 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgery: Mitigating Harmful Fine-Tuning for Large Language Models via Attention Sink
Feb 05, 2026Harmful fine-tuning can invalidate safety alignment of large language models, exposing significant safety risks. In this paper, we utilize the attention sink mechanism to mitigate harmful fine-tuning. Specifically, we first measure a statistic named \emph{sink divergence} for each attention head and observe that \emph{different attention heads exhibit two different signs of sink divergence}. To understand its safety implications, we conduct experiments and find that the number of attention heads of positive sink divergence increases along with the increase of the model's harmfulness when undergoing harmful fine-tuning. Based on this finding, we propose a separable sink divergence hypothesis -- \emph{attention heads associating with learning harmful patterns during fine-tuning are separable by their sign of sink divergence}. Based on the hypothesis, we propose a fine-tuning-stage defense, dubbed Surgery. Surgery utilizes a regularizer for sink divergence suppression, which steers attention heads toward the negative sink divergence group, thereby reducing the model's tendency to learn and amplify harmful patterns. Extensive experiments demonstrate that Surgery improves defense performance by 5.90\%, 11.25\%, and 9.55\% on the BeaverTails, HarmBench, and SorryBench benchmarks, respectively. Source code is available on https://github.com/Lslland/Surgery.
HuBE: Cross-Embodiment Human-like Behavior Execution for Humanoid Robots
Aug 26, 2025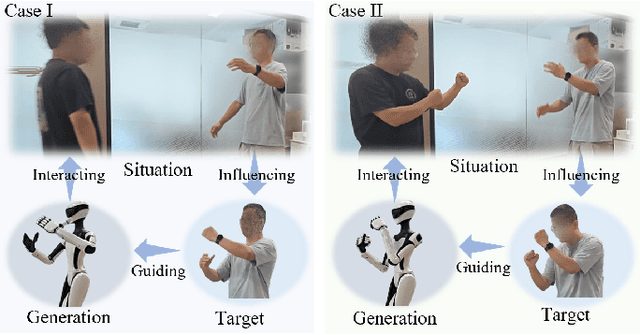
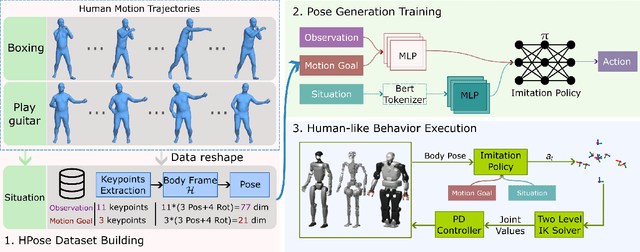

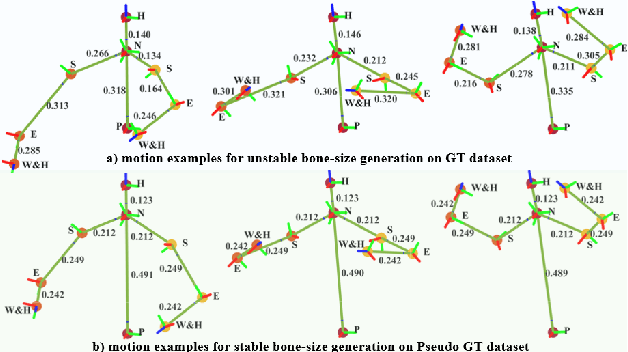
Achieving both behavioral similarity and appropriateness in human-like motion generation for humanoid robot remains an open challenge, further compounded by the lack of cross-embodiment adaptability. To address this problem, we propose HuBE, a bi-level closed-loop framework that integrates robot state, goal poses, and contextual situations to generate human-like behaviors, ensuring both behavioral similarity and appropriateness, and eliminating structural mismatches between motion generation and execution. To support this framework, we construct HPose, a context-enriched dataset featuring fine-grained situational annotations. Furthermore, we introduce a bone scaling-based data augmentation strategy that ensures millimeter-level compatibility across heterogeneous humanoid robots. Comprehensive evaluations on multiple commercial platforms demonstrate that HuBE significantly improves motion similarity, behavioral appropriateness, and computational efficiency over state-of-the-art baselines, establishing a solid foundation for transferable and human-like behavior execution across diverse humanoid robots.
