 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvCounsel: A Conversational Dataset for Student Counseling
Nov 01, 2024



Student mental health is a sensitive issue that necessitates special attention. A primary concern is the student-to-counselor ratio, which surpasses the recommended standard of 250:1 in most universities. This imbalance results in extended waiting periods for in-person consultations, which cause suboptimal treatment. Significant efforts have been directed toward developing mental health dialogue systems utilizing the existing open-source mental health-related datasets. However, currently available datasets either discuss general topics or various strategies that may not be viable for direct application due to numerous ethical constraints inherent in this research domain. To address this issue, this paper introduces a specialized mental health dataset that emphasizes the active listening strategy employed in conversation for counseling, also named as ConvCounsel. This dataset comprises both speech and text data, which can facilitate the development of a reliable pipeline for mental health dialogue systems. To demonstrate the utility of the proposed dataset, this paper also presents the NYCUKA, a spoken mental health dialogue system that is designed by using the ConvCounsel dataset. The results show the merit of using this dataset.
Attention-Guided Adaptation for Code-Switching Speech Recognition
Dec 14, 2023The prevalence of the powerful multilingual models, such as Whisper, has significantly advanced the researches on speech recognition. However, these models often struggle with handling the code-switching setting, which is essential in multilingual speech recognition. Recent studies have attempted to address this setting by separating the modules for different languages to ensure distinct latent representations for languages. Some other methods considered the switching mechanism based on language identification. In this study, a new attention-guided adaptation is proposed to conduct parameter-efficient learning for bilingual ASR. This method selects those attention heads in a model which closely express language identities and then guided those heads to be correctly attended with their corresponding languages. The experiments on the Mandarin-English code-switching speech corpus show that the proposed approach achieves a 14.2% mixed error rate, surpassing state-of-the-art method, where only 5.6% additional parameters over Whisper are trained.
Contrastive Speaker Embedding With Sequential Disentanglement
Sep 23, 2023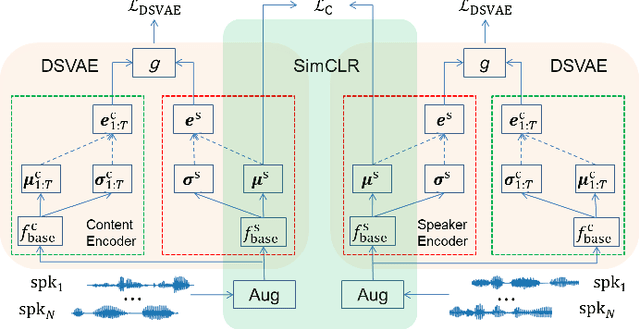
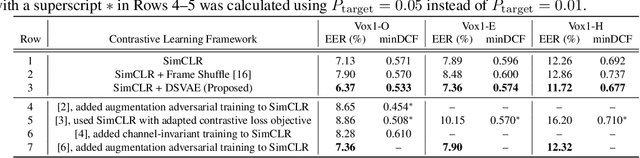
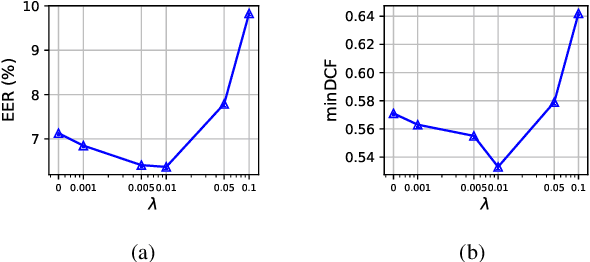
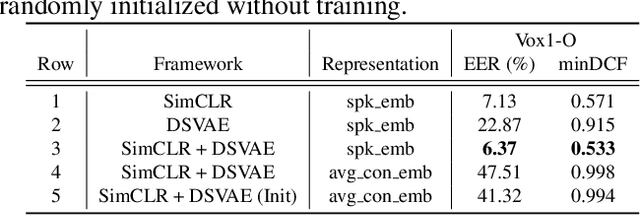
Contrastive speaker embedding assumes that the contrast between the positive and negative pairs of speech segments is attributed to speaker identity only. However, this assumption is incorrect because speech signals contain not only speaker identity but also linguistic content. In this paper, we propose a contrastive learning framework with sequential disentanglement to remove linguistic content by incorporating a disentangled sequential variational autoencoder (DSVAE) into the conventional SimCLR framework. The DSVAE aims to disentangle speaker factors from content factors in an embedding space so that only the speaker factors are used for constructing a contrastive loss objective. Because content factors have been removed from the contrastive learning, the resulting speaker embeddings will be content-invariant. Experimental results on VoxCeleb1-test show that the proposed method consistently outperforms SimCLR. This suggests that applying sequential disentanglement is beneficial to learning speaker-discriminative embeddings.
