 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecycling Failures: Salvaging Exploration in RLVR via Fine-Grained Off-Policy Guidance
Feb 27, 2026Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as a powerful paradigm for enhancing the complex reasoning capabilities of Large Reasoning Models. However, standard outcome-based supervision suffers from a critical limitation that penalizes trajectories that are largely correct but fail due to several missteps as heavily as completely erroneous ones. This coarse feedback signal causes the model to discard valuable largely correct rollouts, leading to a degradation in rollout diversity that prematurely narrows the exploration space. Process Reward Models have demonstrated efficacy in providing reliable step-wise verification for test-time scaling, naively integrating these signals into RLVR as dense rewards proves ineffective.Prior methods attempt to introduce off-policy guided whole-trajectory replacement that often outside the policy model's distribution, but still fail to utilize the largely correct rollouts generated by the model itself and thus do not effectively mitigate the narrowing of the exploration space. To address these issues, we propose SCOPE (Step-wise Correction for On-Policy Exploration), a novel framework that utilizes Process Reward Models to pinpoint the first erroneous step in suboptimal rollouts and applies fine-grained, step-wise off-policy rectification. By applying precise refinement on partially correct rollout, our method effectively salvages partially correct trajectories and increases diversity score by 13.5%, thereby sustaining a broad exploration space. Extensive experiments demonstrate that our approach establishes new state-of-the-art results, achieving an average accuracy of 46.6% on math reasoning and exhibiting robust generalization with 53.4% accuracy on out-of-distribution reasoning tasks.
Remodeling Semantic Relationships in Vision-Language Fine-Tuning
Nov 13, 2025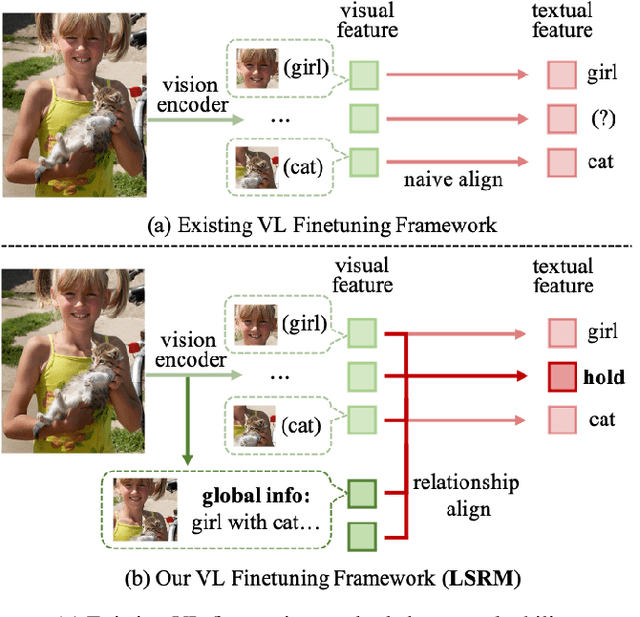

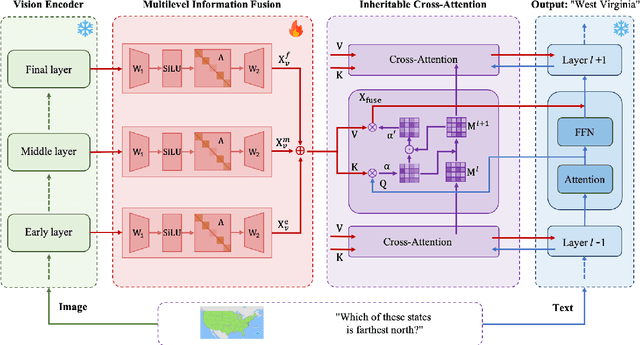

Vision-language fine-tuning has emerged as an efficient paradigm for constructing multimodal foundation models. While textual context often highlights semantic relationships within an image, existing fine-tuning methods typically overlook this information when aligning vision and language, thus leading to suboptimal performance. Toward solving this problem, we propose a method that can improve multimodal alignment and fusion based on both semantics and relationships.Specifically, we first extract multilevel semantic features from different vision encoder to capture more visual cues of the relationships. Then, we learn to project the vision features to group related semantics, among which are more likely to have relationships. Finally, we fuse the visual features with the textual by using inheritable cross-attention, where we globally remove the redundant visual relationships by discarding visual-language feature pairs with low correlation. We evaluate our proposed method on eight foundation models and two downstream tasks, visual question answering and image captioning, and show that it outperforms all existing methods.
