 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleNet: Searching for the Model to Scale
Jul 15, 2022
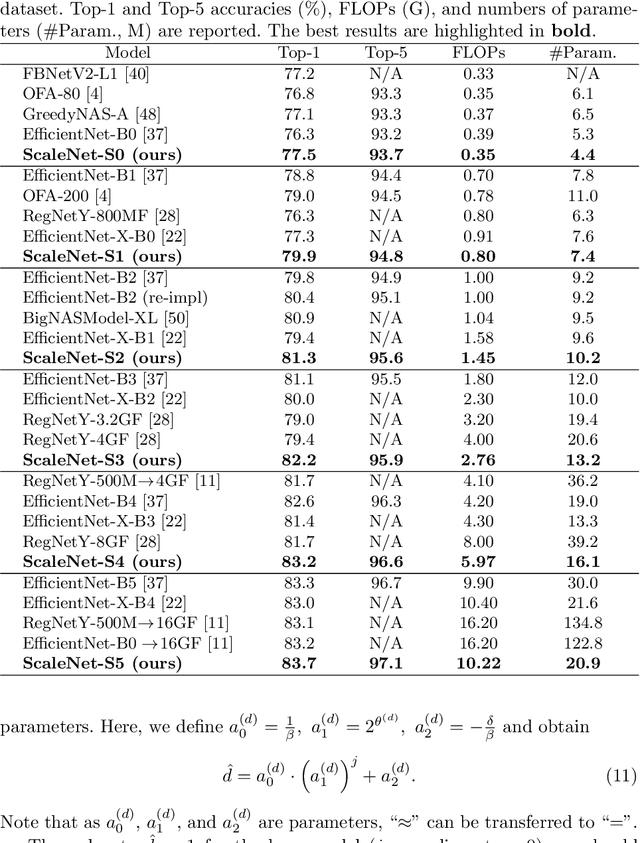
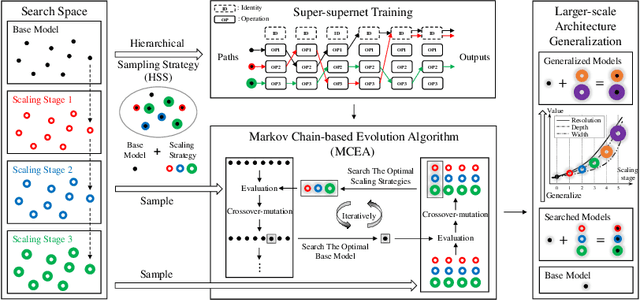
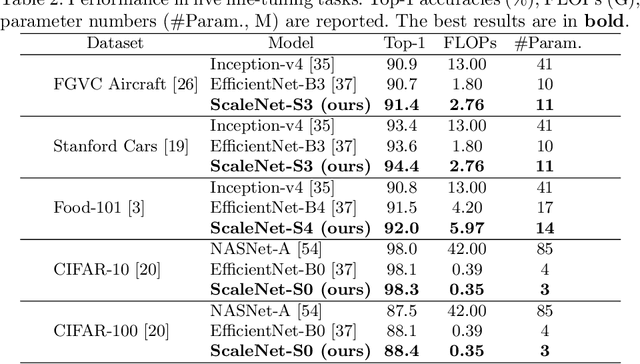
Recently, community has paid increasing attention on model scaling and contributed to developing a model family with a wide spectrum of scales. Current methods either simply resort to a one-shot NAS manner to construct a non-structural and non-scalable model family or rely on a manual yet fixed scaling strategy to scale an unnecessarily best base model. In this paper, we bridge both two components and propose ScaleNet to jointly search base model and scaling strategy so that the scaled large model can have more promising performance. Concretely, we design a super-supernet to embody models with different spectrum of sizes (e.g., FLOPs). Then, the scaling strategy can be learned interactively with the base model via a Markov chain-based evolution algorithm and generalized to develop even larger models. To obtain a decent super-supernet, we design a hierarchical sampling strategy to enhance its training sufficiency and alleviate the disturbance. Experimental results show our scaled networks enjoy significant performance superiority on various FLOPs, but with at least 2.53x reduction on search cost. Codes are available at https://github.com/luminolx/ScaleNet.
