 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedProf: Optimizing Federated Learning with Dynamic Data Profiling
Paper and Code
Feb 02, 2021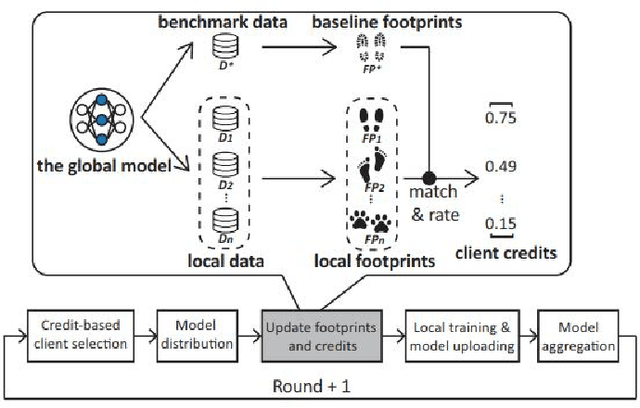
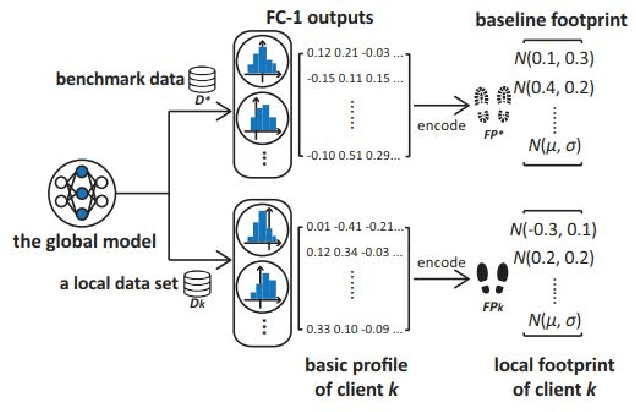
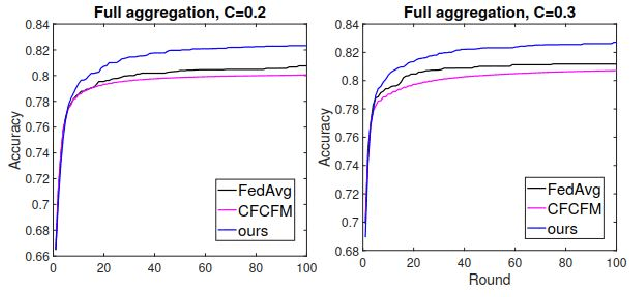
Federated Learning (FL) has shown great potential as a privacy-preserving solution to learning from decentralized data which are only accessible locally on end devices (i.e., clients). In many scenarios, however, a large proportion of the clients are probably in possession of only low-quality data that are biased, noisy or even irrelevant. As a result, they could significantly degrade the quality of the global model we aim to build and slow down its convergence in the course of FL. In light of this, we propose a novel approach to optimizing FL under such circumstances without breaching data privacy. The key of our approach is a dynamic data profiling method for generating model-data footprints on each client and the server. The footprint encodes the representation of the global model on the corresponding data partition based on the output distribution of the model's first fully-connected layer (FC-1). By matching the footprints from clients and the server, we adaptively adjust each client's opportunity of participation in each FL round to mitigate the impact from the clients with low-quality data. We have conducted extensive experiments on public data sets using various FL settings. Results show that our method significantly reduces the number of rounds (by up to 75\%) and overall time (by up to 68\%) required to have the global model converge whiling increasing the global model's accuracy by up to 2.5\%.