Temporal Query Network for Efficient Multivariate Time Series Forecasting
May 19, 2025Sufficiently modeling the correlations among variables (aka channels) is crucial for achieving accurate multivariate time series forecasting (MTSF). In this paper, we propose a novel technique called Temporal Query (TQ) to more effectively capture multivariate correlations, thereby improving model performance in MTSF tasks. Technically, the TQ technique employs periodically shifted learnable vectors as queries in the attention mechanism to capture global inter-variable patterns, while the keys and values are derived from the raw input data to encode local, sample-level correlations. Building upon the TQ technique, we develop a simple yet efficient model named Temporal Query Network (TQNet), which employs only a single-layer attention mechanism and a lightweight multi-layer perceptron (MLP). Extensive experiments demonstrate that TQNet learns more robust multivariate correlations, achieving state-of-the-art forecasting accuracy across 12 challenging real-world datasets. Furthermore, TQNet achieves high efficiency comparable to linear-based methods even on high-dimensional datasets, balancing performance and computational cost. The code is available at: https://github.com/ACAT-SCUT/TQNet.
CrowdSelect: Synthetic Instruction Data Selection with Multi-LLM Wisdom
Mar 03, 2025



Distilling advanced Large Language Models' instruction-following capabilities into smaller models using a selected subset has become a mainstream approach in model training. While existing synthetic instruction data selection strategies rely mainly on single-dimensional signals (i.e., reward scores, model perplexity), they fail to capture the complexity of instruction-following across diverse fields. Therefore, we investigate more diverse signals to capture comprehensive instruction-response pair characteristics and propose three foundational metrics that leverage Multi-LLM wisdom, informed by (1) diverse LLM responses and (2) reward model assessment. Building upon base metrics, we propose CrowdSelect, an integrated metric incorporating a clustering-based approach to maintain response diversity. Our comprehensive experiments demonstrate that our foundation metrics consistently improve performance across 4 base models on MT-bench and Arena-Hard. CrowdSelect, efficiently incorporating all metrics, achieves state-of-the-art performance in both Full and LoRA fine-tuning, showing improvements of 4.81% on Arena-Hard and 11.1% on MT-bench with Llama-3.2-3b-instruct. We hope our findings will bring valuable insights for future research in this direction. Code are available at https://github.com/listentm/crowdselect.
Continuous Autoregressive Modeling with Stochastic Monotonic Alignment for Speech Synthesis
Feb 03, 2025
