 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Augmentation in Federation: Rethinking What Collaborative Learning Can Bring Back to Decentralized Data
Mar 05, 2025Data, as an observable form of knowledge, has become one of the most important factors of production for the development of Artificial Intelligence (AI). Meanwhile, increasing legislation and regulations on private and proprietary information results in scattered data sources also known as the ``data islands''. Although some collaborative learning paradigms such as Federated Learning (FL) can enable privacy-preserving training over decentralized data, they have inherent deficiencies in fairness, costs and reproducibility because of being learning-centric, which greatly limits the way how participants cooperate with each other. In light of this, we present a knowledge-centric paradigm termed \emph{Knowledge Augmentation in Federation} (KAF), with focus on how to enhance local knowledge through collaborative effort. We provide the suggested system architecture, formulate the prototypical optimization objective, and review emerging studies that employ methodologies suitable for KAF. On our roadmap, with a three-way categorization we describe the methods for knowledge expansion, knowledge filtering, and label and feature space correction in the federation. Further, we highlight several challenges and open questions that deserve more attention from the community. With our investigation, we intend to offer new insights for what collaborative learning can bring back to decentralized data.
CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Patterns
Sep 27, 2024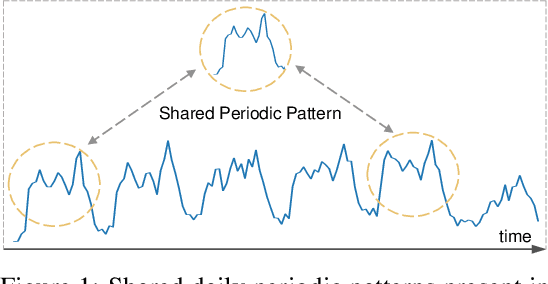
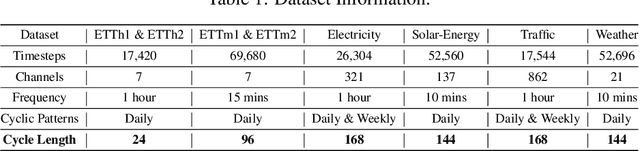
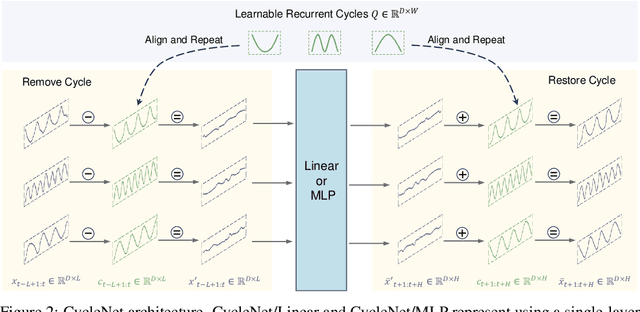
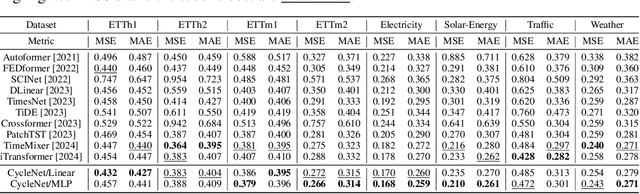
The stable periodic patterns present in time series data serve as the foundation for conducting long-horizon forecasts. In this paper, we pioneer the exploration of explicitly modeling this periodicity to enhance the performance of models in long-term time series forecasting (LTSF) tasks. Specifically, we introduce the Residual Cycle Forecasting (RCF) technique, which utilizes learnable recurrent cycles to model the inherent periodic patterns within sequences, and then performs predictions on the residual components of the modeled cycles. Combining RCF with a Linear layer or a shallow MLP forms the simple yet powerful method proposed in this paper, called CycleNet. CycleNet achieves state-of-the-art prediction accuracy in multiple domains including electricity, weather, and energy, while offering significant efficiency advantages by reducing over 90% of the required parameter quantity. Furthermore, as a novel plug-and-play technique, the RCF can also significantly improve the prediction accuracy of existing models, including PatchTST and iTransformer. The source code is available at: https://github.com/ACAT-SCUT/CycleNet.
