The results show significant improvement in the model quality (reduction in error by up to 11.9%) when using VILoss as the loss criterion in training.
FedProf: Optimizing Federated Learning with Dynamic Data Profiling
Feb 02, 2021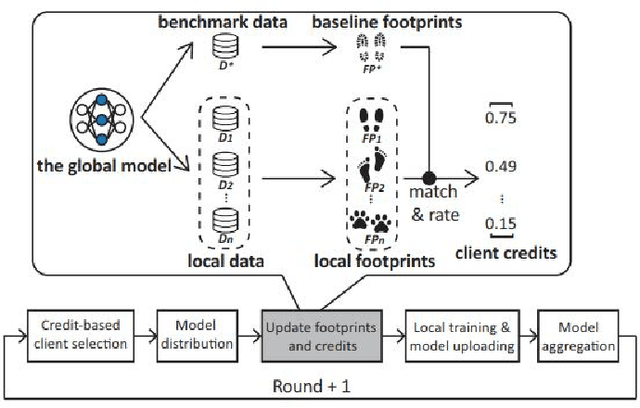
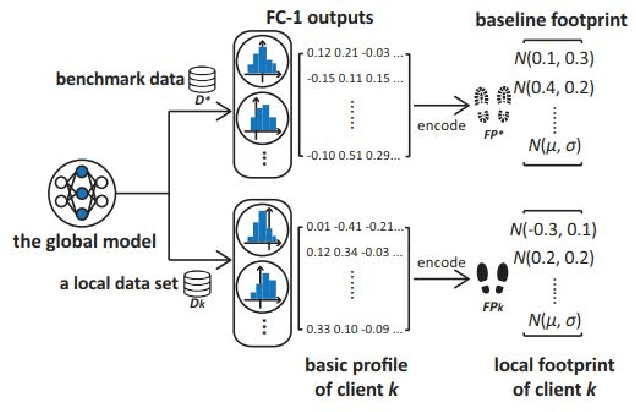
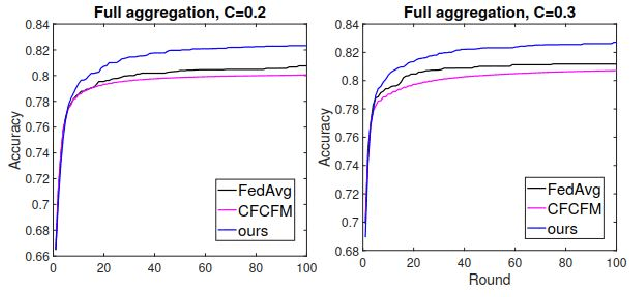
Federated Learning (FL) has shown great potential as a privacy-preserving solution to learning from decentralized data which are only accessible locally on end devices (i.e., clients). In many scenarios, however, a large proportion of the clients are probably in possession of only low-quality data that are biased, noisy or even irrelevant. As a result, they could significantly degrade the quality of the global model we aim to build and slow down its convergence in the course of FL. In light of this, we propose a novel approach to optimizing FL under such circumstances without breaching data privacy. The key of our approach is a dynamic data profiling method for generating model-data footprints on each client and the server. The footprint encodes the representation of the global model on the corresponding data partition based on the output distribution of the model's first fully-connected layer (FC-1). By matching the footprints from clients and the server, we adaptively adjust each client's opportunity of participation in each FL round to mitigate the impact from the clients with low-quality data. We have conducted extensive experiments on public data sets using various FL settings. Results show that our method significantly reduces the number of rounds (by up to 75\%) and overall time (by up to 68\%) required to have the global model converge whiling increasing the global model's accuracy by up to 2.5\%.