Re-Initialization Token Learning for Tool-Augmented Large Language Models
Jun 17, 2025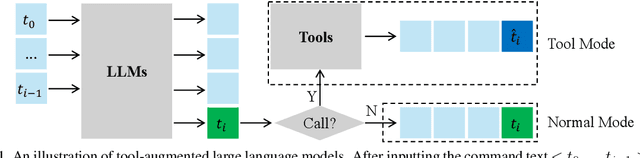
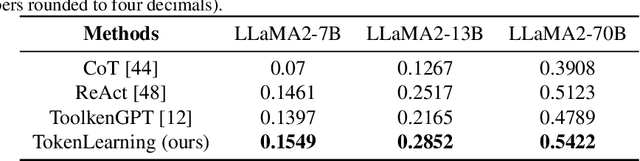
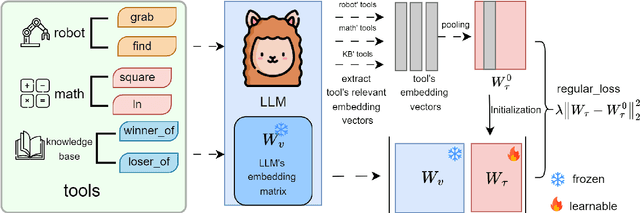
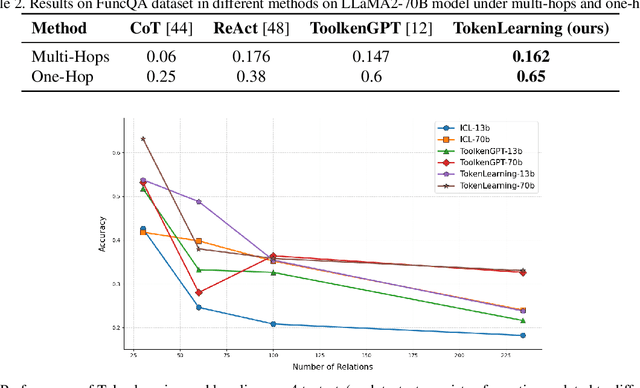
Large language models have demonstrated exceptional performance, yet struggle with complex tasks such as numerical reasoning, plan generation. Integrating external tools, such as calculators and databases, into large language models (LLMs) is crucial for enhancing problem-solving capabilities. Current methods assign a unique token to each tool, enabling LLMs to call tools through token prediction-similar to word generation. However, this approach fails to account for the relationship between tool and word tokens, limiting adaptability within pre-trained LLMs. To address this issue, we propose a novel token learning method that aligns tool tokens with the existing word embedding space from the perspective of initialization, thereby enhancing model performance. We begin by constructing prior token embeddings for each tool based on the tool's name or description, which are used to initialize and regularize the learnable tool token embeddings. This ensures the learned embeddings are well-aligned with the word token space, improving tool call accuracy. We evaluate the method on tasks such as numerical reasoning, knowledge-based question answering, and embodied plan generation using GSM8K-XL, FuncQA, KAMEL, and VirtualHome datasets. The results demonstrate clear improvements over recent baselines, including CoT, REACT, ICL, and ToolkenGPT, indicating that our approach effectively augments LLMs with tools through relevant tokens across diverse domains.
LARGO: Low-Rank Regulated Gradient Projection for Robust Parameter Efficient Fine-Tuning
Jun 14, 2025



The advent of parameter-efficient fine-tuning methods has significantly reduced the computational burden of adapting large-scale pretrained models to diverse downstream tasks. However, existing approaches often struggle to achieve robust performance under domain shifts while maintaining computational efficiency. To address this challenge, we propose Low-rAnk Regulated Gradient Projection (LARGO) algorithm that integrates dynamic constraints into low-rank adaptation methods. Specifically, LARGO incorporates parallel trainable gradient projections to dynamically regulate layer-wise updates, retaining the Out-Of-Distribution robustness of pretrained model while preserving inter-layer independence. Additionally, it ensures computational efficiency by mitigating the influence of gradient dependencies across layers during weight updates. Besides, through leveraging singular value decomposition of pretrained weights for structured initialization, we incorporate an SVD-based initialization strategy that minimizing deviation from pretrained knowledge. Through extensive experiments on diverse benchmarks, LARGO achieves state-of-the-art performance across in-domain and out-of-distribution scenarios, demonstrating improved robustness under domain shifts with significantly lower computational overhead compared to existing PEFT methods. The source code will be released soon.