SparseTSF: Modeling Long-term Time Series Forecasting with 1k Parameters
May 02, 2024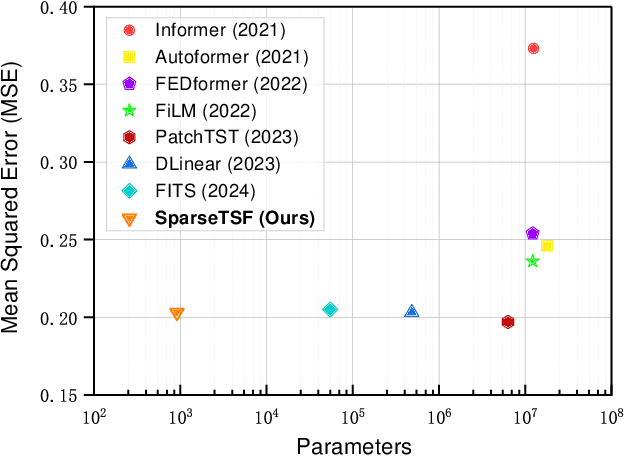

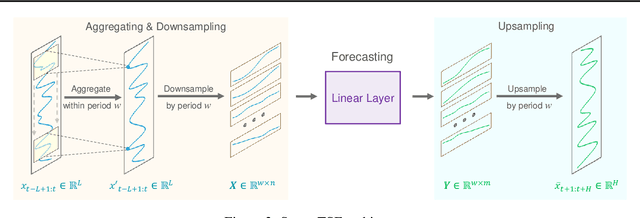
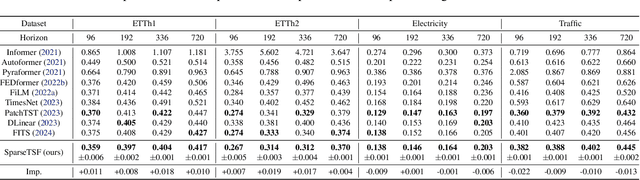
This paper introduces SparseTSF, a novel, extremely lightweight model for Long-term Time Series Forecasting (LTSF), designed to address the challenges of modeling complex temporal dependencies over extended horizons with minimal computational resources. At the heart of SparseTSF lies the Cross-Period Sparse Forecasting technique, which simplifies the forecasting task by decoupling the periodicity and trend in time series data. This technique involves downsampling the original sequences to focus on cross-period trend prediction, effectively extracting periodic features while minimizing the model's complexity and parameter count. Based on this technique, the SparseTSF model uses fewer than 1k parameters to achieve competitive or superior performance compared to state-of-the-art models. Furthermore, SparseTSF showcases remarkable generalization capabilities, making it well-suited for scenarios with limited computational resources, small samples, or low-quality data. The code is available at: https://github.com/lss-1138/SparseTSF.
SegRNN: Segment Recurrent Neural Network for Long-Term Time Series Forecasting
Aug 22, 2023



RNN-based methods have faced challenges in the Long-term Time Series Forecasting (LTSF) domain when dealing with excessively long look-back windows and forecast horizons. Consequently, the dominance in this domain has shifted towards Transformer, MLP, and CNN approaches. The substantial number of recurrent iterations are the fundamental reasons behind the limitations of RNNs in LTSF. To address these issues, we propose two novel strategies to reduce the number of iterations in RNNs for LTSF tasks: Segment-wise Iterations and Parallel Multi-step Forecasting (PMF). RNNs that combine these strategies, namely SegRNN, significantly reduce the required recurrent iterations for LTSF, resulting in notable improvements in forecast accuracy and inference speed. Extensive experiments demonstrate that SegRNN not only outperforms SOTA Transformer-based models but also reduces runtime and memory usage by more than 78%. These achievements provide strong evidence that RNNs continue to excel in LTSF tasks and encourage further exploration of this domain with more RNN-based approaches. The source code is coming soon.