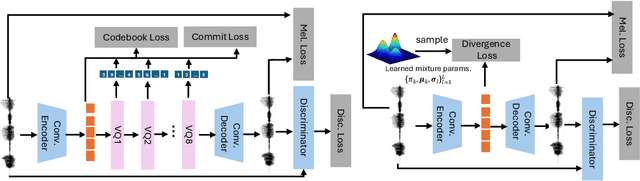
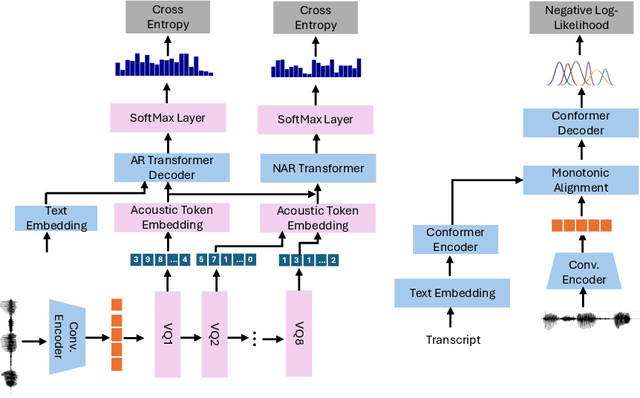
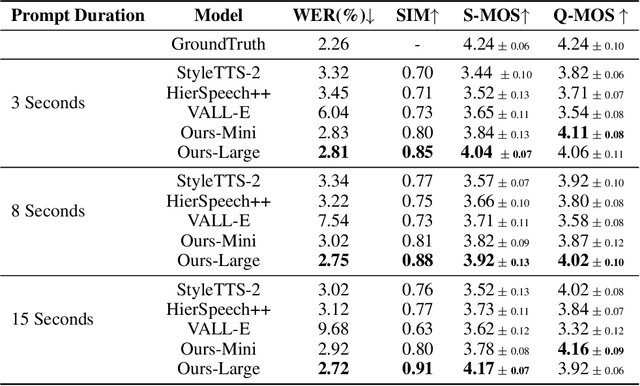
We propose a novel autoregressive modeling approach for speech synthesis, combining a variational autoencoder (VAE) with a multi-modal latent space and an autoregressive model that uses Gaussian Mixture Models (GMM) as the conditional probability distribution. Unlike previous methods that rely on residual vector quantization, our model leverages continuous speech representations from the VAE's latent space, greatly simplifying the training and inference pipelines. We also introduce a stochastic monotonic alignment mechanism to enforce strict monotonic alignments. Our approach significantly outperforms the state-of-the-art autoregressive model VALL-E in both subjective and objective evaluations, achieving these results with only 10.3\% of VALL-E's parameters. This demonstrates the potential of continuous speech language models as a more efficient alternative to existing quantization-based speech language models. Sample audio can be found at https://tinyurl.com/gmm-lm-tts.
* ICLR 2025
Targeted Vaccine: Safety Alignment for Large Language Models against Harmful Fine-Tuning via Layer-wise Perturbation
Oct 13, 2024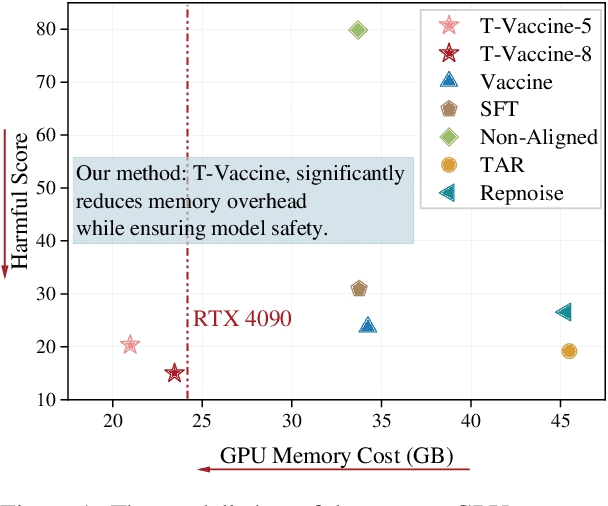
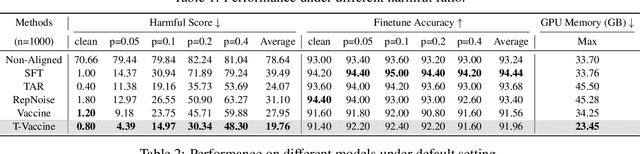
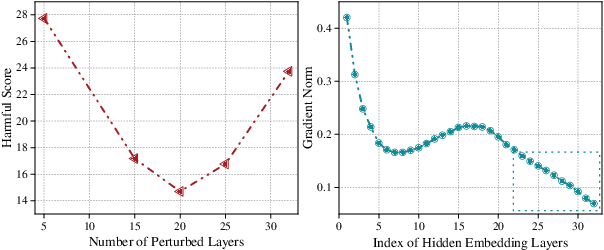
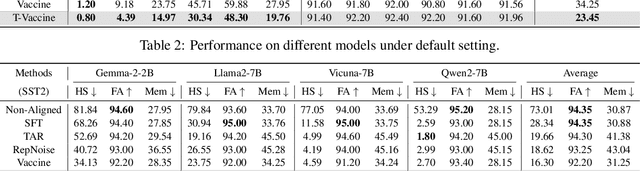
Harmful fine-tuning attack poses a serious threat to the online fine-tuning service. Vaccine, a recent alignment-stage defense, applies uniform perturbation to all layers of embedding to make the model robust to the simulated embedding drift. However, applying layer-wise uniform perturbation may lead to excess perturbations for some particular safety-irrelevant layers, resulting in defense performance degradation and unnecessary memory consumption. To address this limitation, we propose Targeted Vaccine (T-Vaccine), a memory-efficient safety alignment method that applies perturbation to only selected layers of the model. T-Vaccine follows two core steps: First, it uses gradient norm as a statistical metric to identify the safety-critical layers. Second, instead of applying uniform perturbation across all layers, T-Vaccine only applies perturbation to the safety-critical layers while keeping other layers frozen during training. Results show that T-Vaccine outperforms Vaccine in terms of both defense effectiveness and resource efficiency. Comparison with other defense baselines, e.g., RepNoise and TAR also demonstrate the superiority of T-Vaccine. Notably, T-Vaccine is the first defense that can address harmful fine-tuning issues for a 7B pre-trained models trained on consumer GPUs with limited memory (e.g., RTX 4090). Our code is available at https://github.com/Lslland/T-Vaccine.