Searching for Network Width with Bilaterally Coupled Network
Mar 25, 2022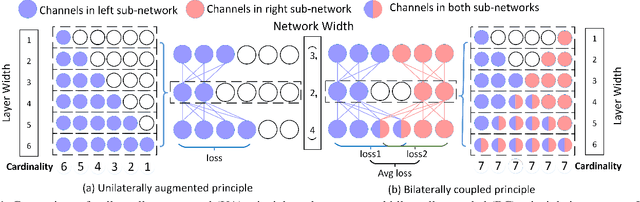
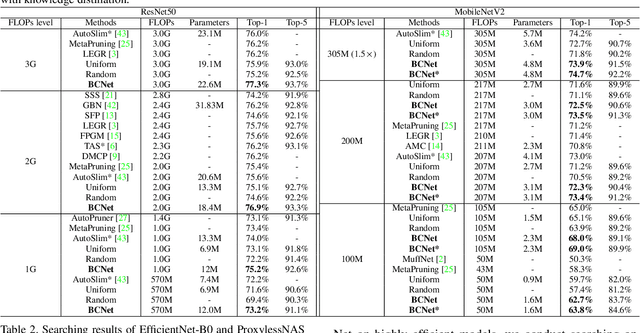
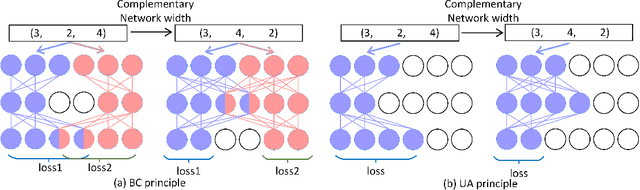
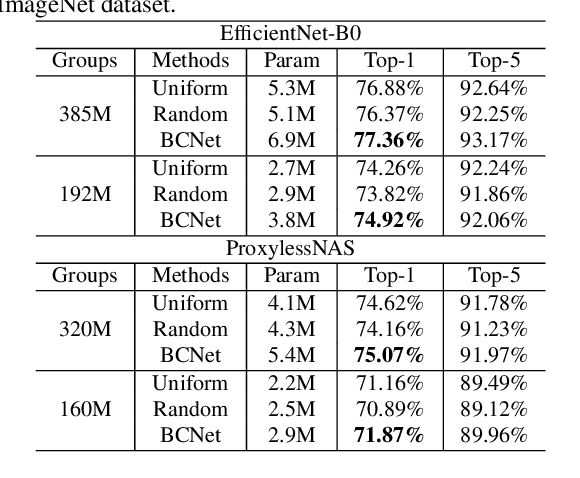
Searching for a more compact network width recently serves as an effective way of channel pruning for the deployment of convolutional neural networks (CNNs) under hardware constraints. To fulfill the searching, a one-shot supernet is usually leveraged to efficiently evaluate the performance \wrt~different network widths. However, current methods mainly follow a \textit{unilaterally augmented} (UA) principle for the evaluation of each width, which induces the training unfairness of channels in supernet. In this paper, we introduce a new supernet called Bilaterally Coupled Network (BCNet) to address this issue. In BCNet, each channel is fairly trained and responsible for the same amount of network widths, thus each network width can be evaluated more accurately. Besides, we propose to reduce the redundant search space and present the BCNetV2 as the enhanced supernet to ensure rigorous training fairness over channels. Furthermore, we leverage a stochastic complementary strategy for training the BCNet, and propose a prior initial population sampling method to boost the performance of the evolutionary search. We also propose the first open-source width benchmark on macro structures named Channel-Bench-Macro for the better comparison of width search algorithms. Extensive experiments on benchmark CIFAR-10 and ImageNet datasets indicate that our method can achieve state-of-the-art or competing performance over other baseline methods. Moreover, our method turns out to further boost the performance of NAS models by refining their network widths. For example, with the same FLOPs budget, our obtained EfficientNet-B0 achieves 77.53\% Top-1 accuracy on ImageNet dataset, surpassing the performance of original setting by 0.65\%.