PETformer: Long-term Time Series Forecasting via Placeholder-enhanced Transformer
Aug 09, 2023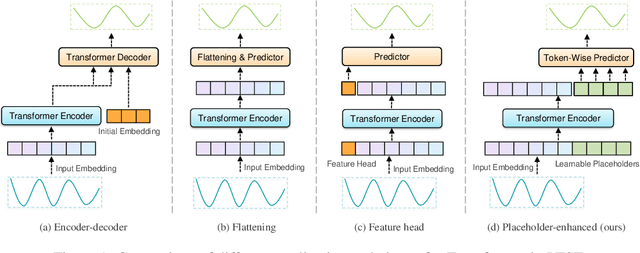

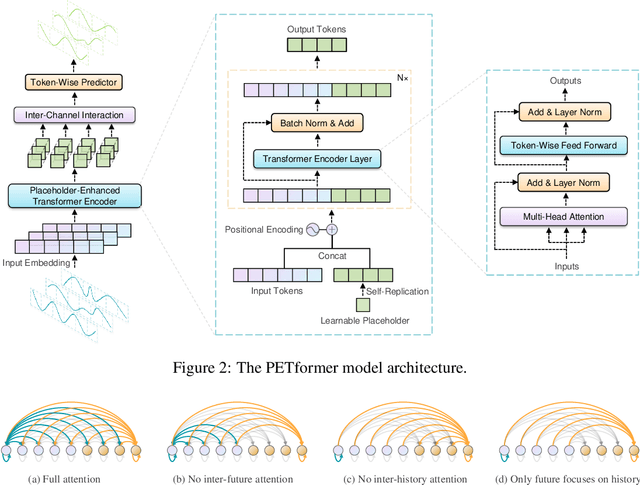
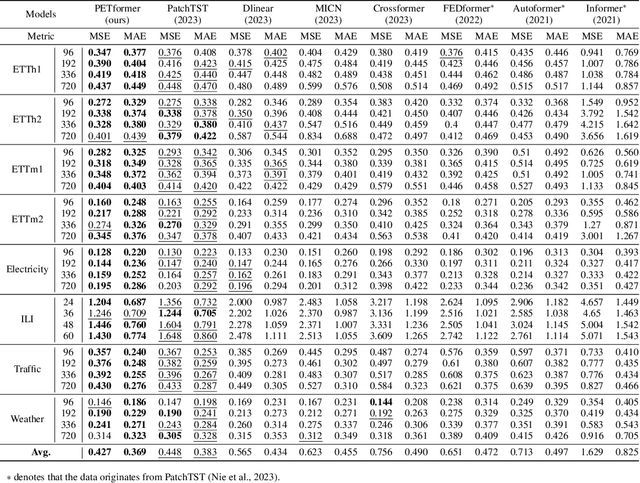
Recently, Transformer-based models have shown remarkable performance in long-term time series forecasting (LTSF) tasks due to their ability to model long-term dependencies. However, the validity of Transformers for LTSF tasks remains debatable, particularly since recent work has shown that simple linear models can outperform numerous Transformer-based approaches. This suggests that there are limitations to the application of Transformer in LTSF. Therefore, this paper investigates three key issues when applying Transformer to LTSF: temporal continuity, information density, and multi-channel relationships. Accordingly, we propose three innovative solutions, including Placeholder Enhancement Technique (PET), Long Sub-sequence Division (LSD), and Multi-channel Separation and Interaction (MSI), which together form a novel model called PETformer. These three key designs introduce prior biases suitable for LTSF tasks. Extensive experiments have demonstrated that PETformer achieves state-of-the-art (SOTA) performance on eight commonly used public datasets for LTSF, outperforming all other models currently available. This demonstrates that Transformer still possesses powerful capabilities in LTSF.
