 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Learning for Text-to-Speech Accent Adaptation
Paper and Code
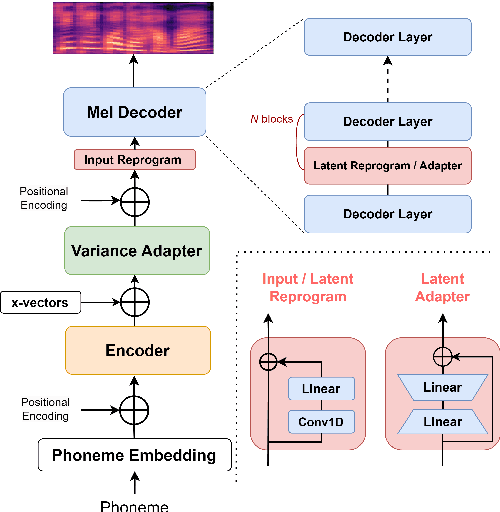
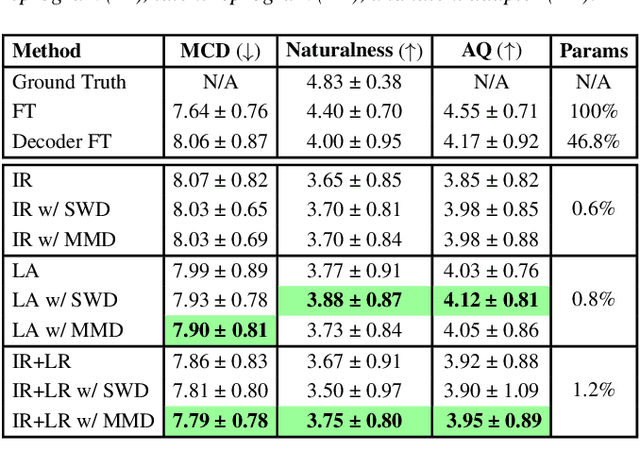
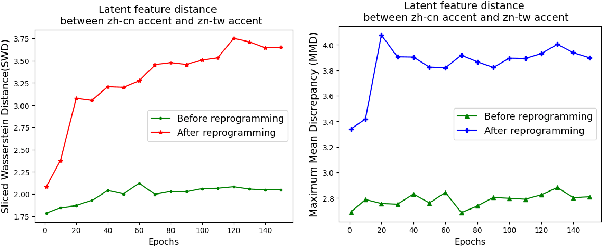
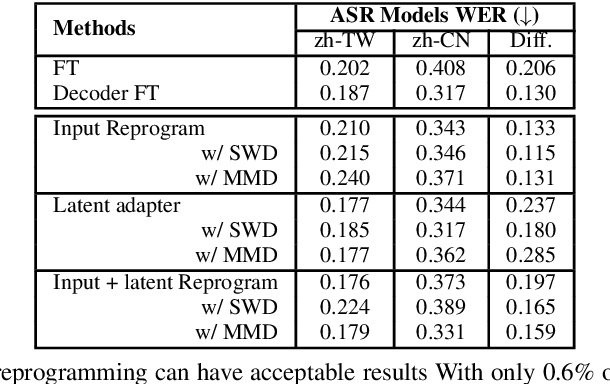
This paper presents a parameter-efficient learning (PEL) to develop a low-resource accent adaptation for text-to-speech (TTS). A resource-efficient adaptation from a frozen pre-trained TTS model is developed by using only 1.2\% to 0.8\% of original trainable parameters to achieve competitive performance in voice synthesis. Motivated by a theoretical foundation of optimal transport (OT), this study carries out PEL for TTS where an auxiliary unsupervised loss based on OT is introduced to maximize a difference between the pre-trained source domain and the (unseen) target domain, in addition to its supervised training loss. Further, we leverage upon this unsupervised loss refinement to boost system performance via either sliced Wasserstein distance or maximum mean discrepancy. The merit of this work is demonstrated by fulfilling PEL solutions based on residual adapter learning, and model reprogramming when evaluating the Mandarin accent adaptation. Experiment results show that the proposed methods can achieve competitive naturalness with parameter-efficient decoder fine-tuning, and the auxiliary unsupervised loss improves model performance empirically.