Vision Transformer Architecture Search
Jun 25, 2021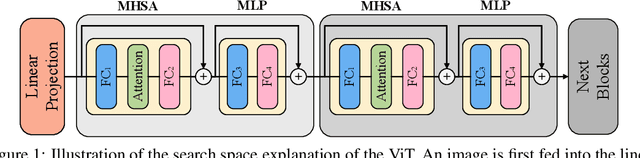

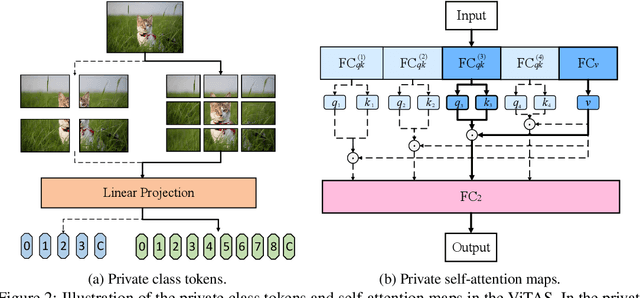

Recently, transformers have shown great superiority in solving computer vision tasks by modeling images as a sequence of manually-split patches with self-attention mechanism. However, current architectures of vision transformers (ViTs) are simply inherited from natural language processing (NLP) tasks and have not been sufficiently investigated and optimized. In this paper, we make a further step by examining the intrinsic structure of transformers for vision tasks and propose an architecture search method, dubbed ViTAS, to search for the optimal architecture with similar hardware budgets. Concretely, we design a new effective yet efficient weight sharing paradigm for ViTs, such that architectures with different token embedding, sequence size, number of heads, width, and depth can be derived from a single super-transformer. Moreover, to cater for the variance of distinct architectures, we introduce \textit{private} class token and self-attention maps in the super-transformer. In addition, to adapt the searching for different budgets, we propose to search the sampling probability of identity operation. Experimental results show that our ViTAS attains excellent results compared to existing pure transformer architectures. For example, with $1.3$G FLOPs budget, our searched architecture achieves $74.7\%$ top-$1$ accuracy on ImageNet and is $2.5\%$ superior than the current baseline ViT architecture. Code is available at \url{https://github.com/xiusu/ViTAS}.
Cross-layer Navigation Convolutional Neural Network for Fine-grained Visual Classification
Jun 21, 2021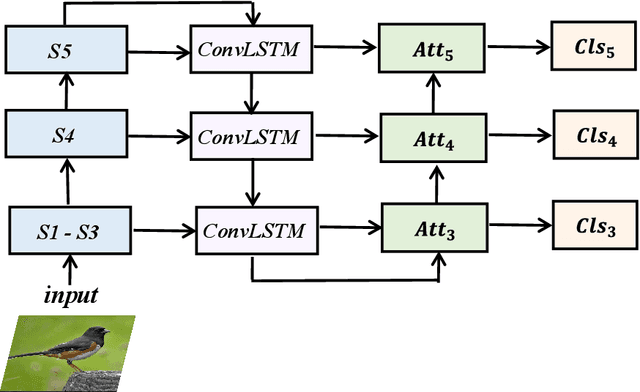
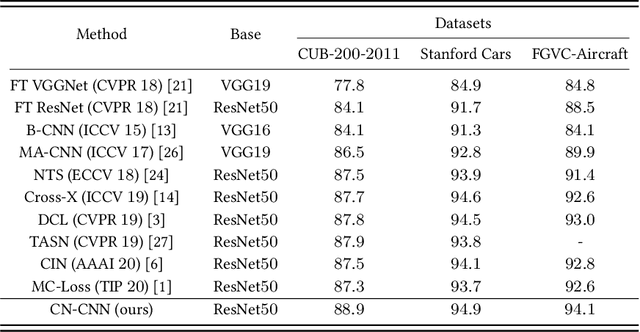
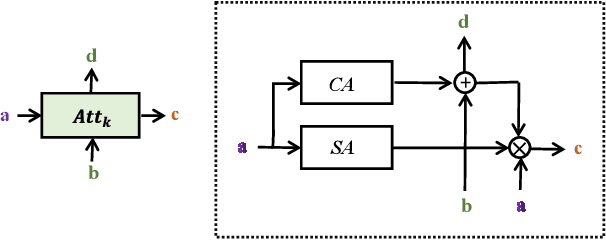

Fine-grained visual classification (FGVC) aims to classify sub-classes of objects in the same super-class (e.g., species of birds, models of cars). For the FGVC tasks, the essential solution is to find discriminative subtle information of the target from local regions. TraditionalFGVC models preferred to use the refined features,i.e., high-level semantic information for recognition and rarely use low-level in-formation. However, it turns out that low-level information which contains rich detail information also has effect on improving performance. Therefore, in this paper, we propose cross-layer navigation convolutional neural network for feature fusion. First, the feature maps extracted by the backbone network are fed into a convolutional long short-term memory model sequentially from high-level to low-level to perform feature aggregation. Then, attention mechanisms are used after feature fusion to extract spatial and channel information while linking the high-level semantic information and the low-level texture features, which can better locate the discriminative regions for the FGVC. In the experiments, three commonly used FGVC datasets, including CUB-200-2011, Stanford-Cars, andFGVC-Aircraft datasets, are used for evaluation and we demonstrate the superiority of the proposed method by comparing it with other referred FGVC methods to show that this method achieves superior results.