Variation-Incentive Loss Re-weighting for Regression Analysis on Biased Data
Sep 14, 2021
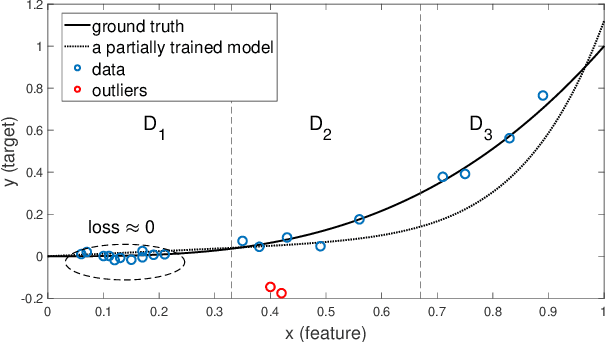
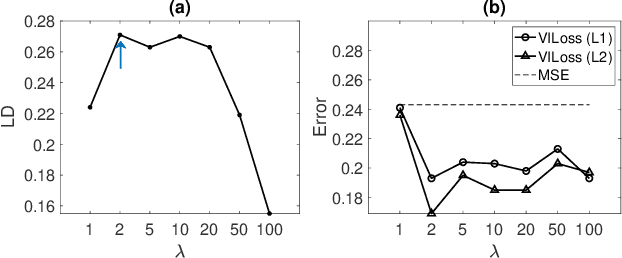
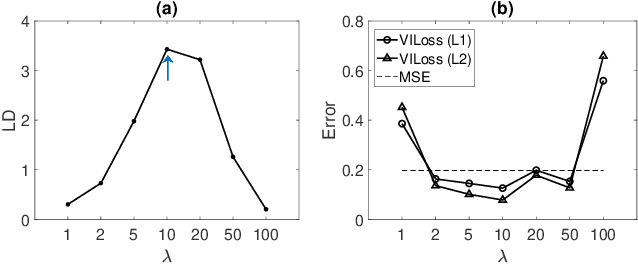
Both classification and regression tasks are susceptible to the biased distribution of training data. However, existing approaches are focused on the class-imbalanced learning and cannot be applied to the problems of numerical regression where the learning targets are continuous values rather than discrete labels. In this paper, we aim to improve the accuracy of the regression analysis by addressing the data skewness/bias during model training. We first introduce two metrics, uniqueness and abnormality, to reflect the localized data distribution from the perspectives of their feature (i.e., input) space and target (i.e., output) space. Combining these two metrics we propose a Variation-Incentive Loss re-weighting method (VILoss) to optimize the gradient descent-based model training for regression analysis. We have conducted comprehensive experiments on both synthetic and real-world data sets. The results show significant improvement in the model quality (reduction in error by up to 11.9%) when using VILoss as the loss criterion in training.
FedProf: Optimizing Federated Learning with Dynamic Data Profiling
Feb 02, 2021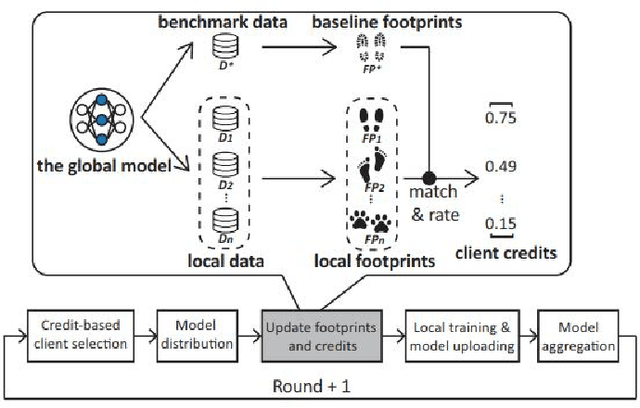
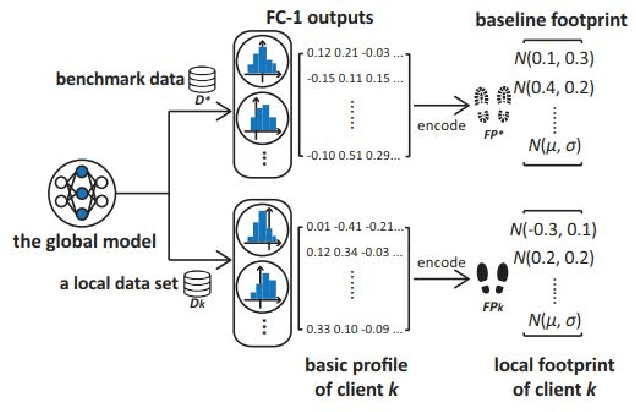
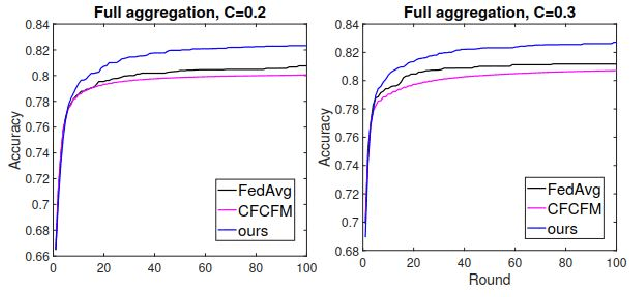
Federated Learning (FL) has shown great potential as a privacy-preserving solution to learning from decentralized data which are only accessible locally on end devices (i.e., clients). In many scenarios, however, a large proportion of the clients are probably in possession of only low-quality data that are biased, noisy or even irrelevant. As a result, they could significantly degrade the quality of the global model we aim to build and slow down its convergence in the course of FL. In light of this, we propose a novel approach to optimizing FL under such circumstances without breaching data privacy. The key of our approach is a dynamic data profiling method for generating model-data footprints on each client and the server. The footprint encodes the representation of the global model on the corresponding data partition based on the output distribution of the model's first fully-connected layer (FC-1). By matching the footprints from clients and the server, we adaptively adjust each client's opportunity of participation in each FL round to mitigate the impact from the clients with low-quality data. We have conducted extensive experiments on public data sets using various FL settings. Results show that our method significantly reduces the number of rounds (by up to 75\%) and overall time (by up to 68\%) required to have the global model converge whiling increasing the global model's accuracy by up to 2.5\%.