Asymmetric Clean Segments-Guided Self-Supervised Learning for Robust Speaker Verification
Sep 08, 2023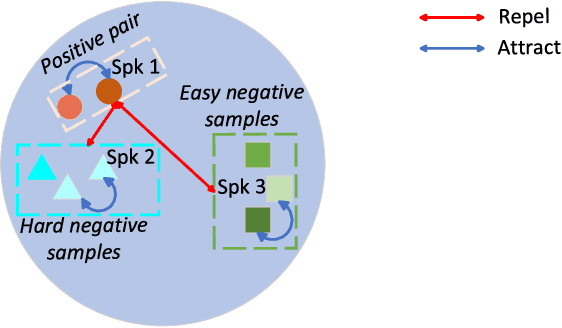
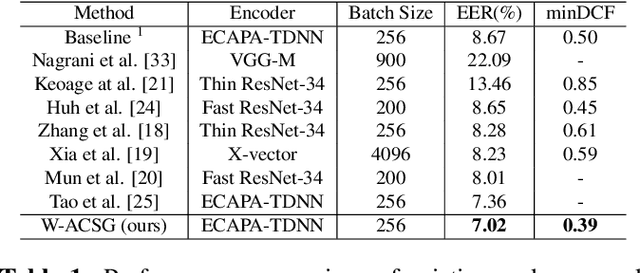
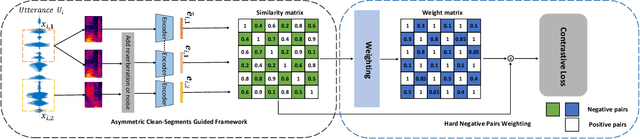

Contrastive self-supervised learning (CSL) for speaker verification (SV) has drawn increasing interest recently due to its ability to exploit unlabeled data. Performing data augmentation on raw waveforms, such as adding noise or reverberation, plays a pivotal role in achieving promising results in SV. Data augmentation, however, demands meticulous calibration to ensure intact speaker-specific information, which is difficult to achieve without speaker labels. To address this issue, we introduce a novel framework by incorporating clean and augmented segments into the contrastive training pipeline. The clean segments are repurposed to pair with noisy segments to form additional positive and negative pairs. Moreover, the contrastive loss is weighted to increase the difference between the clean and augmented embeddings of different speakers. Experimental results on Voxceleb1 suggest that the proposed framework can achieve a remarkable 19% improvement over the conventional methods, and it surpasses many existing state-of-the-art techniques.
Parameter-Efficient Learning for Text-to-Speech Accent Adaptation
May 18, 2023This paper presents a parameter-efficient learning (PEL) to develop a low-resource accent adaptation for text-to-speech (TTS). A resource-efficient adaptation from a frozen pre-trained TTS model is developed by using only 1.2\% to 0.8\% of original trainable parameters to achieve competitive performance in voice synthesis. Motivated by a theoretical foundation of optimal transport (OT), this study carries out PEL for TTS where an auxiliary unsupervised loss based on OT is introduced to maximize a difference between the pre-trained source domain and the (unseen) target domain, in addition to its supervised training loss. Further, we leverage upon this unsupervised loss refinement to boost system performance via either sliced Wasserstein distance or maximum mean discrepancy. The merit of this work is demonstrated by fulfilling PEL solutions based on residual adapter learning, and model reprogramming when evaluating the Mandarin accent adaptation. Experiment results show that the proposed methods can achieve competitive naturalness with parameter-efficient decoder fine-tuning, and the auxiliary unsupervised loss improves model performance empirically.