An Efficiency-boosting Client Selection Scheme for Federated Learning with Fairness Guarantee
Nov 04, 2020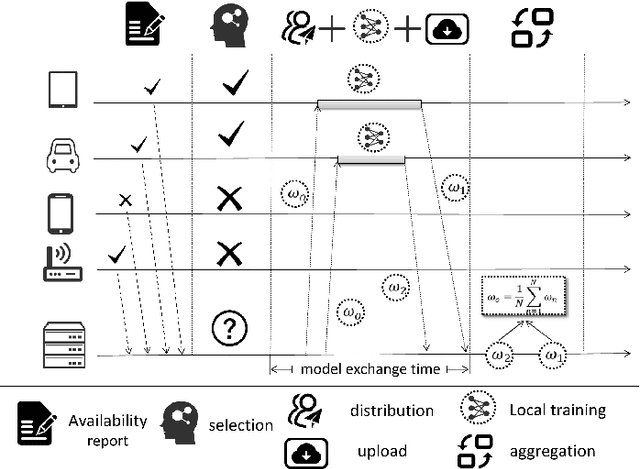


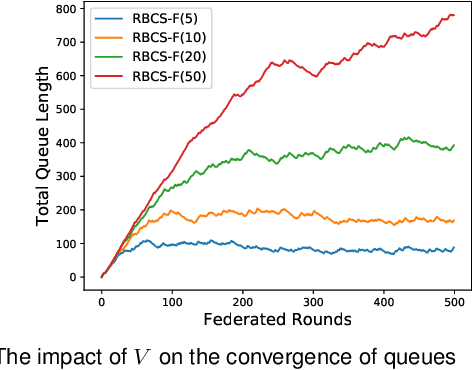
The issue of potential privacy leakage during centralized AI's model training has drawn intensive concern from the public. A Parallel and Distributed Computing (or PDC) scheme, termed Federated Learning (FL), has emerged as a new paradigm to cope with the privacy issue by allowing clients to perform model training locally, without the necessity to upload their personal sensitive data. In FL, the number of clients could be sufficiently large, but the bandwidth available for model distribution and re-upload is quite limited, making it sensible to only involve part of the volunteers to participate in the training process. The client selection policy is critical to an FL process in terms of training efficiency, the final model's quality as well as fairness. In this paper, we will model the fairness guaranteed client selection as a Lyapunov optimization problem and then a C2MAB-based method is proposed for estimation of the model exchange time between each client and the server, based on which we design a fairness guaranteed algorithm termed RBCS-F for problem-solving. The regret of RBCS-F is strictly bounded by a finite constant, justifying its theoretical feasibility. Barring the theoretical results, more empirical data can be derived from our real training experiments on public datasets.
Accelerating Federated Learning over Reliability-Agnostic Clients in Mobile Edge Computing Systems
Jul 28, 2020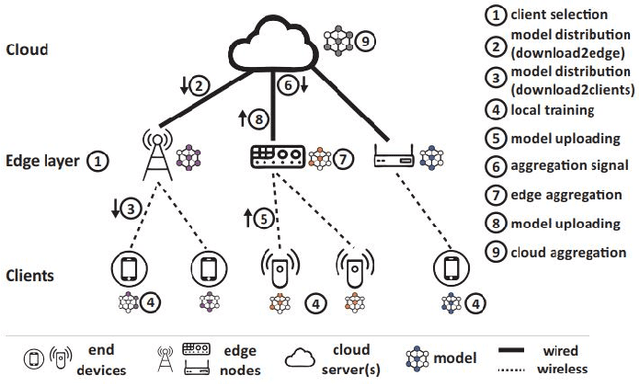
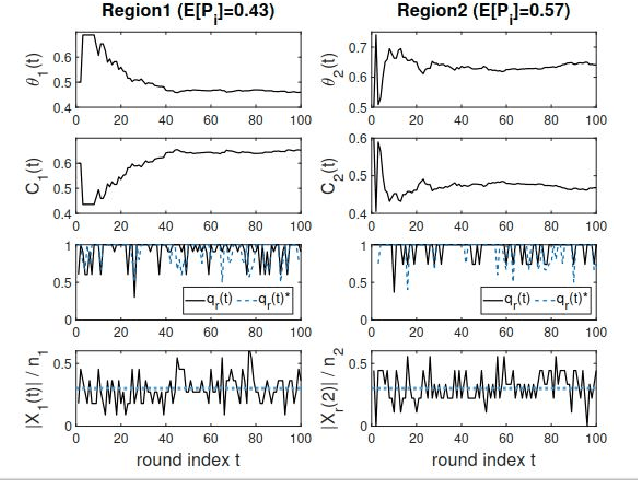
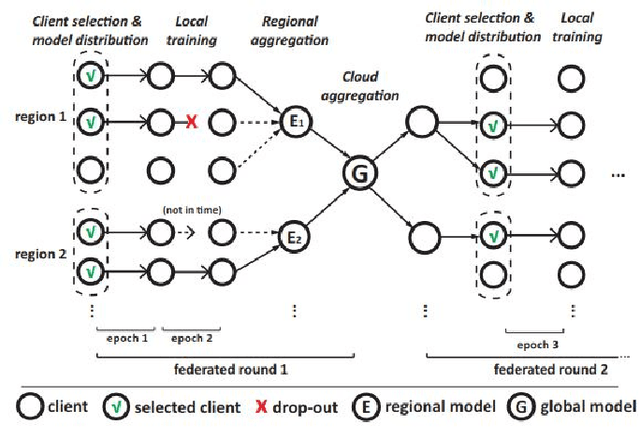
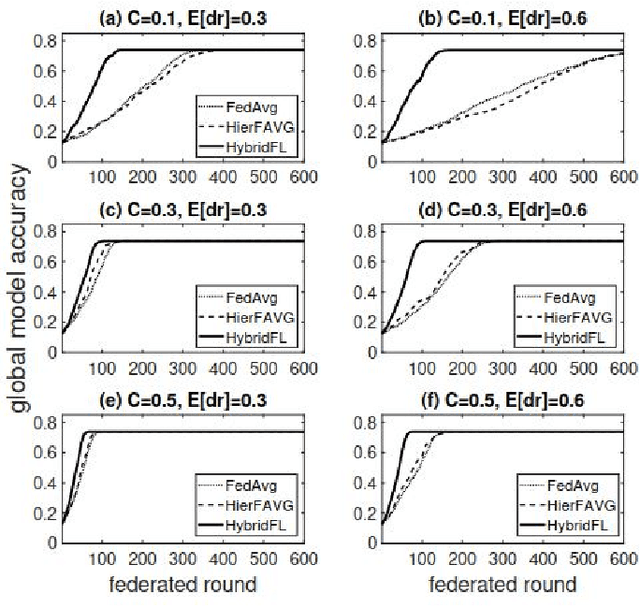
Mobile Edge Computing (MEC), which incorporates the Cloud, edge nodes and end devices, has shown great potential in bringing data processing closer to the data sources. Meanwhile, Federated learning (FL) has emerged as a promising privacy-preserving approach to facilitating AI applications. However, it remains a big challenge to optimize the efficiency and effectiveness of FL when it is integrated with the MEC architecture. Moreover, the unreliable nature (e.g., stragglers and intermittent drop-out) of end devices significantly slows down the FL process and affects the global model's