SIGMA: Refining Large Language Model Reasoning via Sibling-Guided Monte Carlo Augmentation
Jun 06, 2025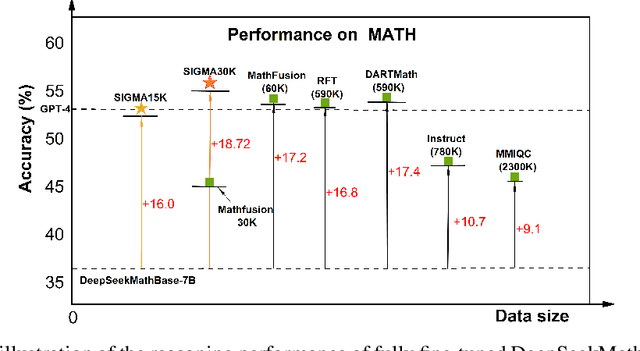



Enhancing large language models by simply scaling up datasets has begun to yield diminishing returns, shifting the spotlight to data quality. Monte Carlo Tree Search (MCTS) has emerged as a powerful technique for generating high-quality chain-of-thought data, yet conventional approaches typically retain only the top-scoring trajectory from the search tree, discarding sibling nodes that often contain valuable partial insights, recurrent error patterns, and alternative reasoning strategies. This unconditional rejection of non-optimal reasoning branches may waste vast amounts of informative data in the whole search tree. We propose SIGMA (Sibling Guided Monte Carlo Augmentation), a novel framework that reintegrates these discarded sibling nodes to refine LLM reasoning. SIGMA forges semantic links among sibling nodes along each search path and applies a two-stage refinement: a critique model identifies overlooked strengths and weaknesses across the sibling set, and a revision model conducts text-based backpropagation to refine the top-scoring trajectory in light of this comparative feedback. By recovering and amplifying the underutilized but valuable signals from non-optimal reasoning branches, SIGMA substantially improves reasoning trajectories. On the challenging MATH benchmark, our SIGMA-tuned 7B model achieves 54.92% accuracy using only 30K samples, outperforming state-of-the-art models trained on 590K samples. This result highlights that our sibling-guided optimization not only significantly reduces data usage but also significantly boosts LLM reasoning.
Generated Contents Enrichment
May 06, 2024



In this paper, we investigate a novel artificial intelligence generation task, termed as generated contents enrichment (GCE). Different from conventional artificial intelligence contents generation task that enriches the given textual description implicitly with limited semantics for generating visually real content, our proposed GCE strives to perform content enrichment explicitly on both the visual and textual domain, from which the enriched contents are visually real, structurally reasonable, and semantically abundant. Towards to solve GCE, we propose a deep end-to-end method that explicitly explores the semantics and inter-semantic relationships during the enrichment. Specifically, we first model the input description as a semantic graph, wherein each node represents an object and each edge corresponds to the inter-object relationship. We then adopt Graph Convolutional Networks on top of the input scene description to predict the enriching objects and their relationships with the input objects. Finally, the enriched graph is fed into an image synthesis model to carry out the visual contents generation. Our experiments conducted on the Visual Genome dataset exhibit promising and visually plausible results.