An Efficiency-boosting Client Selection Scheme for Federated Learning with Fairness Guarantee
Nov 04, 2020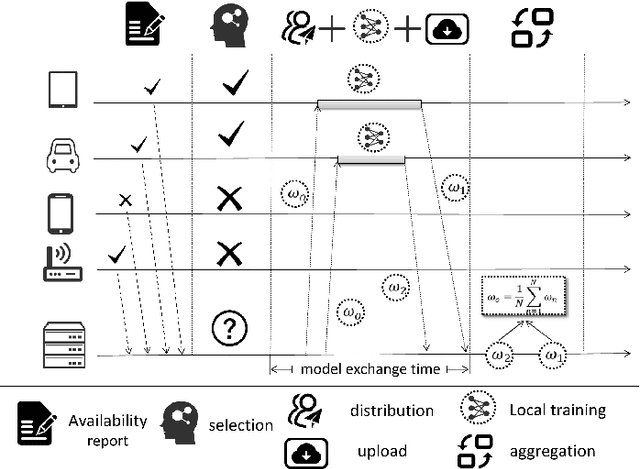


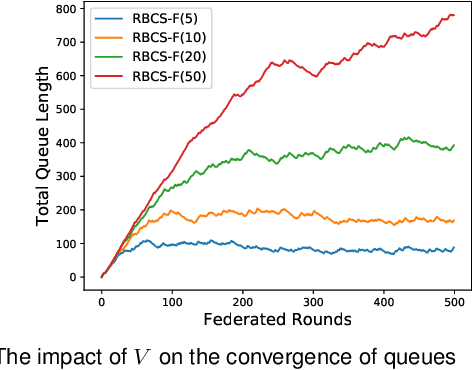
The issue of potential privacy leakage during centralized AI's model training has drawn intensive concern from the public. A Parallel and Distributed Computing (or PDC) scheme, termed Federated Learning (FL), has emerged as a new paradigm to cope with the privacy issue by allowing clients to perform model training locally, without the necessity to upload their personal sensitive data. In FL, the number of clients could be sufficiently large, but the bandwidth available for model distribution and re-upload is quite limited, making it sensible to only involve part of the volunteers to participate in the training process. The client selection policy is critical to an FL process in terms of training efficiency, the final model's quality as well as fairness. In this paper, we will model the fairness guaranteed client selection as a Lyapunov optimization problem and then a C2MAB-based method is proposed for estimation of the model exchange time between each client and the server, based on which we design a fairness guaranteed algorithm termed RBCS-F for problem-solving. The regret of RBCS-F is strictly bounded by a finite constant, justifying its theoretical feasibility. Barring the theoretical results, more empirical data can be derived from our real training experiments on public datasets.