quality in such circumstances. In this paper, a multi-layer federated learning protocol called HybridFL is designed for the MEC architecture. HybridFL adopts two levels (the edge level and the cloud level) of model aggregation enacting different aggregation strategies. Moreover, in order to mitigate stragglers and end device drop-out, we introduce regional slack factors into the stage of client selection performed at the edge nodes using a probabilistic approach without identifying or probing the state of end devices (whose reliability is agnostic). We demonstrate the effectiveness of our method in modulating the proportion of clients selected and present the convergence analysis for our protocol. We have conducted extensive experiments with machine learning tasks in different scales of MEC system. The results show that HybridFL improves the FL training process significantly in terms of shortening the federated round length, speeding up the global model's convergence (by up to 12X) and reducing end device energy consumption (by up to 58%)
SAFA: a Semi-Asynchronous Protocol for Fast Federated Learning with Low Overhead
Oct 03, 2019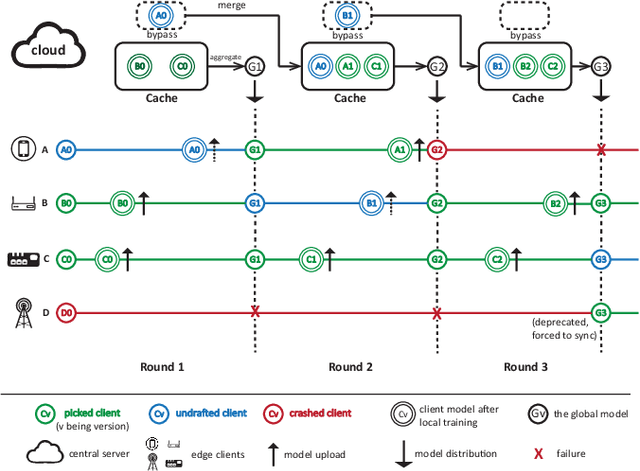
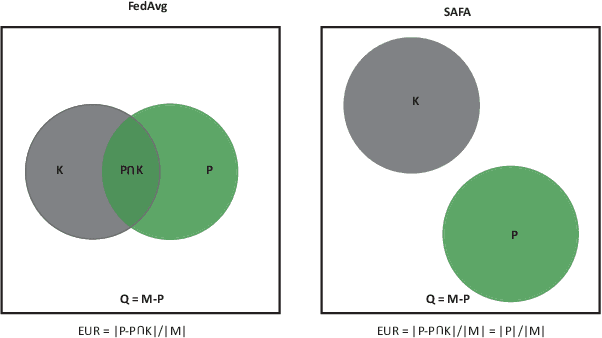
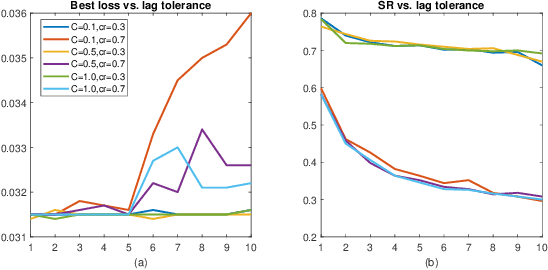
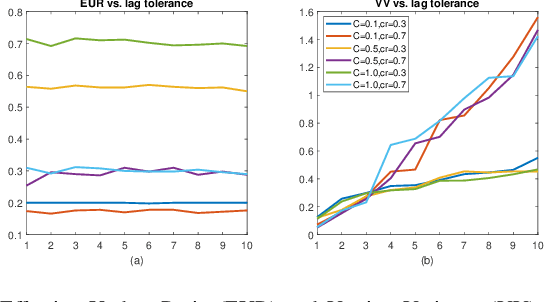
Federated learning (FL) has attracted increasing attention as a promising approach to driving a vast number of devices at the edge with artificial intelligence, i.e., Edge Intelligence. However, it is very challenging to guarantee the efficiency of FL considering the unreliable nature of edge devices while the cost of edge-server communication cannot be neglected. In this paper, we propose SAFA, a semi-asynchronous protocol that avoids problems in the pure synchronous/asynchronous approaches such as heavy downlink traffic and poor convergence rate in extreme conditions (e.g., clients dropping offline frequently). Key principles are introduced in model distribution, client selection and global aggregation, which are designed with tolerance to stragglers for efficiency boost and bias reduction. Extensive experiments on typical machine learning tasks show the effectiveness of the proposed protocol in shortening federated round duration, reducing local resource wastage, and improving the global model's accuracy at a low communication cost.