Unsupervised Person Re-identification via Simultaneous Clustering and Consistency Learning
Apr 01, 2021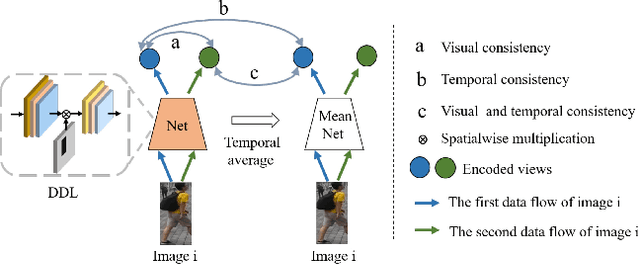
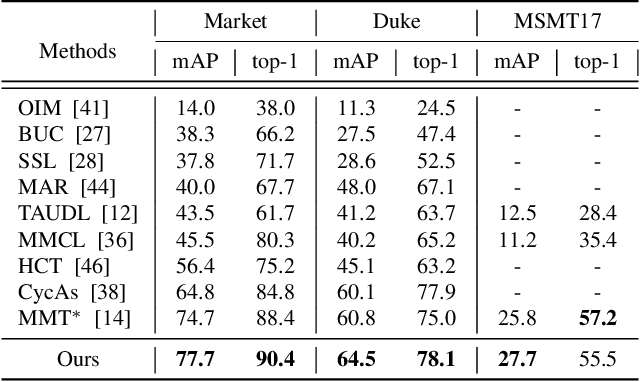
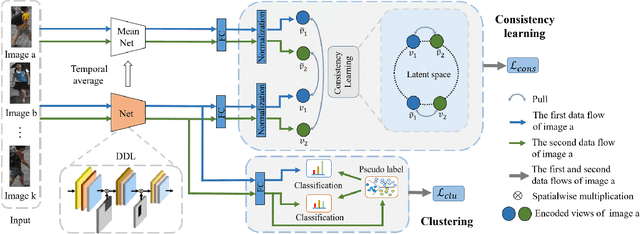
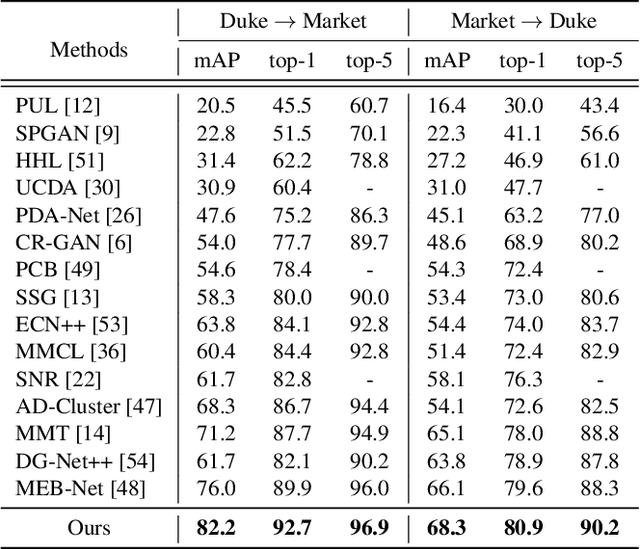
Unsupervised person re-identification (re-ID) has become an important topic due to its potential to resolve the scalability problem of supervised re-ID models. However, existing methods simply utilize pseudo labels from clustering for supervision and thus have not yet fully explored the semantic information in data itself, which limits representation capabilities of learned models. To address this problem, we design a pretext task for unsupervised re-ID by learning visual consistency from still images and temporal consistency during training process, such that the clustering network can separate the images into semantic clusters automatically. Specifically, the pretext task learns semantically meaningful representations by maximizing the agreement between two encoded views of the same image via a consistency loss in latent space. Meanwhile, we optimize the model by grouping the two encoded views into same cluster, thus enhancing the visual consistency between views. Experiments on Market-1501, DukeMTMC-reID and MSMT17 datasets demonstrate that our proposed approach outperforms the state-of-the-art methods by large margins.
Learning Propagation Rules for Attribution Map Generation
Oct 14, 2020


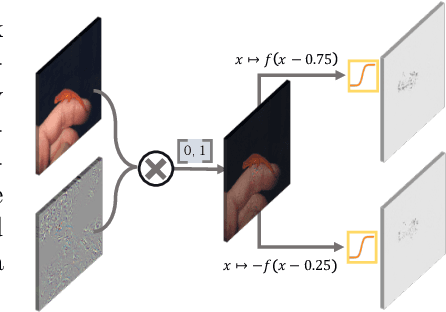
Prior gradient-based attribution-map methods rely on handcrafted propagation rules for the non-linear/activation layers during the backward pass, so as to produce gradients of the input and then the attribution map. Despite the promising results achieved, such methods are sensitive to the non-informative high-frequency components and lack adaptability for various models and samples. In this paper, we propose a dedicated method to generate attribution maps that allow us to learn the propagation rules automatically, overcoming the flaws of the handcrafted ones. Specifically, we introduce a learnable plugin module, which enables adaptive propagation rules for each pixel, to the non-linear layers during the backward pass for mask generating. The masked input image is then fed into the model again to obtain new output that can be used as a guidance when combined with the original one. The introduced learnable module can be trained under any auto-grad framework with higher-order differential support. As demonstrated on five datasets and six network architectures, the proposed method yields state-of-the-art results and gives cleaner and more visually plausible attribution maps.