CycleNet: Enhancing Time Series Forecasting through Modeling Periodic Patterns
Sep 27, 2024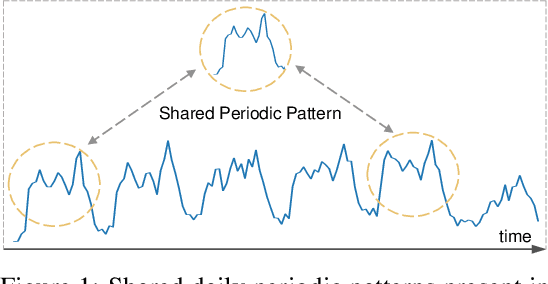
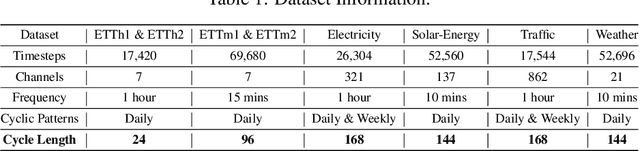
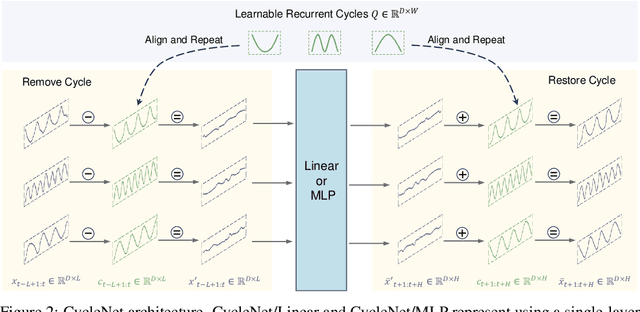
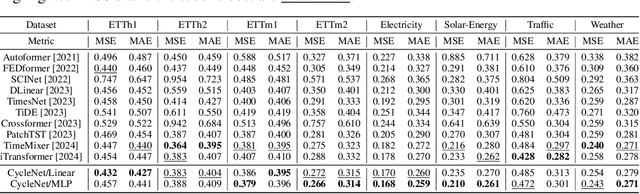
The stable periodic patterns present in time series data serve as the foundation for conducting long-horizon forecasts. In this paper, we pioneer the exploration of explicitly modeling this periodicity to enhance the performance of models in long-term time series forecasting (LTSF) tasks. Specifically, we introduce the Residual Cycle Forecasting (RCF) technique, which utilizes learnable recurrent cycles to model the inherent periodic patterns within sequences, and then performs predictions on the residual components of the modeled cycles. Combining RCF with a Linear layer or a shallow MLP forms the simple yet powerful method proposed in this paper, called CycleNet. CycleNet achieves state-of-the-art prediction accuracy in multiple domains including electricity, weather, and energy, while offering significant efficiency advantages by reducing over 90% of the required parameter quantity. Furthermore, as a novel plug-and-play technique, the RCF can also significantly improve the prediction accuracy of existing models, including PatchTST and iTransformer. The source code is available at: https://github.com/ACAT-SCUT/CycleNet.