BALSON: Bayesian Least Squares Optimization with Nonnegative L1-Norm Constraint
Jul 08, 2018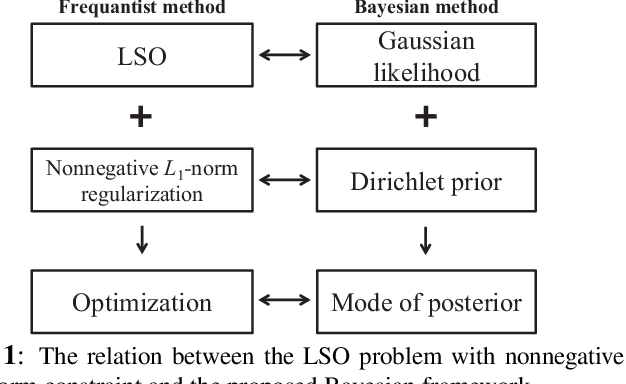
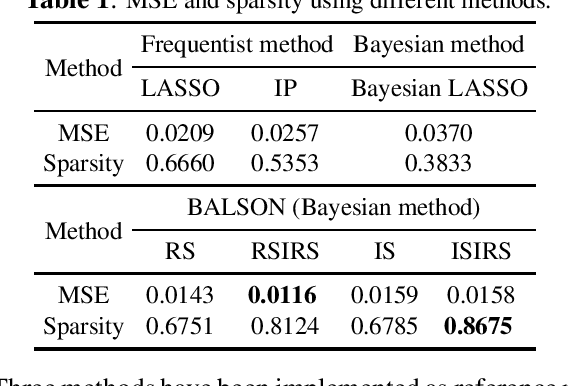
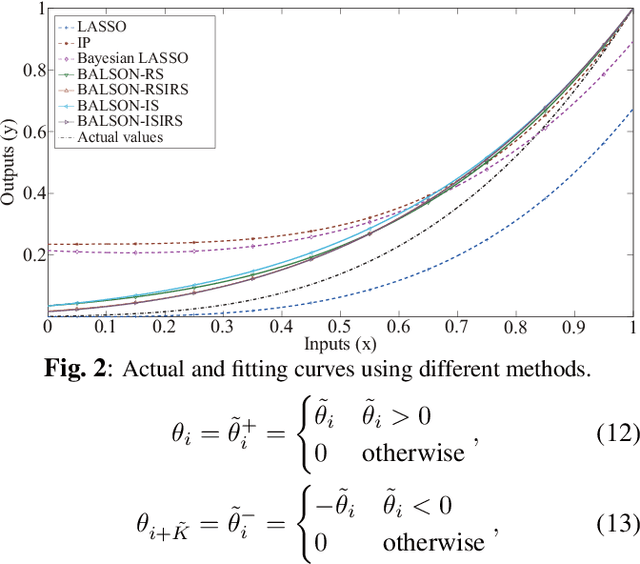
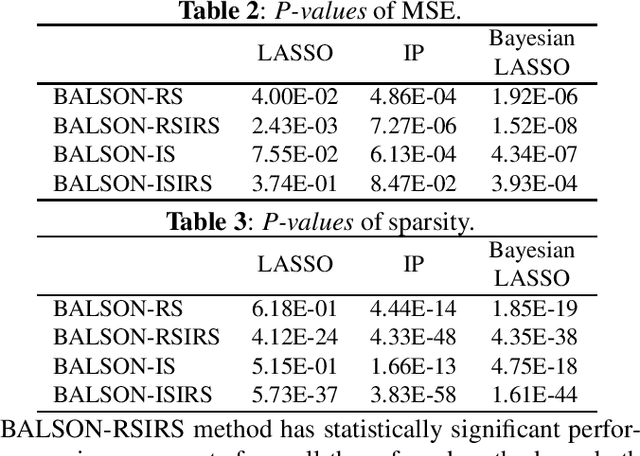
A Bayesian approach termed BAyesian Least Squares Optimization with Nonnegative L1-norm constraint (BALSON) is proposed. The error distribution of data fitting is described by Gaussian likelihood. The parameter distribution is assumed to be a Dirichlet distribution. With the Bayes rule, searching for the optimal parameters is equivalent to finding the mode of the posterior distribution. In order to explicitly characterize the nonnegative L1-norm constraint of the parameters, we further approximate the true posterior distribution by a Dirichlet distribution. We estimate the statistics of the approximating Dirichlet posterior distribution by sampling methods. Four sampling methods have been introduced. With the estimated posterior distributions, the original parameters can be effectively reconstructed in polynomial fitting problems, and the BALSON framework is found to perform better than conventional methods.