SSKD: Self-Supervised Knowledge Distillation for Cross Domain Adaptive Person Re-Identification
Sep 13, 2020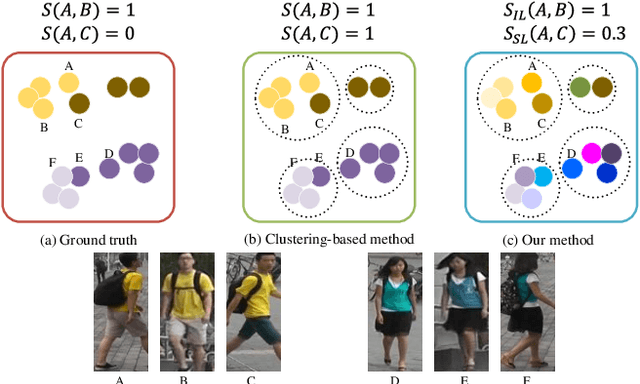
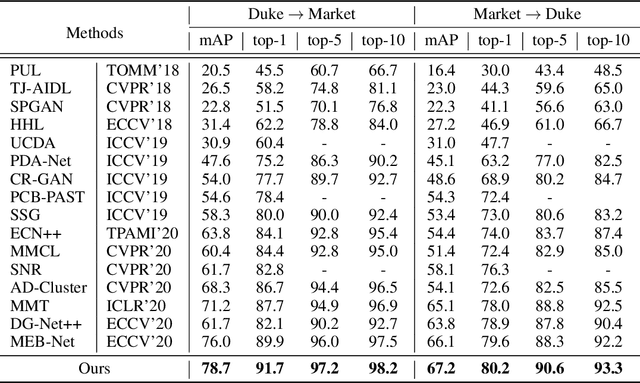
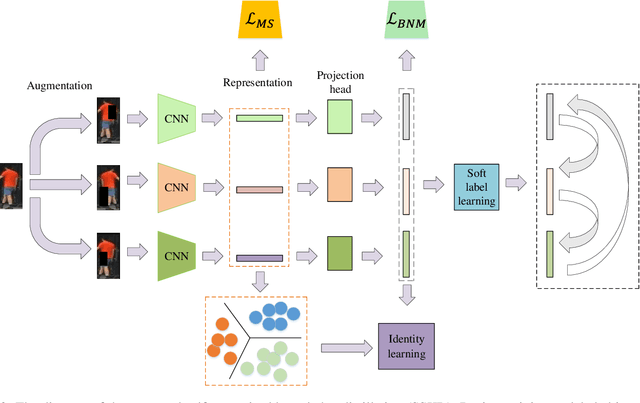
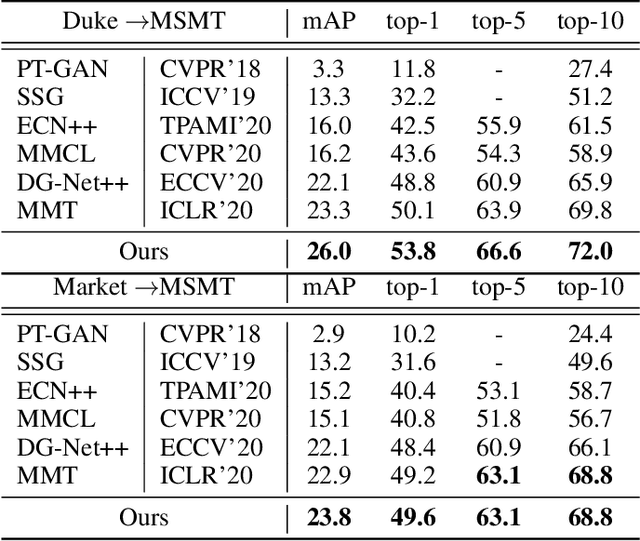
Domain adaptive person re-identification (re-ID) is a challenging task due to the large discrepancy between the source domain and the target domain. To reduce the domain discrepancy, existing methods mainly attempt to generate pseudo labels for unlabeled target images by clustering algorithms. However, clustering methods tend to bring noisy labels and the rich fine-grained details in unlabeled images are not sufficiently exploited. In this paper, we seek to improve the quality of labels by capturing feature representation from multiple augmented views of unlabeled images. To this end, we propose a Self-Supervised Knowledge Distillation (SSKD) technique containing two modules, the identity learning and the soft label learning. Identity learning explores the relationship between unlabeled samples and predicts their one-hot labels by clustering to give exact information for confidently distinguished images. Soft label learning regards labels as a distribution and induces an image to be associated with several related classes for training peer network in a self-supervised manner, where the slowly evolving network is a core to obtain soft labels as a gentle constraint for reliable images. Finally, the two modules can resist label noise for re-ID by enhancing each other and systematically integrating label information from unlabeled images. Extensive experiments on several adaptation tasks demonstrate that the proposed method outperforms the current state-of-the-art approaches by large margins.
