 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-layer Navigation Convolutional Neural Network for Fine-grained Visual Classification
Jun 21, 2021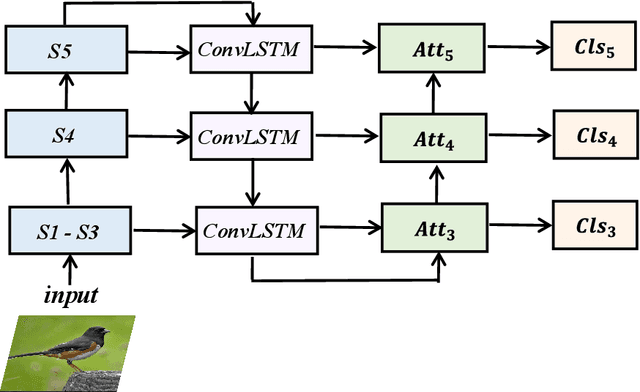
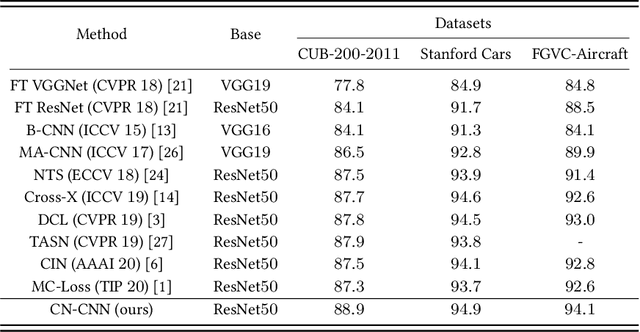
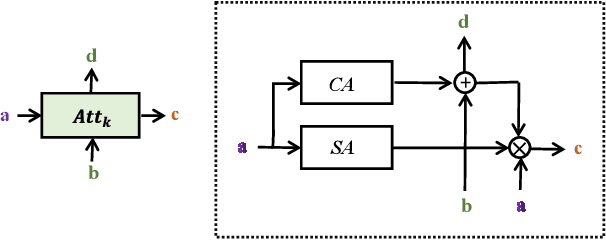

Fine-grained visual classification (FGVC) aims to classify sub-classes of objects in the same super-class (e.g., species of birds, models of cars). For the FGVC tasks, the essential solution is to find discriminative subtle information of the target from local regions. TraditionalFGVC models preferred to use the refined features,i.e., high-level semantic information for recognition and rarely use low-level in-formation. However, it turns out that low-level information which contains rich detail information also has effect on improving performance. Therefore, in this paper, we propose cross-layer navigation convolutional neural network for feature fusion. First, the feature maps extracted by the backbone network are fed into a convolutional long short-term memory model sequentially from high-level to low-level to perform feature aggregation. Then, attention mechanisms are used after feature fusion to extract spatial and channel information while linking the high-level semantic information and the low-level texture features, which can better locate the discriminative regions for the FGVC. In the experiments, three commonly used FGVC datasets, including CUB-200-2011, Stanford-Cars, andFGVC-Aircraft datasets, are used for evaluation and we demonstrate the superiority of the proposed method by comparing it with other referred FGVC methods to show that this method achieves superior results.