Accelerating Federated Learning over Reliability-Agnostic Clients in Mobile Edge Computing Systems
Jul 28, 2020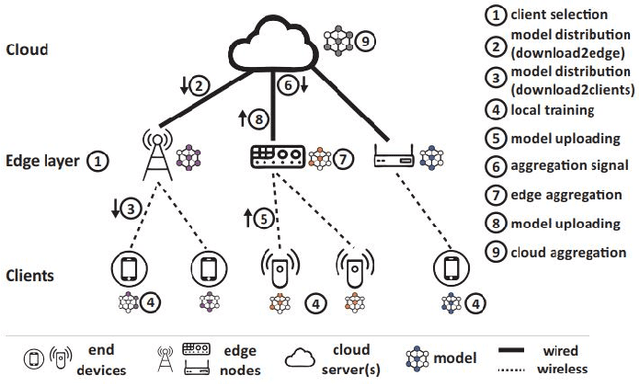
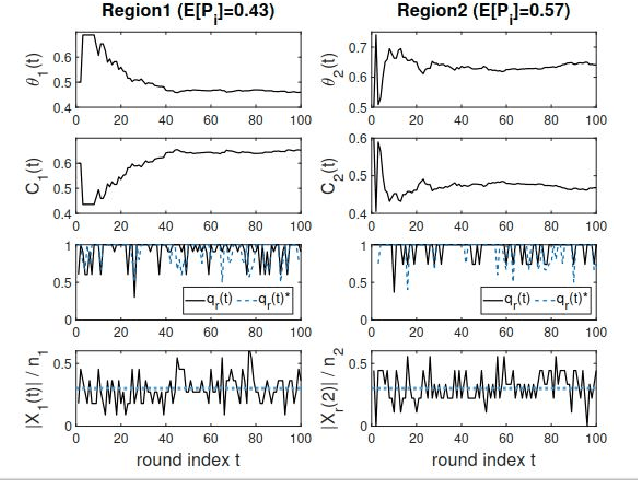
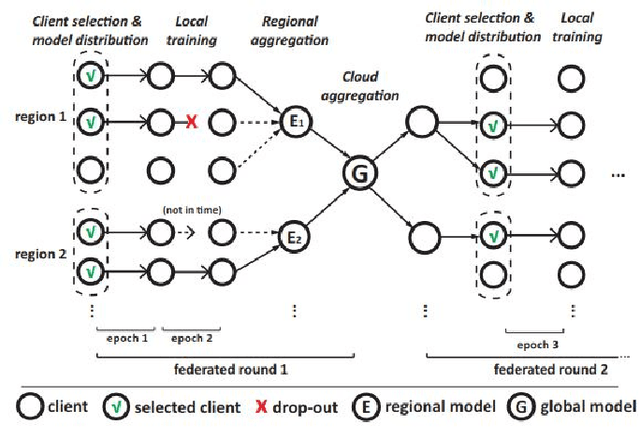
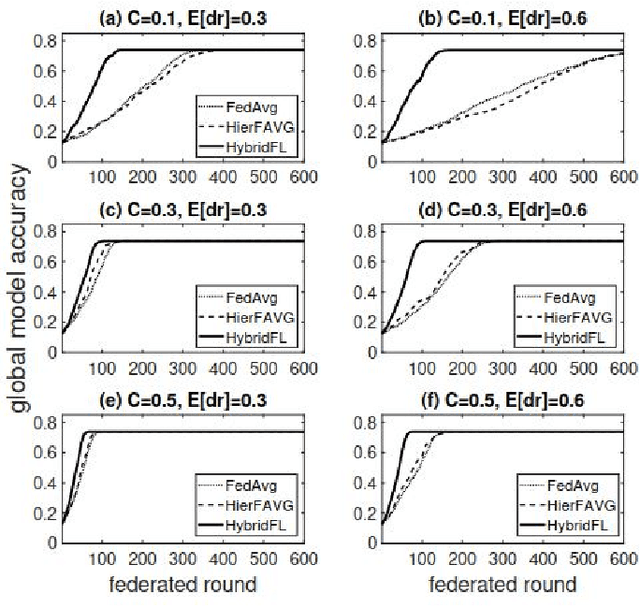
Mobile Edge Computing (MEC), which incorporates the Cloud, edge nodes and end devices, has shown great potential in bringing data processing closer to the data sources. Meanwhile, Federated learning (FL) has emerged as a promising privacy-preserving approach to facilitating AI applications. However, it remains a big challenge to optimize the efficiency and effectiveness of FL when it is integrated with the MEC architecture. Moreover, the unreliable nature (e.g., stragglers and intermittent drop-out) of end devices significantly slows down the FL process and affects the global model's quality in such circumstances. In this paper, a multi-layer federated learning protocol called HybridFL is designed for the MEC architecture. HybridFL adopts two levels (the edge level and the cloud level) of model aggregation enacting different aggregation strategies. Moreover, in order to mitigate stragglers and end device drop-out, we introduce regional slack factors into the stage of client selection performed at the edge nodes using a probabilistic approach without identifying or probing the state of end devices (whose reliability is agnostic). We demonstrate the effectiveness of our method in modulating the proportion of clients selected and present the convergence analysis for our protocol. We have conducted extensive experiments