Structured DropConnect for Uncertainty Inference in Image Classification
Jun 16, 2021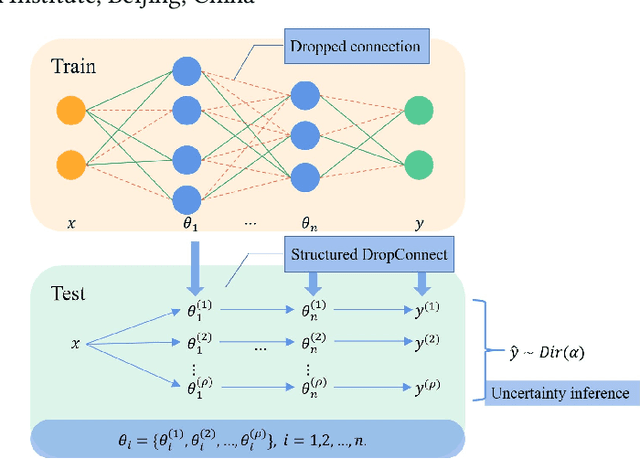


With the complexity of the network structure, uncertainty inference has become an important task to improve the classification accuracy for artificial intelligence systems. For image classification tasks, we propose a structured DropConnect (SDC) framework to model the output of a deep neural network by a Dirichlet distribution. We introduce a DropConnect strategy on weights in the fully connected layers during training. In test, we split the network into several sub-networks, and then model the Dirichlet distribution by match its moments with the mean and variance of the outputs of these sub-networks. The entropy of the estimated Dirichlet distribution is finally utilized for uncertainty inference. In this paper, this framework is implemented on LeNet$5$ and VGG$16$ models for misclassification detection and out-of-distribution detection on MNIST and CIFAR-$10$ datasets. Experimental results show that the performance of the proposed SDC can be comparable to other uncertainty inference methods. Furthermore, the SDC is adapted well to different network structures with certain generalization capabilities and research prospects.