SparseTSF: Modeling Long-term Time Series Forecasting with 1k Parameters
May 02, 2024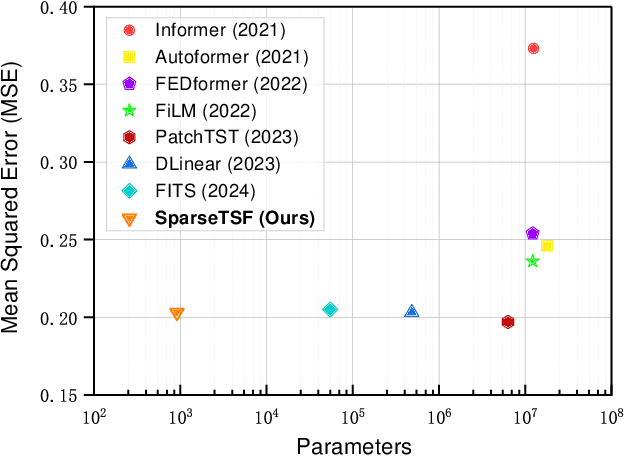

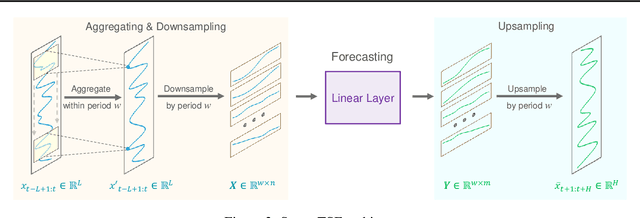
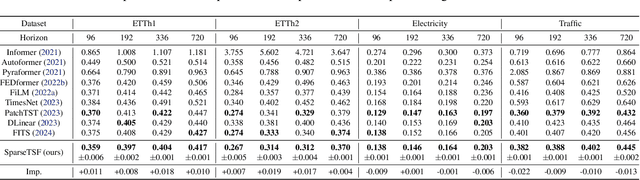
This paper introduces SparseTSF, a novel, extremely lightweight model for Long-term Time Series Forecasting (LTSF), designed to address the challenges of modeling complex temporal dependencies over extended horizons with minimal computational resources. At the heart of SparseTSF lies the Cross-Period Sparse Forecasting technique, which simplifies the forecasting task by decoupling the periodicity and trend in time series data. This technique involves downsampling the original sequences to focus on cross-period trend prediction, effectively extracting periodic features while minimizing the model's complexity and parameter count. Based on this technique, the SparseTSF model uses fewer than 1k parameters to achieve competitive or superior performance compared to state-of-the-art models. Furthermore, SparseTSF showcases remarkable generalization capabilities, making it well-suited for scenarios with limited computational resources, small samples, or low-quality data. The code is available at: https://github.com/lss-1138/SparseTSF.
VoxGenesis: Unsupervised Discovery of Latent Speaker Manifold for Speech Synthesis
Mar 01, 2024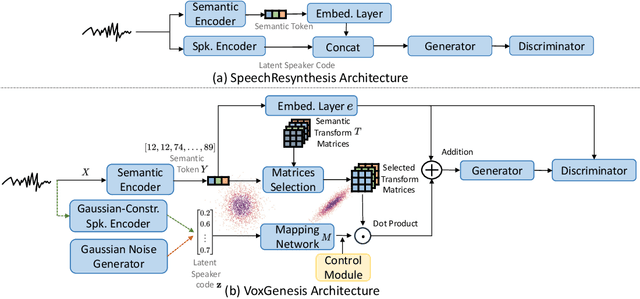
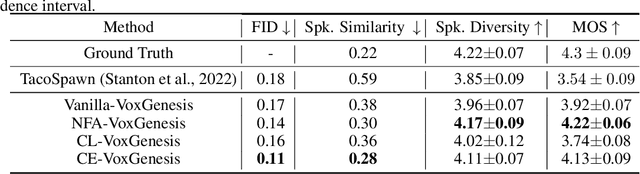
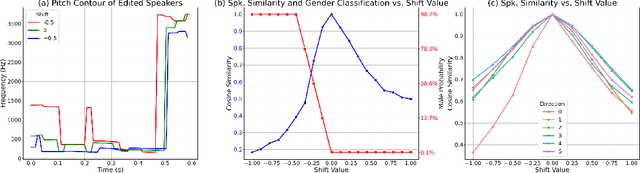

Achieving nuanced and accurate emulation of human voice has been a longstanding goal in artificial intelligence. Although significant progress has been made in recent years, the mainstream of speech synthesis models still relies on supervised speaker modeling and explicit reference utterances. However, there are many aspects of human voice, such as emotion, intonation, and speaking style, for which it is hard to obtain accurate labels. In this paper, we propose VoxGenesis, a novel unsupervised speech synthesis framework that can discover a latent speaker manifold and meaningful voice editing directions without supervision. VoxGenesis is conceptually simple. Instead of mapping speech features to waveforms deterministically, VoxGenesis transforms a Gaussian distribution into speech distributions conditioned and aligned by semantic