with machine learning tasks in different scales of MEC system. The results show that HybridFL improves the FL training process significantly in terms of shortening the federated round length, speeding up the global model's convergence (by up to 12X) and reducing end device energy consumption (by up to 58%)
SAFA: a Semi-Asynchronous Protocol for Fast Federated Learning with Low Overhead
Oct 03, 2019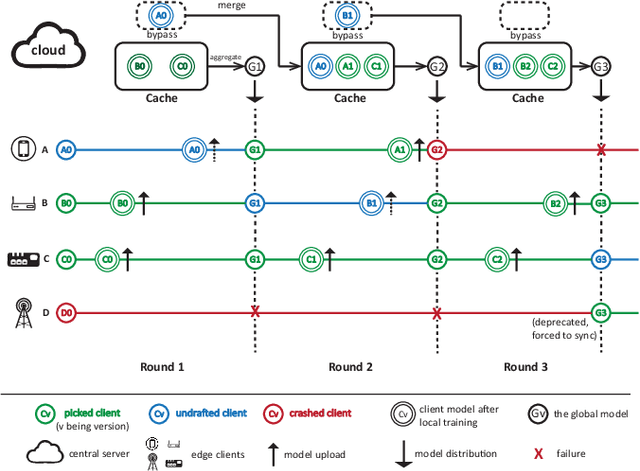
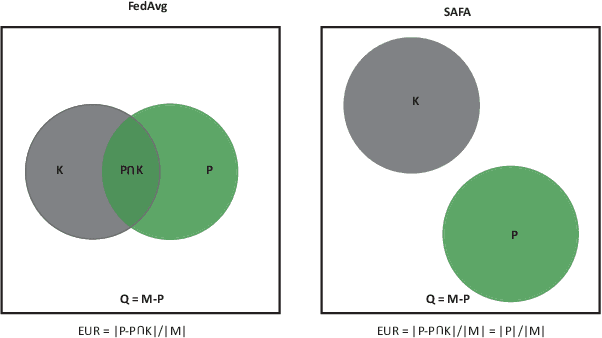
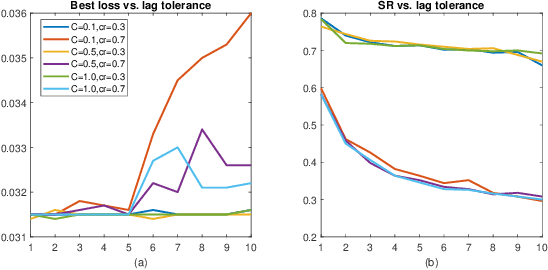
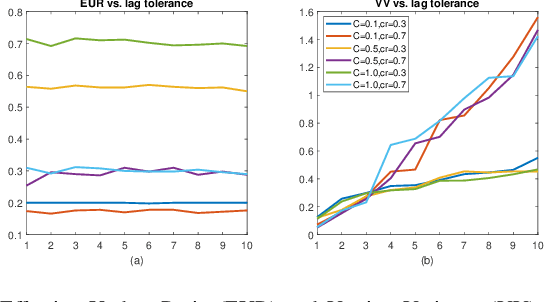
Federated learning (FL) has attracted increasing attention as a promising approach to driving a vast number of devices at the edge with artificial intelligence, i.e., Edge Intelligence. However, it is very challenging to guarantee the efficiency of FL considering the unreliable nature of edge devices while the cost of edge-server communication cannot be neglected. In this paper, we propose SAFA, a semi-asynchronous protocol that avoids problems in the pure synchronous/asynchronous approaches such as heavy downlink traffic and poor convergence rate in extreme conditions (e.g., clients dropping offline frequently). Key principles are introduced in model distribution, client selection and global aggregation, which are designed with tolerance to stragglers for efficiency boost and bias reduction. Extensive experiments on typical machine learning tasks show the effectiveness of the proposed protocol in shortening federated round duration, reducing local resource wastage, and improving the global model's accuracy at a low communication cost.