DF^2AM: Dual-level Feature Fusion and Affinity Modeling for RGB-Infrared Cross-modality Person Re-identification
Apr 01, 2021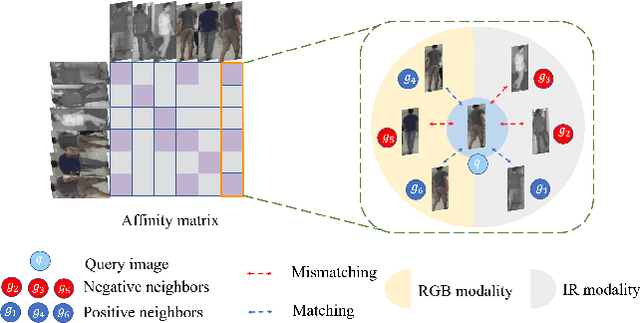
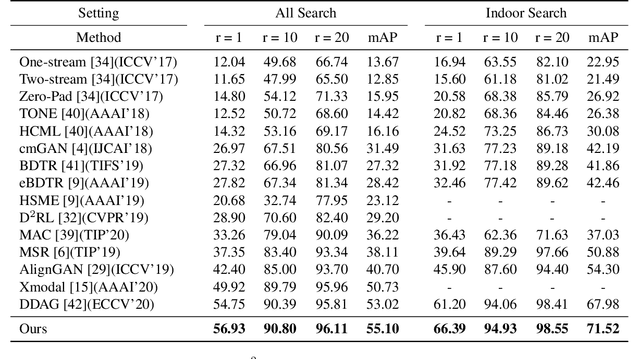
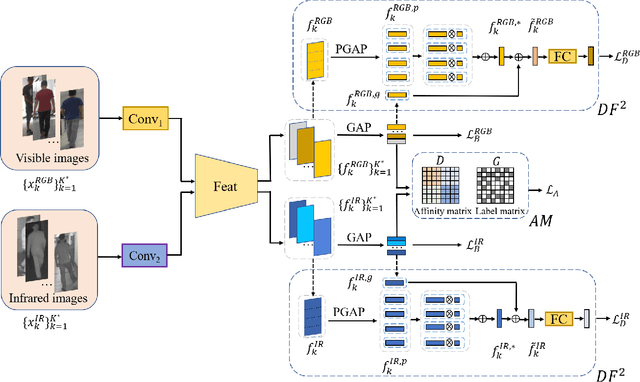
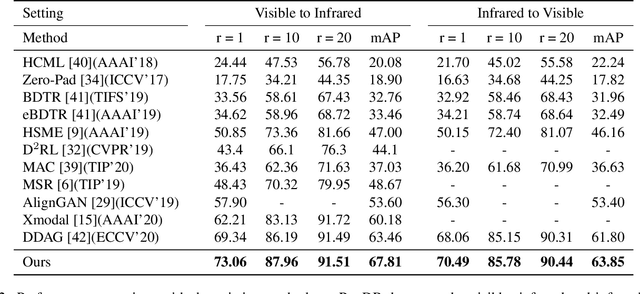
RGB-infrared person re-identification is a challenging task due to the intra-class variations and cross-modality discrepancy. Existing works mainly focus on learning modality-shared global representations by aligning image styles or feature distributions across modalities, while local feature from body part and relationships between person images are largely neglected. In this paper, we propose a Dual-level (i.e., local and global) Feature Fusion (DF^2) module by learning attention for discriminative feature from local to global manner. In particular, the attention for a local feature is determined locally, i.e., applying a learned transformation function on itself. Meanwhile, to further mining the relationships between global features from person images, we propose an Affinities Modeling (AM) module to obtain the optimal intra- and inter-modality image matching. Specifically, AM employes intra-class compactness and inter-class separability in the sample similarities as supervised information to model the affinities between intra- and inter-modality samples. Experimental results show that our proposed method outperforms state-of-the-arts by large margins on two widely used cross-modality re-ID datasets SYSU-MM01 and RegDB, respectively.
Unsupervised Person Re-identification via Simultaneous Clustering and Consistency Learning
Apr 01, 2021
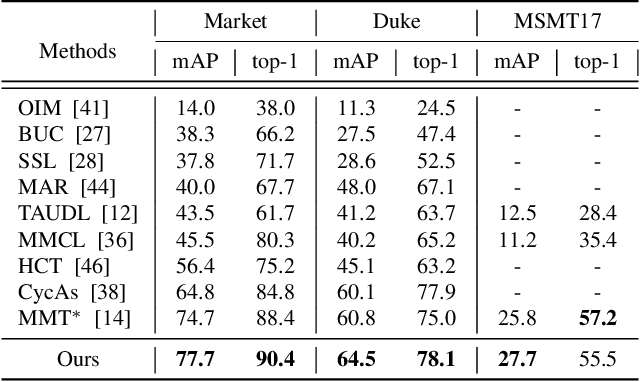
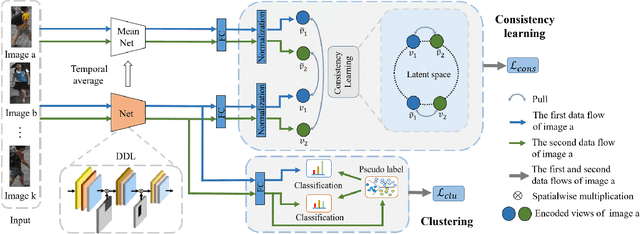
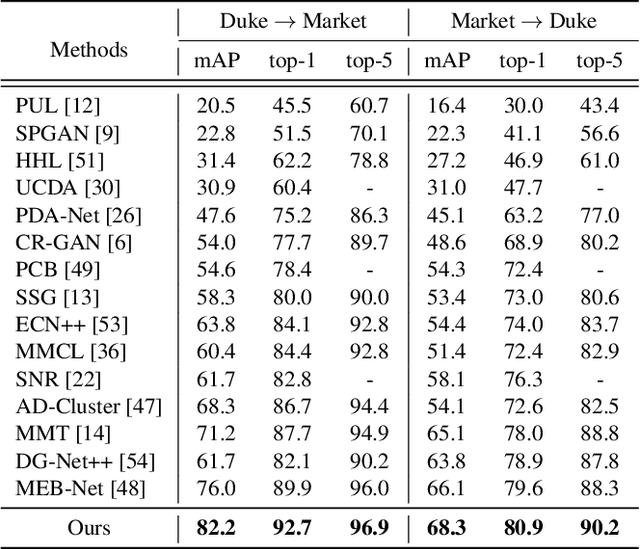