Distilling Knowledge from Graph Convolutional Networks
Mar 28, 2020
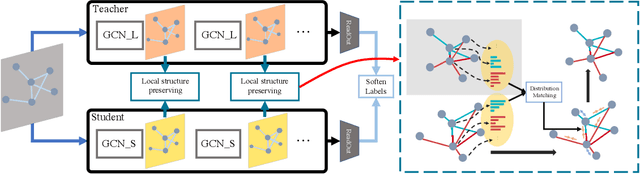
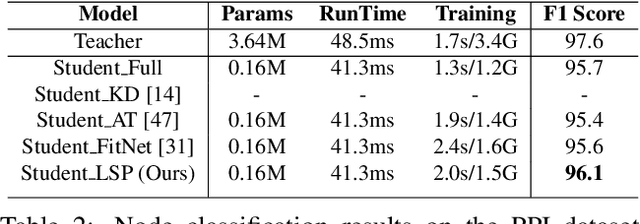
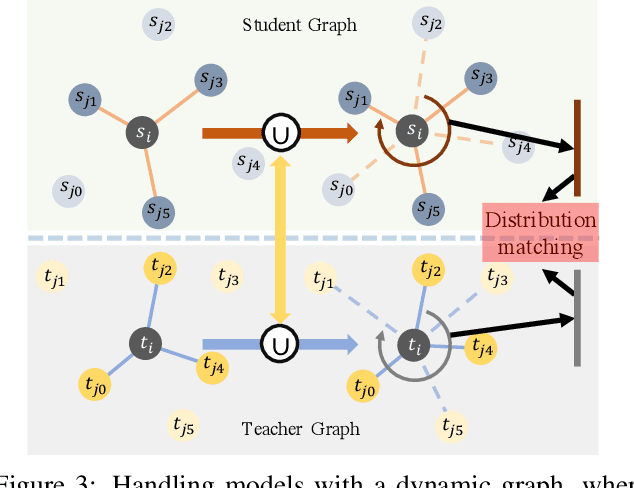
Existing knowledge distillation methods focus on convolutional neural networks~(CNNs), where the input samples like images lie in a grid domain, and have largely overlooked graph convolutional networks~(GCN) that handle non-grid data. In this paper, we propose to our best knowledge the first dedicated approach to {distilling} knowledge from a pre-trained GCN model. To enable the knowledge transfer from the teacher GCN to the student, we propose a local structure preserving module that explicitly accounts for the topological semantics of the teacher. In this module, the local structure information from both the teacher and the student are extracted as distributions, and hence minimizing the distance between these distributions enables topology-aware knowledge transfer from the teacher, yielding a compact yet high-performance student model. Moreover, the proposed approach is readily extendable to dynamic graph models, where the input graphs for the teacher and the student may differ. We evaluate the proposed method on two different datasets using GCN models of different architectures, and demonstrate that our method achieves the state-of-the-art knowledge distillation performance for GCN models.