tokens. This forces the model to learn a speaker distribution disentangled from the semantic content. During the inference, sampling from the Gaussian distribution enables the creation of novel speakers with distinct characteristics. More importantly, the exploration of latent space uncovers human-interpretable directions associated with specific speaker characteristics such as gender attributes, pitch, tone, and emotion, allowing for voice editing by manipulating the latent codes along these identified directions. We conduct extensive experiments to evaluate the proposed VoxGenesis using both subjective and objective metrics, finding that it produces significantly more diverse and realistic speakers with distinct characteristics than the previous approaches. We also show that latent space manipulation produces consistent and human-identifiable effects that are not detrimental to the speech quality, which was not possible with previous approaches. Audio samples of VoxGenesis can be found at: \url{https://bit.ly/VoxGenesis}.
Asymmetric Clean Segments-Guided Self-Supervised Learning for Robust Speaker Verification
Sep 08, 2023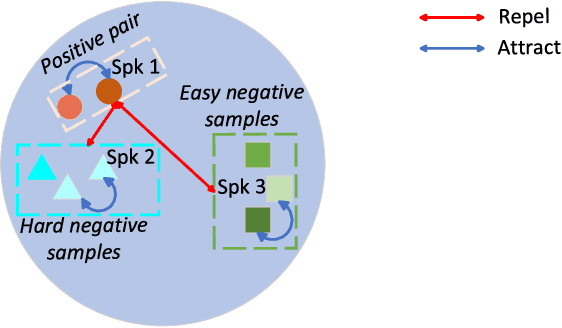
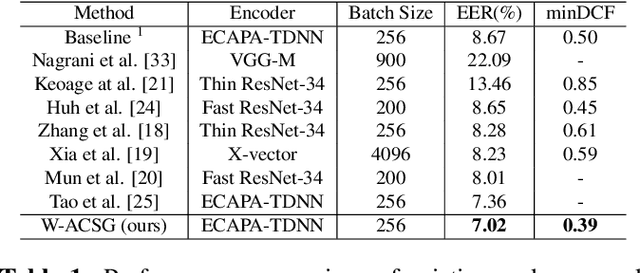
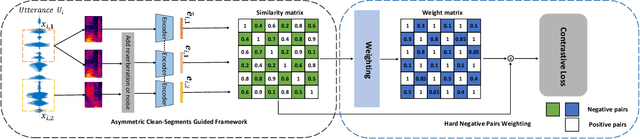

Contrastive self-supervised learning (CSL) for speaker verification (SV) has drawn increasing interest recently due to its ability to exploit unlabeled data. Performing data augmentation on raw waveforms, such as adding noise or reverberation, plays a pivotal role in achieving promising results in SV. Data augmentation, however, demands meticulous calibration to ensure intact speaker-specific information, which is difficult to achieve without speaker labels. To address this issue, we introduce a novel framework by incorporating clean and augmented segments into the contrastive training pipeline. The clean segments are repurposed to pair with noisy segments to form additional positive and negative pairs. Moreover, the contrastive loss is weighted to increase the difference between the clean and augmented embeddings of different speakers. Experimental results on Voxceleb1 suggest that the proposed framework can achieve a remarkable 19% improvement over the conventional methods, and it surpasses many existing state-of-the-art techniques.