Unsupervised person re-identification (re-ID) has become an important topic due to its potential to resolve the scalability problem of supervised re-ID models. However, existing methods simply utilize pseudo labels from clustering for supervision and thus have not yet fully explored the semantic information in data itself, which limits representation capabilities of learned models. To address this problem, we design a pretext task for unsupervised re-ID by learning visual consistency from still images and temporal consistency during training process, such that the clustering network can separate the images into semantic clusters automatically. Specifically, the pretext task learns semantically meaningful representations by maximizing the agreement between two encoded views of the same image via a consistency loss in latent space. Meanwhile, we optimize the model by grouping the two encoded views into same cluster, thus enhancing the visual consistency between views. Experiments on Market-1501, DukeMTMC-reID and MSMT17 datasets demonstrate that our proposed approach outperforms the state-of-the-art methods by large margins.
Grad-CAM guided channel-spatial attention module for fine-grained visual classification
Jan 24, 2021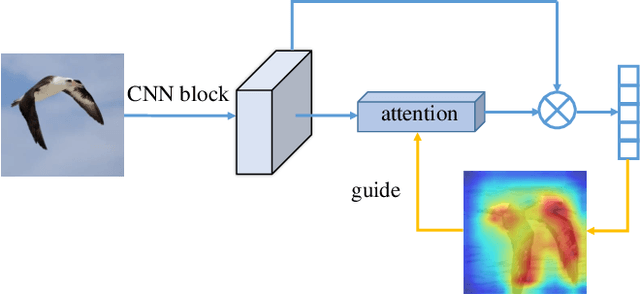
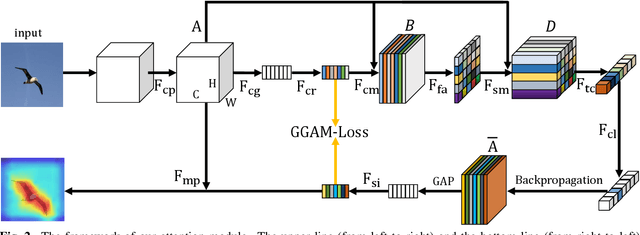
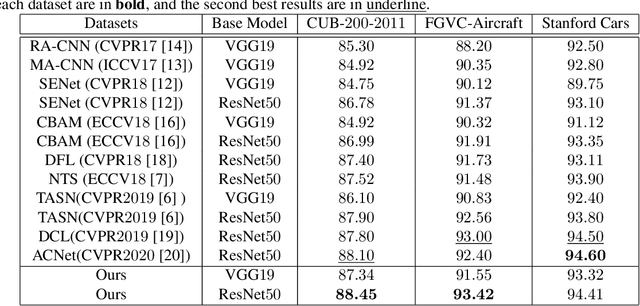
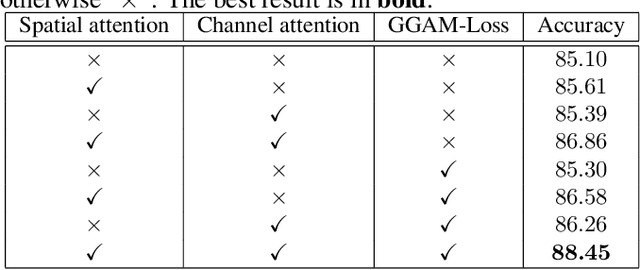
Fine-grained visual classification (FGVC) is becoming an important research field, due to its wide applications and the rapid development of computer vision technologies. The current state-of-the-art (SOTA) methods in the FGVC usually employ attention mechanisms to first capture the semantic parts and then discover their subtle differences between distinct classes. The channel-spatial attention mechanisms, which focus on the discriminative channels and regions simultaneously, have significantly improved the classification performance. However, the existing attention modules are poorly guided since part-based detectors in the FGVC depend on the network learning ability without the supervision of part annotations. As obtaining such part annotations is labor-intensive, some visual localization and explanation methods, such as gradient-weighted class activation mapping (Grad-CAM), can be utilized for supervising the attention mechanism. We propose a Grad-CAM guided channel-spatial attention module for the FGVC, which employs the Grad-CAM to supervise and constrain the attention weights by generating the coarse localization maps. To demonstrate the effectiveness of the proposed method, we conduct comprehensive experiments on three popular FGVC datasets, including CUB-$200$-$2011$, Stanford Cars, and FGVC-Aircraft datasets. The proposed method outperforms the SOTA attention modules in the FGVC task. In addition, visualizations of feature maps also demonstrate the superiority of the proposed method against the SOTA approaches.
DS-UI: Dual-Supervised Mixture of Gaussian Mixture Models for Uncertainty Inference
Nov 17, 2020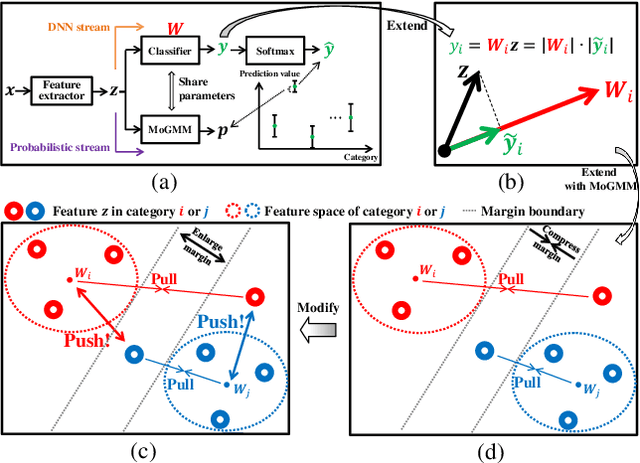
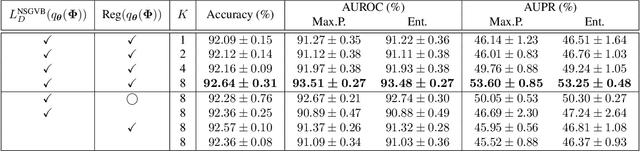
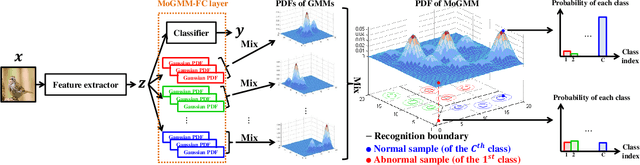
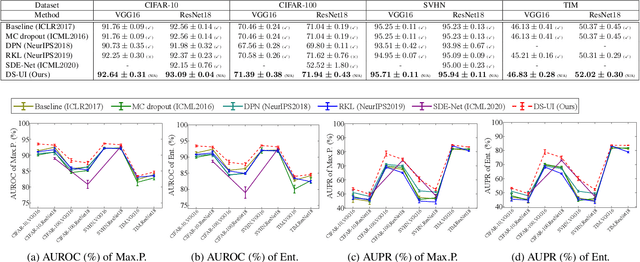
This paper proposes a dual-supervised uncertainty inference (DS-UI) framework for improving Bayesian estimation-based uncertainty inference (UI) in deep neural network (DNN)-based image recognition. In the DS-UI, we combine the classifier of a DNN, i.e., the last fully-connected (FC) layer, with a mixture of Gaussian mixture models (MoGMM) to obtain an MoGMM-FC layer. Unlike existing UI methods for DNNs, which only calculate the means or modes of the DNN outputs' distributions, the proposed MoGMM-FC layer acts as a probabilistic interpreter for the features that are inputs of the classifier to directly calculate the probability density of them for the DS-UI. In addition, we propose a dual-supervised stochastic gradient-based variational Bayes (DS-SGVB) algorithm for the MoGMM-FC layer optimization. Unlike conventional SGVB and optimization algorithms in other UI methods, the DS-SGVB not only models the samples in the specific class for each Gaussian mixture model (GMM) in the MoGMM, but also considers the negative samples from other classes for the GMM to reduce the intra-class distances and