Local Trend Inconsistency: A Prediction-driven Approach to Unsupervised Anomaly Detection in Multi-seasonal Time Series
Aug 03, 2019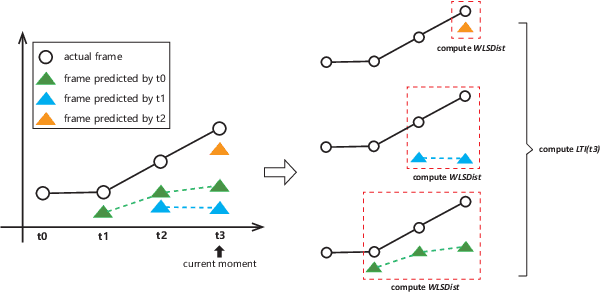
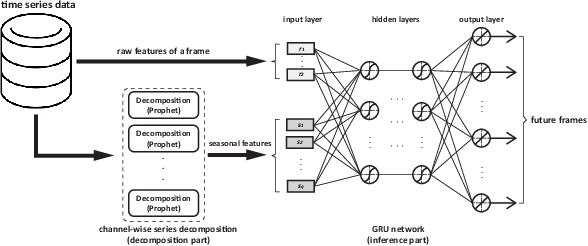
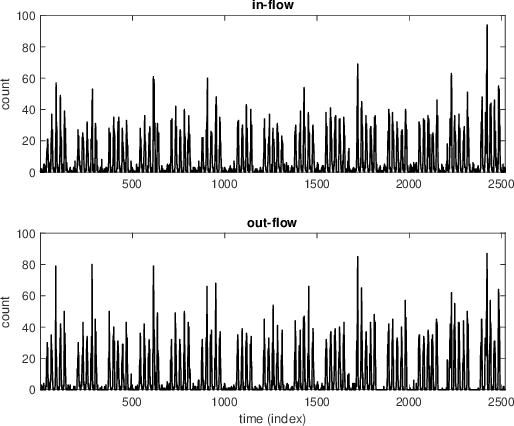
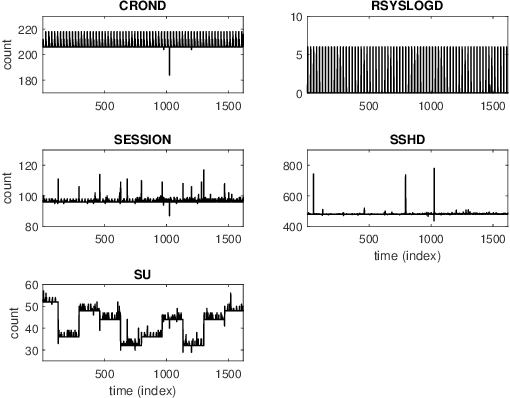
On-line detection of anomalies in time series is a key technique in various event-sensitive scenarios such as robotic system monitoring, smart sensor networks and data center security. However, the increasing diversity of data sources and demands are making this task more challenging than ever. First, the rapid increase of unlabeled data makes supervised learning no longer suitable in many cases. Second, a great portion of time series have complex seasonality features. Third, on-line anomaly detection needs to be fast and reliable. In view of this, we in this paper adopt an unsupervised prediction-driven approach on the basis of a backbone model combining a series decomposition part and an inference part. We then propose a novel metric, Local Trend Inconsistency (LTI), along with a detection algorithm that efficiently computes LTI chronologically along the series and marks each data point with a score indicating its probability of being anomalous. We experimentally evaluated our algorithm on datasets from UCI public repository and a production environment. The result shows that our scheme outperforms several representative anomaly detection algorithms in Area Under Curve (AUC) metric with decent time efficiency.