enlarge the inter-class margins simultaneously for enhancing the learning ability of the MoGMM-FC layer in the DS-UI. Experimental results show the DS-UI outperforms the state-of-the-art UI methods in misclassification detection. We further evaluate the DS-UI in open-set out-of-domain/-distribution detection and find statistically significant improvements. Visualizations of the feature spaces demonstrate the superiority of the DS-UI.
Advanced Dropout: A Model-free Methodology for Bayesian Dropout Optimization
Oct 11, 2020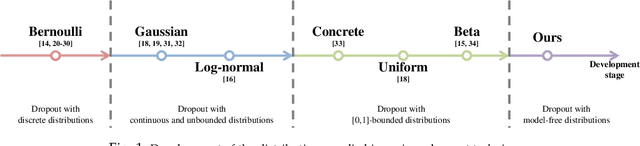
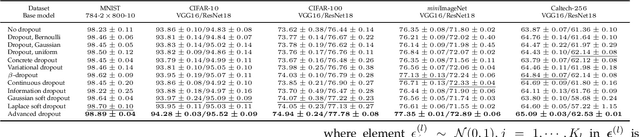
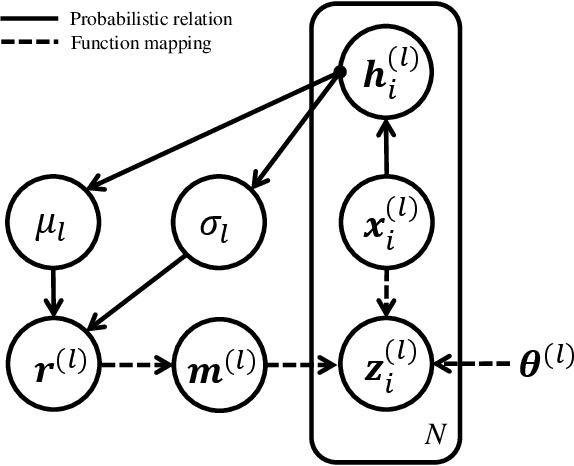

Due to lack of data, overfitting ubiquitously exists in real-world applications of deep neural networks (DNNs). In this paper, we propose advanced dropout, a model-free methodology, to mitigate overfitting and improve the performance of DNNs. The advanced dropout technique applies a model-free and easily implemented distribution with a parametric prior, and adaptively adjusts dropout rate. Specifically, the distribution parameters are optimized by stochastic gradient variational Bayes (SGVB) inference in order to carry out an end-to-end training of DNNs. We evaluate the effectiveness of the advanced dropout against nine dropout techniques on five widely used datasets in computer vision. The advanced dropout outperforms all the referred techniques by 0.83% on average for all the datasets. An ablation study is conducted to analyze the effectiveness of each component. Meanwhile, convergence of dropout rate and ability to prevent overfitting are discussed in terms of classification performance. Moreover, we extend the application of the advanced dropout to uncertainty inference and network pruning, and we find that the advanced dropout is superior to the corresponding referred methods. The advanced dropout improves classification accuracies by 4% in uncertainty inference and by 0.2% and 0.5% when pruning more than 90% of nodes and 99.8% of parameters, respectively.